本教程介绍如何在 Azure Databricks 笔记本中使用 Python 执行探索数据分析(EDA),从加载数据到通过数据可视化生成见解。
本教程中使用的笔记本将检查全球能源和排放数据,并演示如何加载、清理和浏览数据。
可以使用示例笔记本,或从头开始创建自己的笔记本。
什么是 EDA?
探索性数据分析(EDA)是数据科学过程中的关键初始步骤,涉及分析和可视化数据:
- 揭开其主要特征。
- 确定模式和趋势。
- 检测异常。
- 了解变量之间的关系。
EDA 提供有关数据集的见解,有助于做出有关进一步统计分析或建模的明智决策。
借助 Azure Databricks 笔记本,数据科学家可以使用熟悉的工具执行 EDA。 例如,本教程使用一些常见的 Python 库来处理和绘制数据,包括:
- Numpy:用于数值计算的基本库,为数组、矩阵和各种数学函数提供支持,用于对这些数据结构进行作。
- pandas:基于 NumPy 构建的强大数据作和分析库,它提供数据结构(如 DataFrames)以高效处理结构化数据。
- Plotly:一个交互式图形库,可用于创建高质量的交互式可视化效果,以便进行数据分析和展示。
- Matplotlib:用于在 Python 中创建静态、动画和交互式可视化效果的综合库。
Azure Databricks 还提供内置功能,可帮助你浏览笔记本输出中的数据,例如筛选和搜索表中的数据,以及放大可视化效果。 还可以使用 Databricks 助手来帮助编写 EDA 的代码。
开始之前
若要完成本教程,需要满足以下条件:
- 你必须有权使用现有计算资源或创建新的计算资源。 请参阅计算。
- [可选]本教程介绍如何使用助手来帮助你生成代码。 若要使用助理,需要在帐户和工作区中启用助手。 有关详细信息 ,请参阅“使用 Databricks 助手 ”。
下载数据集并导入 CSV 文件
本教程通过检查全球能源和排放数据来演示 EDA 技术。 若要跟随步骤,请从 Kaggle 下载 Our World in Data 的能耗数据集。 本教程使用 owid-energy-data.csv 文件。
若要将数据集导入 Azure Databricks 工作区,请执行以下作:
在工作区的边栏中,单击“ 工作区 ”以导航到工作区浏览器。
将 CSV 文件
owid-energy-data.csv拖放到工作区中。这会打开 “导入 ”模式。 请注意此处列出的 目标文件夹 。 这设定为工作区浏览器中的当前文件夹,并作为导入文件的存放位置。
点击导入。 该文件应显示在工作区的目标文件夹中。
稍后需要文件路径才能将文件加载到笔记本中。 在工作区浏览器中查找该文件。 若要将文件路径复制到剪贴板,请右键单击文件名,然后选择“复制 URL/路径>”。
创建新的 Notebook
若要在用户主文件夹中创建新笔记本,请单击边栏中的“ ![]() 新建 ”,然后从菜单中选择 “笔记本 ”。
新建 ”,然后从菜单中选择 “笔记本 ”。
在顶部的笔记本名称旁边,选择 Python 作为笔记本的默认语言。
若要了解有关创建和管理笔记本的详细信息,请参阅管理笔记本。
将本文中的每个代码示例添加到笔记本中的新单元格。 或者,使用提供的示例笔记本来跟随本教程。
加载 CSV 文件
在新笔记本单元中,加载 CSV 文件。 为此,请导入 numpy 和 pandas。 这些库是用于数据科学和分析的 Python 库。
从数据集创建 pandas 数据帧,以便更轻松地处理和可视化。 将下面的文件路径替换为之前复制的文件路径。
import numpy as np
import pandas as pd # Data processing, CSV file I/O (e.g. pd.read_csv)
df=pd.read_csv('/Workspace/Users/demo@databricks.com/owid-energy-data.csv') # Replace the file path here with the workspace path you copied earlier
运行该单元。 输出应返回 pandas 数据帧,包括每个列及其类型的列表。

了解数据
了解数据集的基础知识对于任何数据科学项目都至关重要。 它涉及到熟悉手头数据的结构、类型和质量。
在 Azure Databricks 笔记本中,可以使用 display(df) 该命令来显示数据集。

由于数据集的行数超过 10,000 行,因此此命令返回截断的数据集。 在每个列的左侧,可以看到列的数据类型。 若要了解详细信息,请参阅 “设置列格式”。
使用 Python 的 pandas 库来获取数据见解
若要有效地了解数据集,请使用以下 pandas 命令:
该
df.shape命令返回 DataFrame 的尺寸,让你快速了解行数和列数。
该
df.dtypes命令提供每列的数据类型,帮助你了解要处理的数据类型。 还可以在结果表中查看每个列的数据类型。
该
df.describe()命令为数字列(例如平均值、标准偏差和百分位)生成描述性统计信息,这有助于识别模式、检测异常并了解数据的分布。
生成数据概况
注释
在 Databricks Runtime 9.1 LTS 及更高版本中可用。
Azure Databricks 笔记本包括内置数据分析功能。 使用 Azure Databricks 显示函数查看 DataFrame 时,可以从表输出生成数据配置文件。
# Display the DataFrame, then click "+ > Data Profile" to generate a data profile
display(df)

单击输出中“表”旁边的“+数据配置文件”。> 这会运行一个新命令,该命令会在 DataFrame 中生成数据的配置文件。

数据概况包括数值、字符串和日期列的摘要统计信息,以及每个列的值分布直方图。 你也可以通过编程方式生成数据配置文件;请参阅汇总命令 (dbutils.data.summarize)。
清理数据
清理数据是 EDA 中的重要步骤,可确保数据集准确、一致且已准备好进行有意义的分析。 此过程涉及多个关键任务,以确保数据已准备好进行分析,包括:
- 标识和删除任何重复的数据。
- 处理缺失值,这可能涉及将它们替换为特定值或删除受影响的行。
- 通过转换和变换标准化数据类型(例如,将字符串转换为
datetime),以确保一致性。 你可能还希望将数据转换为更易于使用的格式。
此清理阶段至关重要,因为它可提高数据的质量和可靠性,从而实现更准确和更深入的分析。
提示:使用 Databricks 助手帮助执行数据清理任务
可以使用 Databricks 助手来帮助你生成代码。 创建新的代码单元格,然后单击 生成 链接或使用右上角的助手图标打开助手。 为助手输入查询。 助手可以生成 Python 或 SQL 代码或生成文本说明。 对于不同的结果,请单击“ 重新生成”。
例如,请尝试以下提示使用助手来帮助清理数据:
- 检查是否
df包含任何重复的列或行。 打印副本。 然后,删除重复项。 - 日期列的格式是什么? 将其更改为
'YYYY-MM-DD'。 - 我不会使用
XXX列。 删除它。
删除重复数据
检查数据是否有任何重复的行或列。 如果是,请将其删除。
小提示
使用助手为你生成代码。
尝试输入提示:“检查 df 是否包含任何重复的列或行。 打印副本。 然后,删除重复项。 助手可能会生成类似于以下示例的代码。
# Check for duplicate rows
duplicate_rows = df.duplicated().sum()
# Check for duplicate columns
duplicate_columns = df.columns[df.columns.duplicated()].tolist()
# Print the duplicates
print("Duplicate rows count:", duplicate_rows)
print("Duplicate columns:", duplicate_columns)
# Drop duplicate rows
df = df.drop_duplicates()
# Drop duplicate columns
df = df.loc[:, ~df.columns.duplicated()]
在这种情况下,数据集没有任何重复的数据。
处理 null 值或缺失值
处理 NaN 或 Null 值的常见方法是将它们替换为 0,以便更轻松地进行数学处理。
df = df.fillna(0) # Replace all NaN (Not a Number) values with 0
这可确保数据帧中的任何缺失数据都替换为 0,这对于后续数据分析或处理步骤(其中缺失值可能会导致问题)非常有用。
重新设置日期格式
日期通常以不同数据集中的各种方式进行格式设置。 它们可能采用日期格式、字符串或整数。
对于此分析,请将 year 列视为整数。 以下代码是执行此作的一种方法:
# Ensure the 'year' column is converted to the correct data type (integer for year)
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# Confirm the changes
df.year.dtype
这可确保 year 列仅包含整数年份值,任何无效条目都转换为 NaT(不是时间)。
使用 Databricks 笔记本输出表浏览数据
Azure Databricks 提供内置功能,可帮助你使用输出表浏览数据。
在新单元格中,用于 display(df) 将数据集显示为表。

使用输出表,可以通过多种方式浏览数据:
在数据中搜索特定字符串或值
单击表右上角的搜索图标并输入搜索。

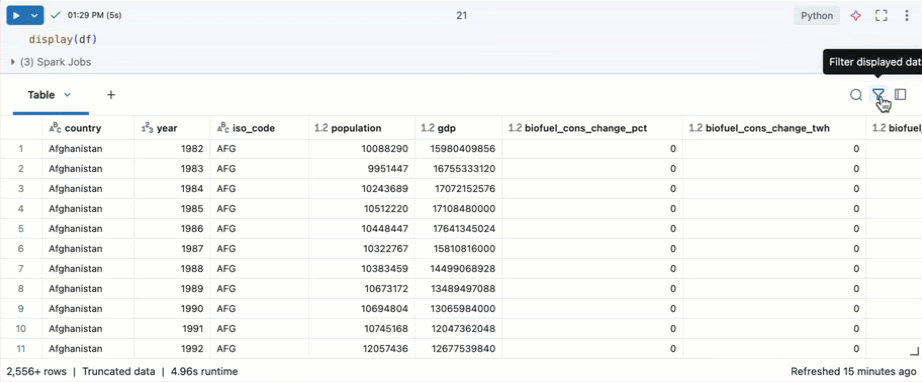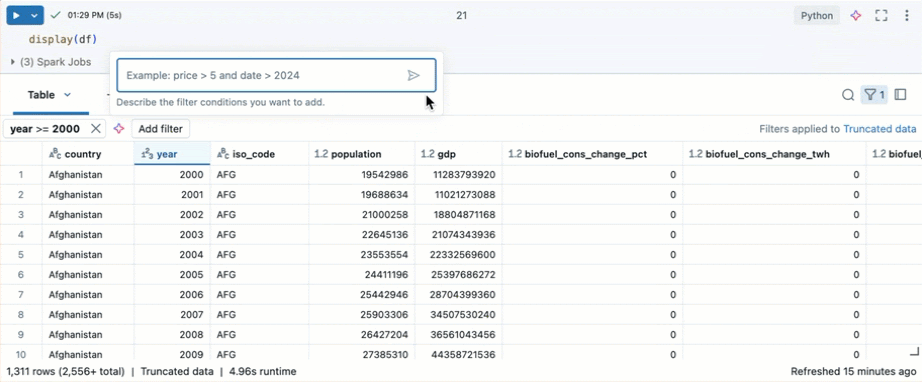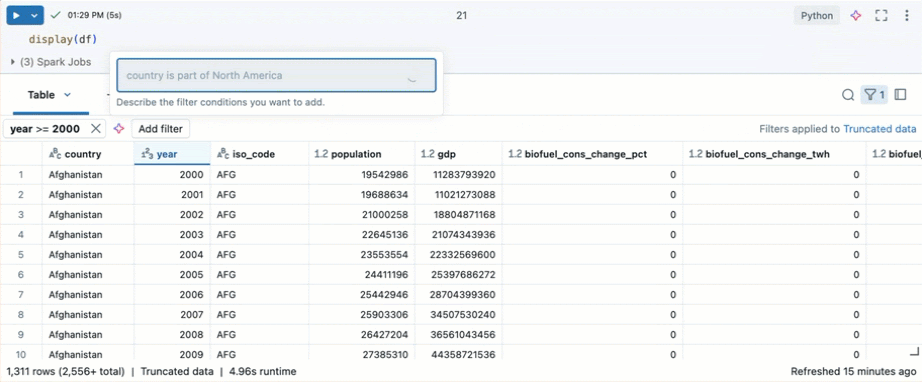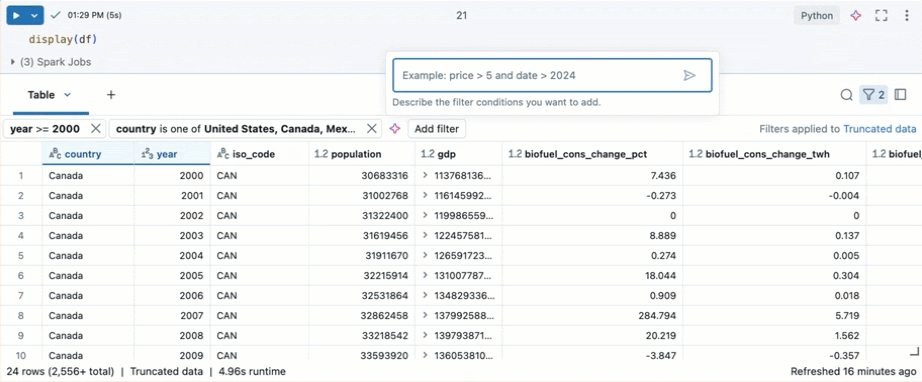
根据特定条件进行筛选
可以使用内置表筛选器,根据特定条件对列进行筛选。 可通过多种方式创建筛选器。 请参阅筛选结果。
小提示
使用 Databricks Assistant 创建筛选器。 单击表格右上角的筛选器图标。 输入筛选器条件。 Databricks Assistant 会自动为你生成筛选器。
使用数据集创建可视化效果
在输出表顶部,单击“+”>打开可视化编辑器。

选择要可视化的可视化类型和列。 编辑器根据配置显示图表预览。 例如,下图显示了如何添加多个折线图以查看随时间推移的各种可再生能源的消耗。

单击“ 保存” 以将可视化效果添加为单元格输出中的选项卡。
请参阅创建新的可视化效果。
使用 Python 库浏览和可视化数据
使用可视化效果浏览数据是 EDA 的基本方面。 可视化效果有助于发现数据中的模式、趋势和关系,这些模式、趋势和关系可能不是通过数值分析直接可见。 将 Plotly 或 Matplotlib 等库用于常见可视化技术,包括散点图、条形图、折线图和直方图。 这些可视化工具允许数据科学家识别异常、了解数据分布以及观察变量之间的相关性。 例如,散点图可以突出显示离群值,而时序图可以揭示趋势和季节性。
为唯一国家/地区创建数组
通过为唯一国家/地区创建数组来检查数据集中包含的国家/地区。 创建一个数组后,你可以看到列出的 country 实体。
# Get the unique countries
unique_countries = df['country'].unique()
unique_countries
输出:

洞察力:
该 country 列包括各种实体,包括世界、高收入国家、亚洲和美国,这些实体并不总是直接比较的。 按区域筛选数据可能更有用。
前 10 个排放器的图表排放趋势 (200-2022)
假设你想要将调查重点放在 2000 年代温室气体排放量最高的 10 个国家上。 可以筛选要查看的年份的数据,以及排放量最多的前 10 个国家/地区,然后使用绘图创建一个折线图,显示其随时间推移的排放量。
import plotly.express as px
# Filter data to include only years from 2000 to 2022
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# Get the top 10 countries with the highest emissions in the filtered data
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# Filter the data for those top countries
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# Plot emissions trends over time for these countries
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
输出:

洞察力:
温室气体排放量从2000年到2022年呈上升趋势,但少数国家排放量相对稳定,在此期间略有下降。
按区域筛选和绘制排放图表
按区域筛选出数据,并计算每个区域的总排放量。 然后将数据绘制为条形图:
# Filter out regional entities
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# Calculate total emissions for each region
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# Plot the comparison
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()
输出:

见解:
亚洲的温室气体排放量最高。 大洋洲、南美洲和非洲的温室气体排放量最低。
计算和绘制可再生能源份额增长图
创建一个新的特征/列,用于计算可再生能源份额,作为可再生能源消耗与主要能耗的比例。 然后,根据国家的平均可再生能源份额对国家进行排名。 对于前 10 个国家,随着时间的推移,绘制其可再生能源份额:
# Calculate the renewable energy share and save it as a new column called "renewable_share"
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# Rank countries by their average renewable energy share
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# Filter for countries leading in renewable energy share
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
leading_renewable_data_filter=leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# Plot renewable share over time for top renewable countries
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
输出:

洞察力:
挪威和冰岛在可再生能源方面处于领先地位,其中超过一半的消费来自可再生能源。
冰岛和瑞典的可再生能源份额增长最大。 所有国家偶尔看到下降和上升,表明可再生能源份额的增长不一定是线性的。 有趣的是,中非在2010年代初出现下滑,但2020年反弹。
散点图:显示可再生能源对最大排放国的影响
筛选前 10 个排放者的数据,然后使用散点图查看可再生能源份额与随时间推移的温室气体排放量。
# Select top emitters and calculate renewable share vs. emissions
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# Plot renewable share vs. greenhouse gas emissions over time
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="Impact of Renewable Energy on Emissions for Top Emitters")
fig.show()
输出:

洞察力:
作为一个国家使用更多的可再生能源,它也有更多的温室气体排放,这意味着其总能耗比可再生能源的消耗速度要快。 北美是一个例外,因为它的温室气体排放量多年来保持相对不变,因为它的可再生能源份额继续增加。
模型预测全球能耗
按年聚合全球主要能耗,然后构建自动回归综合移动平均(ARIMA)模型,预测未来几年全球总能耗。 使用 Matplotlib 绘制历史和预测的能耗。
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# Aggregate global primary energy consumption by year
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# Build an ARIMA model for projection
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # Projecting for 10 years
# Plot historical and forecasted energy consumption
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
输出:

洞察力:
这个模型预测全球能耗将继续上升。
示例笔记本
使用以下笔记本执行本文中的步骤。 有关将笔记本导入 Azure Databricks 工作区的说明,请参阅 “导入笔记本”。
教程:具有全球能源数据的 EDA
后续步骤
现在,你已对数据集执行了一些初始探索数据分析,请尝试执行以下后续步骤: