重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
了解如何使用 Spark 和 Hive Tools for Visual Studio Code 创建和提交 Apache Spark 的 PySpark 脚本,首先介绍如何在 Visual Studio Code 中安装 Spark 和 Hive 工具,然后逐步介绍如何将作业提交到 Spark。
Spark 和 Hive 工具可以安装在 Visual Studio Code 支持的平台上,其中包括 Windows、Linux 和 macOS。 下面将找到不同平台的先决条件。
先决条件
完成本文中的步骤需要以下各项:
- SQL Server 大数据群集。 请参阅 SQL Server 大数据群集。
- Visual Studio Code。
- Visual Studio Code 上的 Python 和 Python 扩展。
- Mono。 仅 Linux 和 macOS 需要 Mono。
- 为 Visual Studio Code 设置 PySpark 交互式环境。
- 名为 SQLBDCexample 的本地目录。 本文使用 C:\SQLBDC\SQLBDCexample。
安装 Spark & Hive Tools
完成先决条件后,可以安装适用于 Visual Studio Code 的 Spark 和 Hive 工具。 完成以下步骤以安装 Spark 和 Hive 工具:
打开 Visual Studio Code。
从菜单栏中,导航到查看>扩展。
在搜索框中,输入“Spark & Hive”。
从搜索结果中选择Microsoft发布的 Spark 和 Hive 工具,然后选择“ 安装”。

根据需要重新加载。
打开工作文件夹
完成以下步骤以打开工作文件夹,并在 Visual Studio Code 中创建文件:
从菜单栏中导航到 “文件>打开文件夹...”>C:\SQLBDC\SQLBDCexample,然后选择 “选择文件夹 ”按钮。 该文件夹显示在左侧的“资源管理器”视图中。
在 资源管理器 视图中,选择文件夹 SQLBDCexample,然后选择工作文件夹旁边的 “新建文件” 图标。

使用 (Spark 脚本) 文件扩展名命名新文件
.py。 此示例使用 HelloWorld.py。将以下代码复制并粘贴到脚本文件中:
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
链接 SQL Server 大数据群集
需要链接 SQL Server 大数据群集,然后才能从 Visual Studio Code 将脚本提交到群集。
从菜单栏中导航到 “查看>命令面板...”,然后输入 Spark/Hive:链接群集。

选择链接的群集类型 SQL Server 大数据。
输入 SQL Server 大数据终结点。
输入 SQL Server 大数据群集用户名。
输入用户管理员的密码。
设置大数据群集的显示名称(可选)。
列出群集,查看 输出 视图进行验证。
列出群集
从菜单栏中导航到 “查看>命令面板...”,然后输入 Spark/Hive:列出集群。
检查“输出”视图。 该视图将显示您链接的一个或多个群集。

设置默认群集
如果已关闭,请打开之前创建的 SQLBDCexample 文件夹 Re-Open。
选择之前创建的文件 HelloWorld.py,它将在脚本编辑器中打开。
链接群集(如果尚未这样做)。
右键单击脚本编辑器,然后选择 “Spark/Hive:设置默认群集”。
选择一个群集作为当前脚本文件的默认群集。 这些工具自动更新配置文件.VSCode\settings.json。
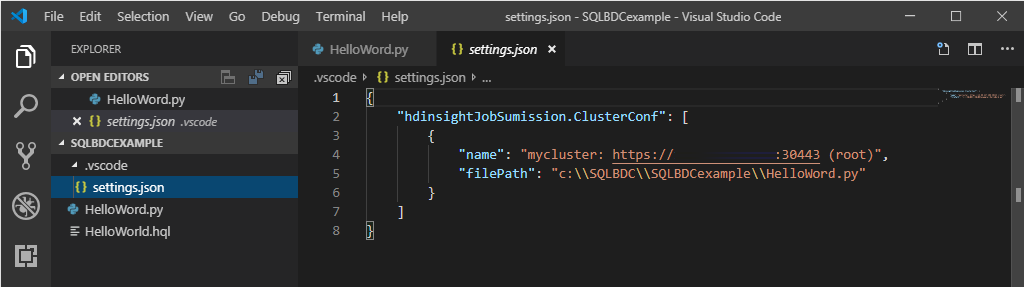
提交交互式 PySpark 查询
可以按照以下步骤提交交互式 PySpark 查询:
如果关闭,请重新打开之前创建的文件夹 SQLBDCexample。
选择之前创建的文件 HelloWorld.py,它将在脚本编辑器中打开。
链接群集(如果尚未这样做)。
选择所有代码并右键单击脚本编辑器,选择 Spark:PySpark Interactive 以提交查询,或使用快捷方式 Ctrl + Alt + I。

如果尚未指定默认群集,请选择群集。 片刻之后, Python 交互式 结果会显示在新选项卡中。这些工具还允许你使用上下文菜单提交代码块而不是整个脚本文件。
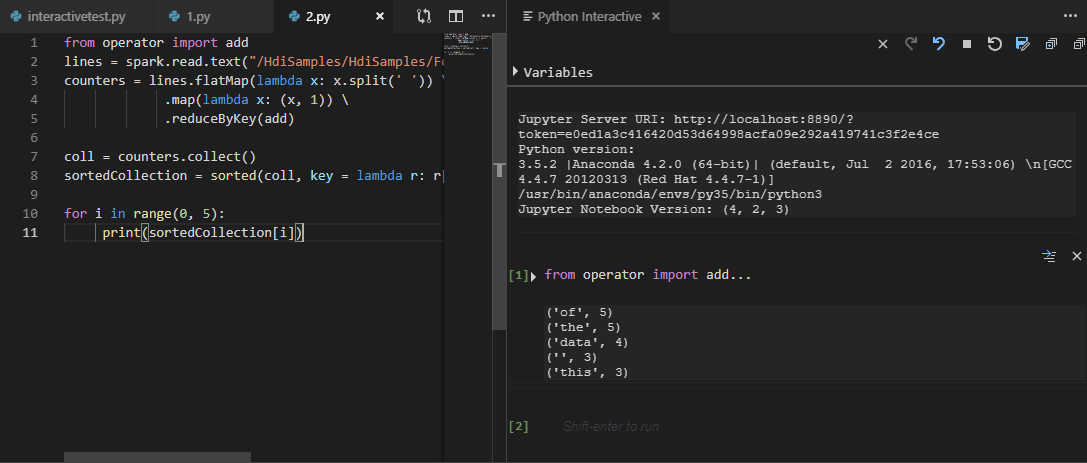
输入 “%%info”,然后按 Shift + Enter 查看作业信息。 (可选)

注释
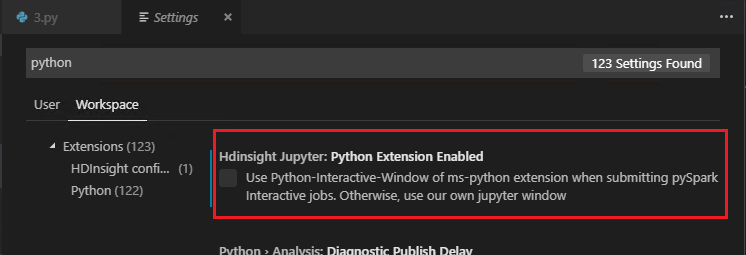
在设置中取消选中 “启用 Python 扩展 ”时(已选中默认设置),提交的 pyspark 交互结果将使用旧窗口。
提交 PySpark 批处理作业
如果关闭,请重新打开之前创建的文件夹 SQLBDCexample。
选择之前创建的文件 HelloWorld.py,它将在脚本编辑器中打开。
链接群集(如果尚未这样做)。
右键单击脚本编辑器,然后选择 Spark:PySpark Batch,或使用快捷 键 Ctrl + Alt + H。
如果尚未指定默认群集,请选择群集。 提交 Python 作业后,提交日志将显示在 Visual Studio Code 的“输出”窗口中。 Spark UI URL 和 Yarn UI URL 也同时显示。 你可以在 Web 浏览器中打开 URL 以跟踪作业状态。

Apache Livy 配置
Apache Livy 配置是支持的,可以在工作区文件夹中的 .VSCode\settings.js 处设置。 目前,Livy 配置仅支持 Python 脚本。 有关详细信息,请参阅 Livy 自述文件。
如何激活 Livy 配置
方法 1
- 从菜单栏中,导航到“文件”“首选项”>“设置” 。
- 在 “搜索设置” 文本框中,输入 HDInsight 作业提交:Livy Conf。
- 选择“在 settings.json 中编辑”以获取相关搜索结果。
方法 2
提交文件,请注意,该 .vscode 文件夹会自动添加到工作文件夹中。 您可以通过选择 settings.json 下的 .vscode 来查找 Livy 配置。
项目设置:

注释
对于设置 driverMemory 和 executorMemory,请使用单位设置值,例如 1gb 或 1024mb。
支持的 Livy 配置
POST /batches
请求正文
| 姓名 | 描述 | 类型 |
|---|---|---|
| 文件 | 包含要执行的应用程序的文件 | 路径(必需) |
| 代理用户 | 运行作业时要模拟的用户 | 字符串 |
| 类名 | 应用程序 Java/Spark 主类 | 字符串 |
| args | 应用程序的命令行参数 | 字符串列表 |
| 罐子 | 要在此会话中使用的 jar | 字符串列表 |
| py文件 | 将在本次会话中使用的 Python 文件 | 字符串列表 |
| 文件 | 要在此会话中使用的文件 | 字符串列表 |
| 驱动程序内存 | 用于驱动程序进程的内存量 | 字符串 |
| driverCores | 用于驱动程序进程的内核数 | 整数 (int) |
| 执行器内存 | 每个执行程序进程使用的内存量 | 字符串 |
| executorCores | 每个执行程序使用的内核数 | 整数 (int) |
| 执行器数量 | 为此会话启动的执行程序数 | 整数 (int) |
| 档案 | 将在本次会话中使用的档案 | 字符串列表 |
| 队列 | 已提交到的 YARN 队列的名称 | 字符串 |
| 姓名 | 此会话的名称 | 字符串 |
| 会议 | Spark 配置属性 | key=val 映射 |
| :- | :- | :- |
响应正文
创建的批处理对象。
| 姓名 | 描述 | 类型 |
|---|---|---|
| id | 会话 ID | 整数 (int) |
| 应用程序ID | 此会话的应用程序 ID | 字符串 |
| appInfo | 详细的应用程序信息 | key=val 映射 |
| 日志 | 日志行 | 字符串列表 |
| 州 | 批处理状态 | 字符串 |
| :- | :- | :- |
注释
提交脚本时,分配的 Livy 配置将显示在输出窗格中。
其他功能
Spark 和 Hive for Visual Studio Code 支持以下功能:
IntelliSense 自动完成。 建议会在关键字、方法、变量等处弹出。 不同的图标表示不同类型的对象。

IntelliSense 错误标记。 语言服务会为 Hive 脚本中的编辑错误添加下划线。
语法突出显示。 语言服务使用不同的颜色来区分变量、关键字、数据类型、函数等。

取消链接群集
从菜单栏中导航到 “查看>命令面板...”,然后输入 Spark/Hive:取消链接群集。
选择要取消链接的群集。
查看“输出”视图以进行验证。
后续步骤
有关 SQL Server 大数据群集和相关方案的详细信息,请参阅 SQL Server 大数据群集。