Broker 资源是定义 MQTT 代理的总体设置的主要资源。 它还确定运行 Broker 配置的 Pod 的数量和类型,例如前端和后端。 还可以使用 Broker 资源配置其内存配置文件。 自我修复机制内置于代理中,它通常可以从组件故障中自动恢复。 例如,当配置了高可用性的 Kubernetes 群集中的节点失败时。
可以通过添加更多前端副本和后端分区来水平缩放 MQTT 代理。 前端副本负责接受来自客户端的 MQTT 连接并将其转发到后端分区。 后端分区负责存储消息并将消息传送到客户端。 前端 Pod 会跨后端 Pod 分配消息流量。 后端冗余系数决定了数据副本的数量,从而针对集群中的节点故障提供复原能力。
有关可用设置的列表,请参阅代理 API 参考。
配置缩放设置
重要
此设置要求修改 Broker 资源。 它仅在初始部署时使用 Azure CLI 或 Azure 门户进行配置。 如果需要 Broker 配置更改,则需要新的部署。 若要了解详细信息,请参阅自定义默认代理。
若要配置 MQTT 代理的缩放设置,需要在 Azure IoT 操作部署期间在 Broker 资源的规格中指定基数字段。
自动部署基数
若要在部署期间自动确定初始基数,请省略代理资源中的基数字段。
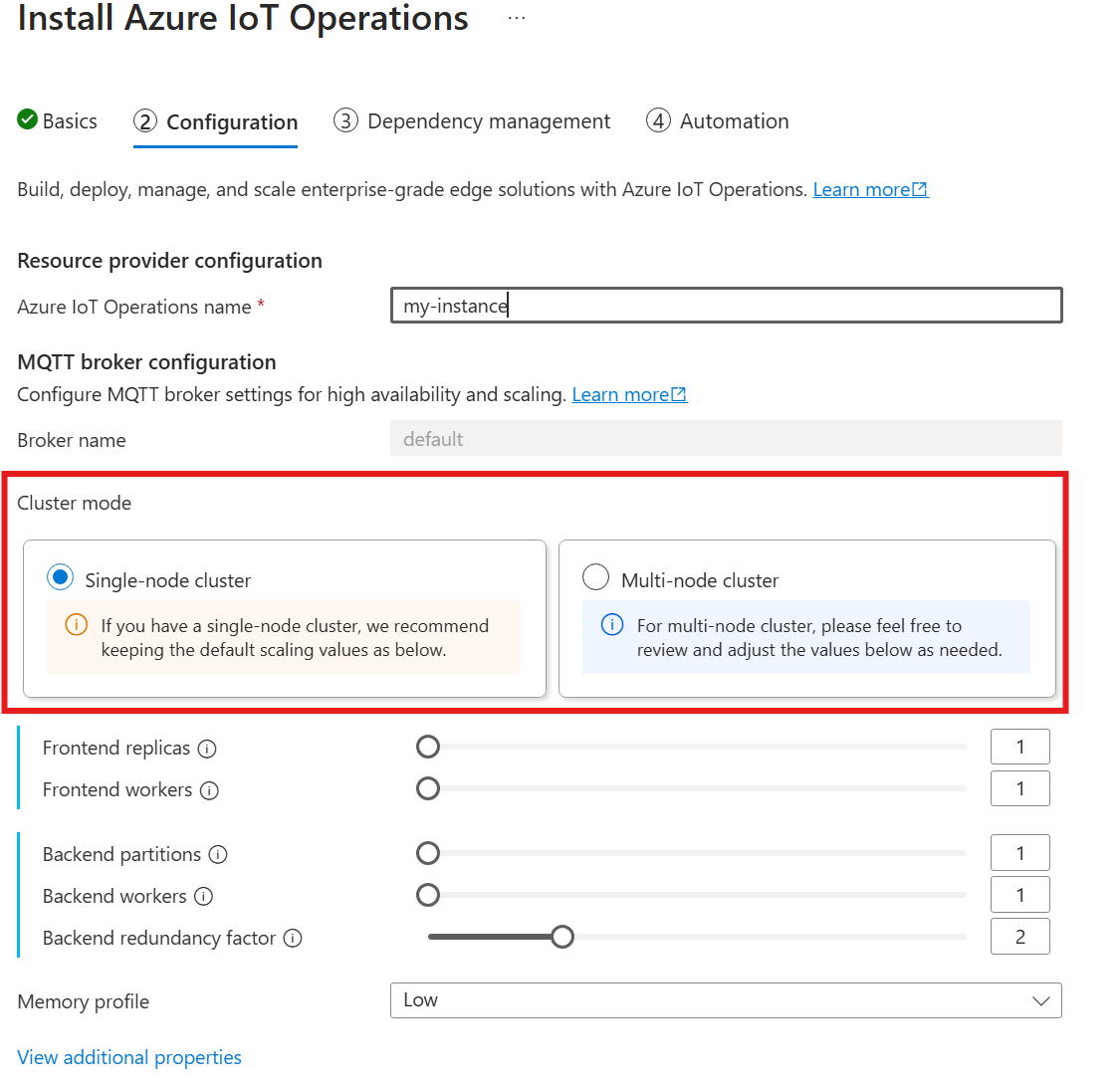
通过 Azure 门户部署 Azure IoT 操作时,尚不支持自动基数。 可以手动将群集部署模式指定为“单节点”或“多节点”。 若要了解详细信息,请参阅部署 Azure IoT 操作。
MQTT 代理运营商将根据部署时可用的节点数自动部署适当的 Pod 数。 此功能对于不需要高可用性或缩放的非生产场景非常有用。
此功能不是自动缩放。 运营商不会根据负载自动缩放 Pod 数。 操作员将仅根据群集硬件确定要部署的初始 Pod 数。 如前所述,基数仅在初始部署时设置。 如果需要更改基数设置,则需要新的部署。
直接配置基数
若要直接配置基数设置,请指定每一个基数字段。

了解基数
基数表示一个集中特定实体的实例数。 在 MQTT 代理的上下文中,基数是指要部署的前端副本、后端分区和后端工作线程的数量。 基数设置用于横向缩放代理,并在出现 Pod 或节点故障时提升高可用性。
基数字段为嵌套字段,具有前端和后端链子字段。 每个子字段都有自己的设置。
前端
前端子字段定义前端 Pod 的设置。 两个主要设置包括:
- 副本:要部署的前端副本 (Pod) 数。 增加前端副本的数量可提供高可用性,以防某个前端 Pod 发生故障。
- 工作线程:每个副本的逻辑前端工作线程数。 每个工作线程最多可以使用一个 CPU 核心。
后端链
后端链子字段定义后端分区的设置。 三个主要设置包括:
- 分区::要部署的分区数。 通过一个名为“分片”的过程,每个分区将负责一部分消息(按主题 ID 和会话 ID 划分)。 前端 Pod 会跨分区分配消息流量。 增加分区数会增加代理可以处理的消息数。
- 冗余系数:每个分区要部署的后端副本 (Pod) 数。 提高冗余系数会增加数据副本的数量,从而针对集群中的节点故障提供弹性。
- 工作线程:每个后端副本要部署的工作线程数。 增加每个后端副本的工作线程数会增加后端 Pod 可以处理的消息数。 每个工作线程最多可以使用 2 个 CPU 核心,因此在增加每个副本的工作线程数时要小心,一定不要超过群集中的 CPU 核心数。
注意事项
增加基数值后,代理处理更多连接和消息的能力通常会提高,并且可在发生 Pod 或节点故障时增强高可用性。 这种增加的容量也会导致资源消耗量增加。 因此,在调整基数值时,请考虑内存配置文件设置和代理的 CPU 资源请求。 如果发现前端 CPU 使用率是瓶颈,则增加每个前端副本的工作线程数有助于提高 CPU 核心利用率。 如果后端 CPU 利用率是瓶颈,则增加后端工作线程的数量有助于提高消息吞吐量。
例如,如果群集有 3 个节点,每个节点有 8 个 CPU 核心,请将前端副本数设置为与节点数 (3) 相匹配,并将工作线程数设置为 1。 将后端分区数设置为与节点数 (3) 相匹配,并将后端工作线程数设置为 1。 根据需要设置冗余系数(2 或 3)。 如果发现前端 CPU 利用率是瓶颈,请增加前端工作线程的数量。 请记住,后端和前端工作线程可能会相互以及与其他 Pod 争用 CPU 资源。
配置内存配置文件
内存配置文件指定了资源受限环境的中转站内存使用情况。 可以从具有不同内存使用特征的预定义内存配置文件中进行选择。 内存配置文件设置用于配置前端和后端副本的内存使用情况。 内存概况与基数设置相互作用,以确定代理的总内存使用量。
重要
此设置要求修改 Broker 资源。 它仅在初始部署时使用 Azure CLI 或 Azure 门户进行配置。 如果需要 Broker 配置更改,则需要新的部署。 若要了解详细信息,请参阅自定义默认代理。
若要配置 MQTT 代理的内存配置文件设置,请在 IoT 操作部署期间在 Broker 资源的规格中指定内存配置文件字段。

用于发布消息的内存有预定义的配置文件,各有不同的内存使用特征。 代理可以处理的会话数或订阅数没有限制。 内存配置文件仅控制 PUBLISH 流量的内存使用情况。
小型
在内存资源有限且客户端发布流量较低的情况下,请使用此概况。
使用此配置文件时:
- 每个前端副本的最大内存使用量约为 99 MiB,但实际的最大内存使用量可能更高。
- 每个后端副本的最大内存使用量约为 102 MiB,乘以后端工作线程数,但实际的最大内存使用量可能更高。
- 最大消息大小为 4 MB。
- PUBLISH 数据的传入缓冲区的最大大小约为每个后端工作器 16 MiB。 但是,由于反压控制机制,缓冲区的有效大小可能会减少。当缓冲区达到 75% 容量时,该机制激活,使得缓冲区大小约为 12 MiB。 被拒绝的数据包会收到包含超出配额错误代码的PUBACK响应。
使用此配置文件时的建议:
- 只应使用一个前端。
- 客户端不应发送大型数据包。 应只发送小于 4 MiB 的数据包。
低
当内存资源有限且客户端发布小数据包时,请使用此配置。
使用此配置文件时:
- 每个前端副本的最大内存使用量约为 387 MiB,但实际的最大内存使用量可能更高。
- 每个后端副本的最大内存使用量约为 390 MiB 乘以后端辅助角色数,但实际的最大内存使用量可能更高。
- 最大消息大小为 16 MB。
- PUBLISH 数据的传入缓冲区的最大大小约为每个后端工作人员 64 兆字节。 但是,由于回压机制的存在,有效大小可能会降低。当缓冲区达到 75% 的容量时,这一机制将被激活,导致缓冲区大小约为 48 MiB。 被拒绝的数据包会收到包含超出配额错误代码的PUBACK响应。
使用此配置文件时的建议:
- 应仅使用一两个前端。
- 客户端不应发送大型数据包。 应只发送小于 16 MiB 的数据包。
中
如果需要处理中等数量的客户端消息,请使用此配置文件。
“中等”是默认配置文件。
- 每个前端副本的最大内存使用量约为 1.9 GiB,但实际的最大内存使用量可能更高。
- 每个后端副本的最大内存使用量约为 1.5 GiB 乘以后端辅助角色数,但实际的最大内存使用量可能更高。
- 最大消息大小为 64 MB。
- PUBLISH 数据的传入缓冲区的最大大小约为每个后端工作器 576 MiB。 但是,由于背压机制,有效大小可能会更低。当缓冲区达到 75% 容量时,该机制会激活,此时缓冲区大小约为 432 MiB。 被拒绝的数据包会收到包含超出配额错误代码的PUBACK响应。
高
需要处理大量客户端消息时,请使用此配置文件。
- 每个前端副本的最大内存使用量约为 4.9 GiB,但实际的最大内存使用量可能更高。
- 每个后端副本的最大内存使用量约为 5.8 GiB 乘以后端辅助角色数,但实际的最大内存使用量可能更高。
- 最大消息大小为 256 MB。
- 每个后端工作线程的 PUBLISH 数据的传入缓冲区最大大小约为 2 GiB。 但是,由于背压机制,有效大小可能会更低。当缓冲区达到 75% 容量时,该机制会激活,此时缓冲区大小约为 1.5 GiB。 被拒绝的数据包会收到包含超出配额错误代码的PUBACK响应。
计算总内存使用量
内存配置文件设置指定每个前端和后端副本的内存使用情况,并与基数设置交互。 可以使用公式计算总内存使用量:
M_total = R_fe * M_fe + (P_be * RF_be) * M_be * W_be
地点:
| 变量 | DESCRIPTION |
|---|---|
| M_total | 总内存使用量 |
| R_fe | 前端副本数 |
| M_fe | 每个前端副本的内存使用情况 |
| P_be | 后端分区数 |
| RF_be | 后端冗余因素 |
| M_be | 每个后端副本的内存使用情况 |
| W_be | 每个后端副本的工作线程数 |
例如,如果选择 中等 内存配置文件,则配置文件的前端内存使用率为 1.9 GB,后端内存使用率为 1.5 GB。 假设代理配置为 2 个前端副本、2 个后端分区和后端冗余因子 2。 总内存使用量为:
2 * 1.9 GB + (2 * 2) * 1.5 GB * 2 = 15.8 GB
相比之下, Tiny 内存配置文件的前端内存使用率为 99 MiB,后端内存使用率为 102 MiB。 如果假设具有相同的中转站配置,则总内存使用量为:
2 * 99 MB + (2 * 2) * 102 MB * 2 = 198 MB + 816 MB = 1.014 GB。
重要
当内存为 75% 已满时,MQTT 中转站将开始拒绝消息。
基数和 Kubernetes 资源限制
为了防止群集中的资源不足,代理默认配置为请求 Kubernetes CPU 资源限制。 缩放副本或工作线程的数量会按比例增加所需的 CPU 资源。 如果群集中可用的 CPU 资源不足,则会发生部署错误。 此通知有助于避免请求的代理基数因资源不足而无法以最佳方式运行的情况。 它还有助于避免潜在的 CPU 争用和 Pod 逐出。
MQTT 代理目前为每个前端工作线程请求一 (1.0) CPU 单元,为每个后端工作线程请求两个 (2.0) CPU 单元。 有关详细信息,请参阅 Kubernetes CPU 资源单元。
例如,下面的基数将请求以下 CPU 资源:
- 对于前端:每个前端 Pod 2 个 CPU 单元,总共 6 个 CPU 单元。
- 对于后端:每个后端 Pod 4 个 CPU 单元(针对两个后端工作线程)X 2(冗余系数)X 3(分区数),总共 24 个 CPU 单元。
{
"cardinality": {
"frontend": {
"replicas": 3,
"workers": 2
},
"backendChain": {
"partitions": 3,
"redundancyFactor": 2,
"workers": 2
}
}
}
若要禁用此设置,请在代理资源中将 generateResourceLimits.cpu 字段设置为 Disabled。
多节点部署
为了确保使用多节点部署实现高可用性和复原能力,IoT 操作 MQTT 代理会自动为后端 Pod 设置反相关性规则。
这些规则是预定义的,无法修改。
反相关性规则的用途
反相关性规则可确保来自同一分区的后端 Pod 不会在同一节点上运行。 此功能有助于分布负载并提供针对节点故障的复原能力。 具体而言,来自同一分区的后端 Pod 彼此具有反相关性。
验证反相关性设置
若要验证后端 Pod 的反相关性设置,请使用以下命令:
kubectl get pod aio-broker-backend-1-0 -n azure-iot-operations -o yaml | grep affinity -A 15
输出会显示反相关性配置,如下所示:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: chain-number
operator: In
values:
- "1"
topologyKey: kubernetes.io/hostname
weight: 100
这些规则是为代理设置的唯一反相关性规则。