本文提供了在使用 EventProcessorClient 类型时可能会遇到的常见问题的解决方案。 如果要查找使用 Azure 事件中心时可能会遇到的其他常见问题的解决方案,请参阅 Azure 事件中心疑难解答。
使用事件处理器时,412 个先决条件失败
当客户端尝试获取或续订分区的所有权时,会发生 412 前置条件错误,但所有权记录的本地版本已过时。 当另一个处理器实例窃取分区所有权时,会出现此问题。 有关详细信息,请参阅下一节。
分区所有权经常更改
当实例数发生更改(即添加或删除)时,正在运行的 EventProcessorClient 实例会尝试在它们之间对分区进行负载均衡。 在处理器数量变更后的几分钟内,预计分区会更换所有者。 均衡后,分区所有权应稳定且不经常更改。 如果分区所有权在处理器数不变时频繁更改,则可能表示出现问题。 我们建议你在 GitHub 上提交一个包含日志和重现的问题。
分区所有权是通过 CheckpointStore 中的所有权记录确定的。 在每个负载均衡间隔中, EventProcessorClient 将执行以下任务:
- 提取最新的所有权记录。
- 检查记录以查看哪些记录尚未在分区所有权过期间隔内更新其时间戳。 仅考虑符合此条件的记录。
- 如果存在任何未拥有的分区,并且负载在实例
EventProcessorClient之间不均衡,则事件处理程序客户端将尝试声明分区。 - 更新其拥有的分区的所有权记录,这些分区与该分区有活动链接。
通过 EventProcessorClient 创建 EventProcessorClientBuilder 时,可以配置负载均衡和所有权过期间隔,如下所示:
- loadBalancingUpdateInterval(Duration) 方法指示负载均衡周期的运行频率。
- partitionOwnershipExpirationInterval(Duration) 方法表示自所有权记录更新以来,处理器认为分区无所有权之前的最短时间。
例如,如果所有权记录在上午 9:30 更新,那么 partitionOwnershipExpirationInterval 是 2 分钟。 当负载均衡周期发生时,如果发现所有权记录在过去2分钟内或到了上午9:32时未更新,它将视该分区为未拥有。
如果某个分区使用者中发生错误,它将关闭相应的使用者,但在下一个负载均衡周期之前不会尝试回收它。
“…当前接收器'<RECEIVER_NAME>(纪元为'0')正在断开连接”
整个错误消息类似于以下输出:
New receiver 'nil' with higher epoch of '0' is created hence current receiver 'nil' with epoch '0'
is getting disconnected. If you are recreating the receiver, make sure a higher epoch is used.
TrackingId:<GUID>, SystemTracker:<NAMESPACE>:eventhub:<EVENT_HUB_NAME>|<CONSUMER_GROUP>,
Timestamp:2022-01-01T12:00:00}"}
在添加或删除 EventProcessorClient 个实例后进行负载均衡时,会出现此错误。 负载均衡是一个持续的过程。 当你对使用者使用 BlobCheckpointStore 时,每隔约 30 秒(默认情况下),使用者就会检查哪个使用者对每个分区都有声明,然后运行一些逻辑来确定它是否需要从另一个使用者那里“窃取”一个分区。 用于断言分区独占所有权的服务机制称为 Epoch。
但是,如果未添加或删除任何实例,则应解决一个根本问题。 有关详细信息,请参阅 分区所有权更改频繁 部分并 提交 GitHub 问题。
CPU 使用率高
CPU 使用率高通常是因为实例拥有的分区过多。 对于每个 CPU 核心,建议不超过三个分区。 最好从每个 CPU 核心的 1.5 个分区开始,然后通过增加拥有的分区数进行测试。
内存不足,选择堆大小
如果 JVM 的当前最大堆不足以运行应用程序,则可能会出现内存不足(OOM)问题。 可能需要度量应用程序的堆需求。 然后,根据结果,使用 -Xmx JVM 选项设置适当的最大堆内存来调整堆的大小。
不应该将 -Xmx 指定为大于主机(VM 或容器)的可用内存或限制设置的值,例如容器配置中请求的内存。 应为主机分配足够的内存以支持 Java 堆。
以下步骤描述了测量最大 Java 堆值的典型方法:
在靠近生产环境的环境中运行应用程序,应用程序在生产中预期的峰值负载下发送、接收和处理事件。
等待应用程序达到稳定状态。 在此阶段,应用程序和 JVM 将加载所有域对象、类类型、静态实例、对象池(TCP、DB 连接池等)。
在稳定状态下,可以看到堆集合的稳定锯齿形图案,如以下屏幕截图所示:
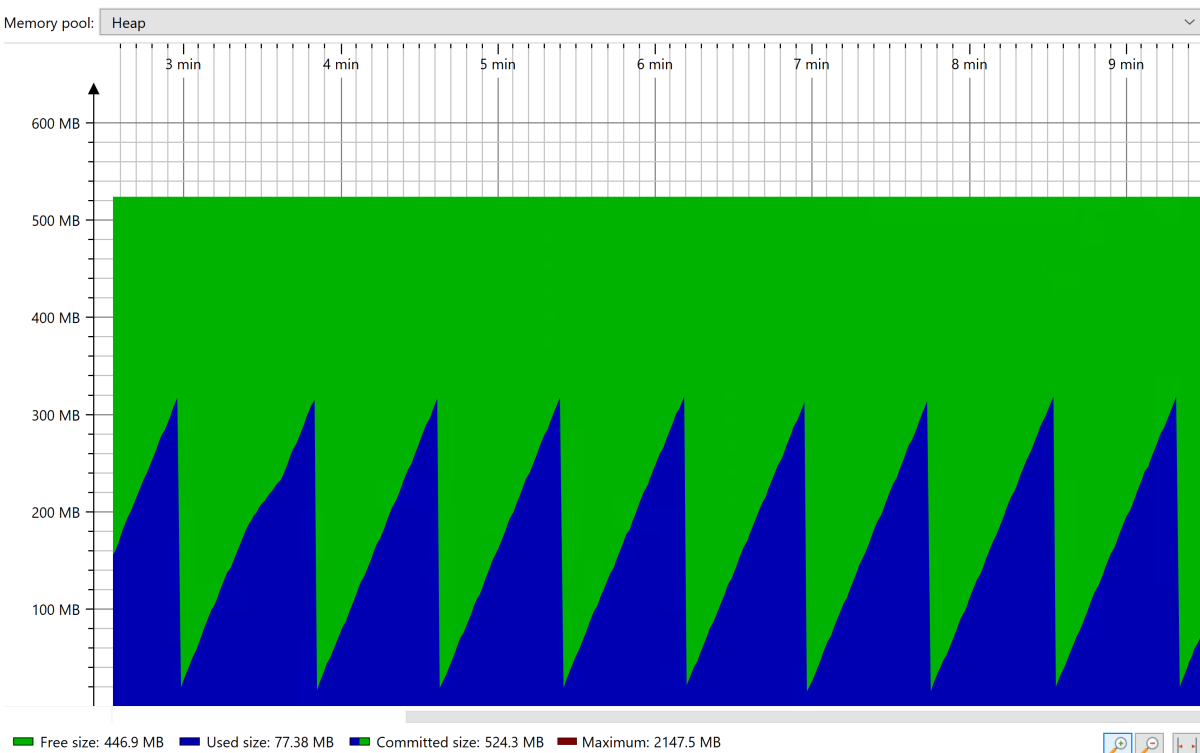
应用程序达到稳定状态后,使用 JConsole 等工具强制进行完全垃圾回收(GC)。 观察完整 GC 后占用的内存。 你想要调整堆的大小,以便在完整 GC 后仅占用 30%。 可以使用此值设置最大堆大小(使用
-Xmx)。

如果您使用的是容器,请调整容器的大小,以便为 JVM 实例的非堆内存需求预留额外约 1 GB 的内存。
处理器客户端停止接收
处理器客户端通常在主机应用程序中持续运行数天。 有时,它注意到 EventProcessorClient 没有处理一个或多个分区。 通常,没有足够的信息来确定异常发生的原因。 EventProcessorClient 停止是尝试从暂时性错误中恢复时发生的根本原因(即争用条件)的一个症状。 有关我们需要的信息,请参阅 提交 GitHub 问题。
重启处理器时接收到重复的事件数据
EventProcessorClient 和事件中心服务保证至少一次交付。 可以添加元数据来识别重复事件。 有关详细信息,请参阅 Azure 事件中心是否保证在 Stack Overflow 上至少传递一次? 如果需要仅传递 一次 ,应考虑服务总线,该服务总线会等待来自客户端的确认。 有关消息传送服务的比较,请参阅 在 Azure 消息传送服务之间进行选择。
低级别使用者客户端停止接收
EventHubConsumerAsyncClient 是事件中心库提供的低级使用者客户端,专为需要对其反应应用程序进行更大控制和灵活性的高级用户而设计。 此客户端提供低级别接口,使用户能够在 Reactor 链中管理反压、线程处理和恢复。 与 EventProcessorClient 不同,EventHubConsumerAsyncClient 并不包括针对所有终端原因的自动恢复机制。 因此,用户必须处理终端事件,并选择适当的 Reactor 操作符来实现恢复策略。
当 EventHubConsumerAsyncClient::receiveFromPartition 连接遇到不可重试错误或一系列连接恢复尝试连续失败时,该方法会发出终端错误,从而耗尽最大重试限制。 尽管低级别接收器会尝试从暂时性错误中恢复,但使用者客户端的用户应处理终端事件。 如果需要连续事件接收,应用程序应调整 Reactor 链,以在终端事件上创建新的使用者客户端。
从旧客户端库迁移到新客户端库
迁移指南包括从旧客户端迁移和迁移旧检查点的步骤。
后续步骤
如果本文中的故障排除指南在使用 Azure SDK for Java 客户端库时无法解决问题,建议在 Azure SDK for Java GitHub 存储库中提出问题。