模型保存与加载常见问题¶
问题:增量训练中,如何保存模型和恢复训练?¶
答复:在增量训练过程中,不仅需要保存模型的参数,也需要保存优化器的参数。
具体地,在1.8版本中需要使用Layer和Optimizer的state_dict和set_dict方法配合fluid.save_dygraph/load_dygraph使用。简要示例如下:
import paddle.fluid as fluid
with fluid.dygraph.guard():
emb = fluid.dygraph.Embedding([10, 10])
state_dict = emb.state_dict()
fluid.save_dygraph(state_dict, "paddle_dy")
adam = fluid.optimizer.Adam( learning_rate = fluid.layers.noam_decay( 100, 10000),
parameter_list = emb.parameters() )
state_dict = adam.state_dict()
fluid.save_dygraph(state_dict, "paddle_dy")
para_state_dict, opti_state_dict = fluid.load_dygraph("paddle_dy")
emb.set_dict(para_state_dict)
adam.set_dict(opti_state_dict)
更多介绍请参考以下API文档:
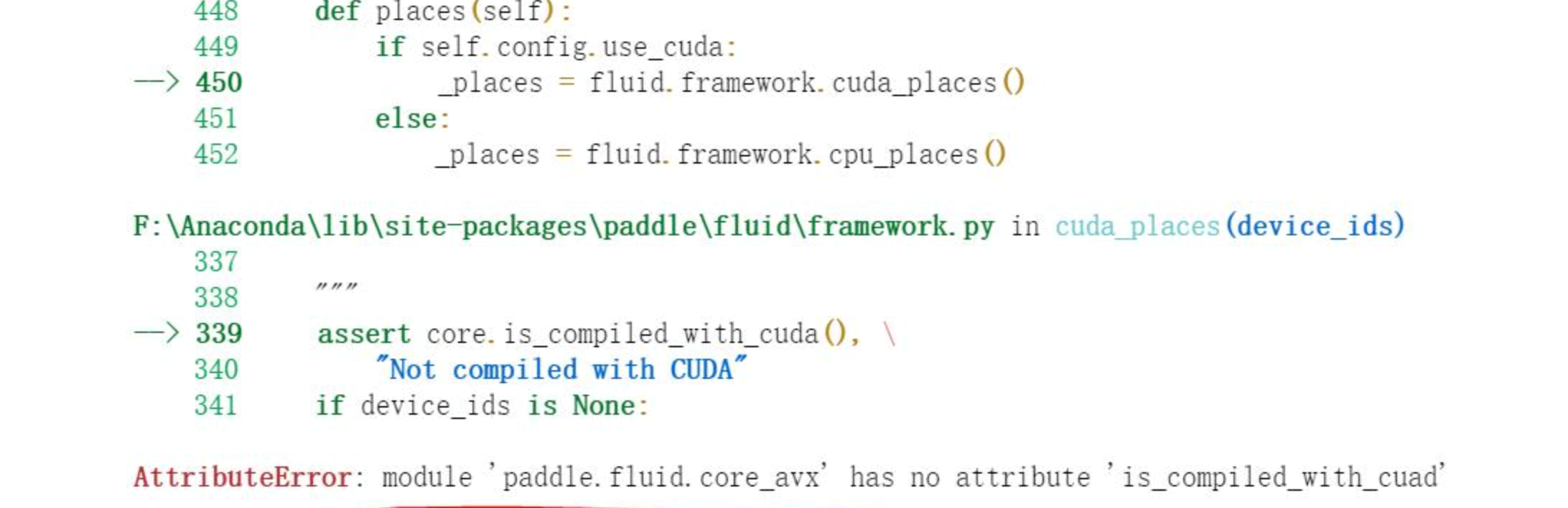
答复:报错是由于没有安装GPU版本的PaddlePaddle,CPU版本默认不包含CUDA检测功能。使用
pip install paddlepaddle-gpu -U即可。
问题:静态图的save接口与save_inference_model接口存储的结果有什么区别?¶
答复:主要差别在于保存结果的应用场景:
save接口(2.0的
paddle.static.save或者1.8的fluid.io.save)该接口用于保存训练过程中的模型和参数,一般包括
*.pdmodel,*.pdparams,*.pdopt三个文件。其中*.pdmodel是训练使用的完整模型program描述,区别于推理模型,训练模型program包含完整的网络,包括前向网络,反向网络和优化器,而推理模型program仅包含前向网络,*.pdparams是训练网络的参数dict,key为变量名,value为Tensor array数值,*.pdopt是训练优化器的参数,结构与*.pdparams一致。save_inference_model接口(2.0的
paddle.static.save_inference_model或者1.8的fluid.io.save_inference_model)该接口用于保存推理模型和参数,2.0的
paddle.static.save_inference_model保存结果为*.pdmodel和*.pdiparams两个文件,其中*.pdmodel为推理使用的模型program描述,*.pdiparams为推理用的参数,这里存储格式与*.pdparams不同(注意两者后缀差个i),*.pdiparams为二进制Tensor存储格式,不含变量名。1.8的fluid.io.save_inference_model默认保存结果为__model__文件,和以参数名为文件名的多个分散参数文件,格式与2.0一致。关于更多2.0动态图模型保存和加载的介绍可以参考教程:模型存储与载入