对数据文件进行分区
分区是一种优化技术,使 Spark 能够最大程度地提高工作器节点的性能。 在查询中筛选数据时,通过消除不必要的磁盘 IO 可以实现更高的性能提升。
对输出文件进行分区
要将数据帧另存为一组已分区的文件,可在写入数据时使用 partitionBy 方法。
以下示例创建派生的 年份 字段。 然后使用它对数据进行分区。
from pyspark.sql.functions import year, col
# Load source data
df = spark.read.csv('/orders/*.csv', header=True, inferSchema=True)
# Add Year column
dated_df = df.withColumn("Year", year(col("OrderDate")))
# Partition by year
dated_df.write.partitionBy("Year").mode("overwrite").parquet("/data")
分区数据帧时生成的文件夹名称包括 column=value 格式的分区列名称和值,如下所示:
表示已分区文件文件夹结构的 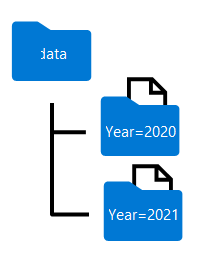
注释
可按多个列对数据进行分区,这会为每个分区键生成一个文件夹层次结构。 例如,可以按年份和月份对示例中的顺序进行分区,以便文件夹层次结构包含每个年份值的文件夹,而该文件夹又包含每个月值的子文件夹。
在查询中筛选 Parquet 文件
当你将数据从 parquet 文件读取到 DataFrame 时,可以从分层文件夹中的任意文件夹中提取数据。 此筛选过程是通过对分区字段使用显式值和通配符来完成的。
在下列示例中,以下代码将提取 2020 年生成的销售订单。
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020')
display(orders_2020.limit(5))
注释
生成的数据帧会省略文件路径中指定的分区列。 示例查询生成的结果不包括 Year 列 - 所有行都将来自 2020 年。