적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
이 문서에서는 실시간 유추에 사용하기 위해 모델을 온라인 엔드포인트에 배포하는 방법을 알아봅니다. 먼저 로컬 컴퓨터에 모델을 배포하여 오류를 디버깅합니다. 그런 다음 Azure에서 모델을 배포 및 테스트하고, 배포 로그를 보고, SLA(서비스 수준 계약)를 모니터링합니다. 이 문서의 끝부분에는 실시간 유추에 사용할 수 있는 확장 가능한 HTTPS/REST 엔드포인트가 있습니다.
온라인 엔드포인트란 실시간 유추에 사용되는 엔드포인트입니다. 온라인 엔드포인트에는 관리형 온라인 엔드포인트와 Kubernetes 온라인 엔드포인트의 두 가지 유형이 있습니다. 차이점에 대한 자세한 내용은 관리형 온라인 엔드포인트와 Kubernetes 온라인 엔드포인트를 참조하세요.
관리형 온라인 엔드포인트는 턴키 방식으로 기계 학습 모델을 배포하는 데 도움이 됩니다. 관리형 온라인 엔드포인트는 확장성 있는 완전 관리형 방식으로 Azure의 강력한 CPU 및 GPU 머신에서 작동합니다. 관리형 온라인 엔드포인트는 모델 제공, 크기 조정, 보안 및 모니터링을 처리합니다. 이 지원을 통해 기본 인프라를 설정하고 관리하는 오버헤드에서 벗어날 수 있습니다.
이 문서의 주요 예제에서는 배포에 관리형 온라인 엔드포인트를 사용합니다. Kubernetes를 대신 사용하려면 이 문서의 참고 사항을 관리형 온라인 엔드포인트에 대한 설명과 함께 참조하세요.
필수 조건
적용 대상:Azure CLI ml 확장 v2(현재)
Azure RBAC(Azure 역할 기반 액세스 제어)는 Azure Machine Learning에서 작업에 대한 액세스 권한을 부여하는 데 사용됩니다. 이 문서의 단계를 수행하려면 사용자 계정에 Azure Machine Learning 작업 영역에 대한 소유자 또는 기여자 역할이 할당되거나 사용자 지정 역할이 허용 Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*되어야 합니다. Azure Machine Learning Studio를 사용하여 온라인 엔드포인트 또는 배포를 만들고 관리하는 경우 리소스 그룹 소유자의 추가 권한이 Microsoft.Resources/deployments/write 필요합니다. 자세한 내용은 Azure Machine Learning 작업 영역에 대한 액세스 관리를 참조하세요.
(선택 사항) 로컬로 배포하려면 로컬 컴퓨터에 Docker 엔진을 설치 해야 합니다. 문제를 더 쉽게 디버그할 수 있도록 하는 이 옵션을 사용하는 것이 좋습니다 .
이 문서의 단계를 따르기 전에 다음 필수 구성 요소가 있는지 확인합니다.
이러한 단계에서는 Azure CLI 및 기계 학습용 CLI 확장이 사용되지만 주요 초점은 아닙니다. 템플릿을 Azure에 전달하고 템플릿 배포의 상태를 확인하는 유틸리티로 더 많이 사용됩니다.
- Azure RBAC는 Azure Machine Learning에서 작업에 대한 액세스 권한을 부여하는 데 사용됩니다. 이 문서의 단계를 수행하려면 사용자 계정에 Azure Machine Learning 작업 영역에 대한 소유자 또는 기여자 역할이 할당되거나 사용자 지정 역할이 허용
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*되어야 합니다. 자세한 내용은 Azure Machine Learning 작업 영역에 대한 액세스 관리를 참조하세요.
배포를 위해 할당된 VM(가상 머신) 할당량이 충분한지 확인합니다. Azure Machine Learning은 일부 VM 버전에서 업그레이드를 수행하기 위해 컴퓨팅 리소스의 20개% 예약합니다. 예를 들어 배포에서 10개의 인스턴스를 요청하는 경우 VM 버전의 각 코어 수에 대해 12의 할당량이 있어야 합니다. 추가 컴퓨팅 리소스를 고려하지 않으면 오류가 발생합니다. 일부 VM 버전은 추가 할당량 예약에서 제외됩니다. 할당량 할당에 대한 자세한 내용은 배포에 대한 가상 머신 할당량 할당을 참조하세요.
또는 제한된 시간 동안 Azure Machine Learning 공유 할당량 풀의 할당량을 사용할 수 있습니다. Azure Machine Learning은 다양한 지역의 사용자가 할당량에 액세스하여 가용성에 따라 제한된 시간 동안 테스트를 수행할 수 있는 공유 할당량 풀을 제공합니다.
스튜디오를 사용하여 모델 카탈로그의 Llama-2, Phi, Nemotron, Mistral, Dolly 및 Deci-DeciLM 모델을 관리형 온라인 엔드포인트에 배포하는 경우 Azure Machine Learning을 사용하면 잠시 공유 할당량 풀에 액세스하여 테스트를 수행할 수 있습니다. 공유 할당량 풀에 대한 자세한 내용은 Azure Machine Learning 공유 할당량을 참조하세요.
시스템 준비
환경 변수 설정
Azure CLI에 대한 기본값을 아직 설정하지 않은 경우 기본 설정을 저장합니다. 구독, 작업 영역 및 리소스 그룹에 대한 값을 여러 번 전달하지 않으려면 다음 코드를 실행하세요.
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
예제 리포지토리 복제
이 문서를 따르려면 먼저 azureml-examples 리포지토리를 복제한 다음 리포지토리의 azureml-examples/cli 디렉터리로 변경합니다.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
리포지토리에 대한 최신 커밋만 복제하여 작업을 완료하는 시간을 단축하는 데 사용합니다 --depth 1 .
이 자습서의 명령은 deploy-local-endpoint.sh 파일에 있으며cli 디렉터리의 deploy-managed-online-endpoint.sh. YAML 구성 파일은 엔드포인트/온라인/관리/샘플/ 하위 디렉터리에 있습니다.
참고 항목
Kubernetes 온라인 엔드포인트에 대한 YAML 구성 파일은 엔드포인트/온라인/kubernetes/ 하위 디렉터리에 있습니다.
예제 리포지토리 복제
학습 예제를 실행하려면 먼저 azureml-examples 리포지토리를 복제한 다음 azureml-examples/sdk/python/endpoints/online/managed directory로 변경합니다.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
리포지토리에 대한 최신 커밋만 복제하여 작업을 완료하는 시간을 단축하는 데 사용합니다 --depth 1 .
이 문서의 정보는 online-endpoints-simple-deployment.ipynb Notebook을 기반으로 합니다. 코드 순서는 약간 다르지만 이 문서와 동일한 콘텐츠가 포함되어 있습니다.
Azure Machine Learning 작업 영역에 연결
작업 영역은 Azure Machine Learning의 최상위 리소스입니다. Azure Machine Learning을 사용할 때 만드는 모든 아티팩트를 사용할 수 있는 중앙 집중식 위치를 제공합니다. 이 섹션에서는 배포 작업을 수행하는 작업 영역에 연결합니다. 따라가려면 online-endpoints-simple-deployment.ipynb 노트북 파일을 여세요.
필요한 라이브러리 가져오기:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
참고 항목
Kubernetes 온라인 엔드포인트를 사용하는 경우 KubernetesOnlineEndpoint 라이브러리에서 KubernetesOnlineDeployment 클래스와 azure.ai.ml.entities 클래스를 가져옵니다.
작업 영역 세부 정보를 구성하고 작업 영역에 대한 핸들을 가져옵니다.
작업 영역에 연결하려면 구독, 리소스 그룹 및 작업 영역 이름과 같은 식별자 매개 변수가 필요합니다. 필요한 Azure Machine Learning 작업 영역 핸들을 얻기 위해 MLClient의 azure.ai.ml에서 이러한 세부 정보를 사용합니다. 이 예제에서는 기본 Azure 인증을 사용합니다.
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
로컬 컴퓨터에 Git이 설치되어 있는 경우 지침에 따라 예제 리포지토리를 복제할 수 있습니다. 그렇지 않으면 지침에 따라 예제 리포지토리에서 파일을 다운로드합니다.
예제 리포지토리 복제
이 문서를 따라가려면 먼저 azureml-examples 리포지토리를 복제한 다음 azureml-examples/cli/endpoints/online/model-1 디렉터리로 변경합니다.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
리포지토리에 대한 최신 커밋만 복제하여 작업을 완료하는 시간을 단축하는 데 사용합니다 --depth 1 .
예제 리포지토리에서 파일 다운로드
예제 리포지토리를 복제한 경우 로컬 컴퓨터에는 이미 이 예제에 대한 파일 복사본이 있으므로 다음 섹션으로 건너뛸 수 있습니다. 리포지토리를 복제하지 않은 경우 로컬 컴퓨터에 다운로드합니다.
-
예제 리포지토리(azureml-examples)로 이동합니다.
- 페이지의 코드 단추로 <> 이동한 다음 로컬 탭에서 ZIP 다운로드를 선택합니다.
-
/cli/endpoints/online/model-1/model 및 /cli/endpoints/online/model-1/onlinescoring/score.py 파일을 찾습니다.
환경 변수 설정
이 문서의 예제에서 사용할 수 있도록 다음 환경 변수를 설정합니다. 값을 Azure 구독 ID, 작업 영역이 있는 Azure 지역, 작업 영역이 포함된 리소스 그룹 및 작업 영역 이름으로 바꿉니다.
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
몇 가지 템플릿 예제를 사용하려면 작업 영역에 대한 Azure Blob Storage에 파일을 업로드해야 합니다. 다음 단계에서는 작업 영역을 쿼리하고 이 정보를 예제에 사용된 환경 변수에 저장합니다.
액세스 토큰 가져오기:
TOKEN=$(az account get-access-token --query accessToken -o tsv)
REST API 버전 설정:
API_VERSION="2022-05-01"
스토리지 정보 가져오기:
# Get values for storage account
response=$(curl --___location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
예제 리포지토리 복제
이 문서를 따르려면 먼저 azureml-examples 리포지토리를 복제한 다음 azureml-examples 디렉터리로 변경합니다.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
리포지토리에 대한 최신 커밋만 복제하여 작업을 완료하는 시간을 단축하는 데 사용합니다 --depth 1 .
엔드포인트 정의
온라인 엔드포인트를 정의하려면 엔드포인트 이름 및 인증 모드를 지정합니다. 관리되는 온라인 엔드포인트에 대한 자세한 내용은 온라인 엔드포인트를 참조하세요.
엔드포인트 이름 설정
엔드포인트 이름을 설정하려면 다음 명령을 실행합니다.
<YOUR_ENDPOINT_NAME>을 Azure 지역에서 고유한 이름으로 바꿉니다. 명명 규칙에 대한 자세한 내용은 엔드포인트 제한을 참조하세요.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
다음 코드 조각은 엔드포인트/온라인/관리/샘플/endpoint.yml 파일을 보여 줍니다.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
엔드포인트 YAML 형식에 대한 참조는 다음 표에 설명되어 있습니다. 이러한 특성을 지정하는 방법을 알아보려면 온라인 엔드포인트 YAML 참조를 참조하세요. 관리형 엔드포인트와 관련된 제한에 대한 자세한 내용은 Azure Machine Learning 온라인 엔드포인트 및 일괄 처리 엔드포인트를 참조하세요.
| 키 |
설명 |
$schema |
(선택 사항) YAML 스키마입니다. YAML 파일에서 사용 가능한 모든 옵션을 보려면 브라우저에서 이전 코드 조각의 스키마를 볼 수 있습니다. |
name |
엔드포인트의 이름입니다. |
auth_mode |
키 기반 인증의 경우 key를 사용합니다.
Azure Machine Learning 토큰 기반 인증에 대해 aml_token을 사용합니다.
Microsoft Entra 토큰 기반 인증(미리 보기)에는 aad_token을 사용합니다.
인증에 대한 자세한 내용은 온라인 엔드포인트에 대한 클라이언트 인증을 참조하세요. |
먼저 온라인 엔드포인트의 이름을 정의한 다음 엔드포인트를 구성합니다.
사용자 <YOUR_ENDPOINT_NAME>를 Azure 지역에서 고유한 이름으로 바꾸거나, 예제 메서드를 사용하여 임의의 이름을 정의합니다. 사용하지 않는 메서드를 삭제해야 합니다. 명명 규칙에 대한 자세한 내용은 엔드포인트 제한을 참조하세요.
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
이전 코드는 키 기반 인증에 key를 사용합니다. Azure Machine Learning 토큰 기반 인증을 사용하려면 aml_token을 사용합니다. Microsoft Entra 토큰 기반 인증(미리 보기)을 사용하려면 aad_token을 사용합니다. 인증에 대한 자세한 내용은 온라인 엔드포인트에 대한 클라이언트 인증을 참조하세요.
스튜디오에서 Azure에 배포하는 경우 추가할 엔드포인트 및 배포를 만듭니다. 이때 엔드포인트 및 배포에 대한 이름을 입력하라는 메시지가 표시됩니다.
배포 정의
배포는 실제 유추를 수행하는 모델을 호스팅하는 데 필요한 리소스의 세트입니다. 이 예제에서는 회귀를 scikit-learn 수행하는 모델을 배포하고 점수 매기기 스크립트 score.py 사용하여 특정 입력 요청에서 모델을 실행합니다.
배포의 주요 특성에 대해 알아보려면 온라인 배포를 참조하세요.
배포 구성은 배포하려는 모델의 위치를 사용합니다.
다음 코드 조각은 배포를 구성하는 데 필요한 모든 입력과 함께 엔드포인트/온라인/관리/샘플/blue-deployment.yml 파일을 보여 줍니다.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
blue-deployment.yml 파일은 다음 배포 특성을 지정합니다.
-
model: 매개 변수(파일을 업로드할 위치)를 사용하여 path 모델 속성을 인라인으로 지정합니다. CLI는 자동으로 모델 파일을 업로드하고 자동 생성된 이름으로 모델을 등록합니다.
-
environment: 파일을 업로드할 위치를 포함하는 인라인 정의를 사용합니다. CLI는 conda.yaml 파일을 자동으로 업로드하고 환경을 등록합니다. 나중에 환경을 빌드하기 위해 배포는 기본 이미지에 image 대한 매개 변수를 사용합니다. 이 예에서는 mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest입니다.
conda_file 종속성은 기본 이미지 위에 설치됩니다.
-
code_configuration: 배포하는 동안 개발 환경에서 점수 매기기 모델의 Python 원본과 같은 로컬 파일을 업로드합니다.
YAML 스키마에 대한 자세한 내용은 온라인 엔드포인트 YAML 참조를 참조하세요.
참고 항목
관리형 온라인 엔드포인트 대신 Kubernetes 엔드포인트를 컴퓨팅 대상으로 사용하려면 다음 안내를 따릅니다.
-
Azure Machine Learning 스튜디오를 사용하여 Kubernetes 클러스터를 컴퓨팅 대상으로 만들고 Azure Machine Learning 작업 영역에 연결합니다.
-
엔드포인트 YAML을 사용하여 관리되는 엔드포인트 YAML 대신 Kubernetes를 대상으로 지정합니다.
compute의 값을 등록된 컴퓨팅 대상의 이름으로 변경하려면 YAML을 편집해야 합니다. Kubernetes 배포에 적용되는 다른 속성이 있는 이 deployment.yaml 을 사용할 수 있습니다.
이 문서에서 관리형 온라인 엔드포인트에 사용되는 모든 명령은 Kubernetes 엔드포인트에 적용되지 않는 다음 기능을 제외하고 Kubernetes 엔드포인트에도 적용됩니다.
다음 코드를 사용하여 배포를 구성합니다.
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
-
Model: 매개 변수(파일을 업로드할 위치)를 사용하여 path 모델 속성을 인라인으로 지정합니다. SDK는 자동으로 모델 파일을 업로드하고 자동 생성된 이름으로 모델을 등록합니다.
-
Environment: 파일을 업로드할 위치를 포함하는 인라인 정의를 사용합니다. SDK는 conda.yaml 파일을 자동으로 업로드하고 환경을 등록합니다. 나중에 환경을 빌드하기 위해 배포는 기본 이미지에 image 대한 매개 변수를 사용합니다. 이 예에서는 mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest입니다.
conda_file 종속성은 기본 이미지 위에 설치됩니다.
-
CodeConfiguration: 배포하는 동안 개발 환경에서 점수 매기기 모델의 Python 원본과 같은 로컬 파일을 업로드합니다.
온라인 배포 정의에 대한 자세한 내용은 OnlineDeployment 클래스를 참조하세요.
Azure에 배포할 때 추가할 엔드포인트 및 배포를 만듭니다. 이때 엔드포인트 및 배포에 대한 이름을 입력하라는 메시지가 표시됩니다.
채점 스크립트 이해
온라인 엔드포인트의 점수 매기기 스크립트의 형식은 이전 버전의 CLI 및 Python SDK에서 사용된 것과 동일한 형식입니다.
code_configuration.scoring_script에 지정된 채점 스크립트에는 init() 함수와 run() 함수가 있어야 합니다.
채점 스크립트에는 init() 함수와 run() 함수가 있어야 합니다.
채점 스크립트에는 init() 함수와 run() 함수가 있어야 합니다.
채점 스크립트에는 init() 함수와 run() 함수가 있어야 합니다. 이 문서에서는 score.py 파일을 사용합니다.
배포에 템플릿을 사용하는 경우 먼저 점수 매기기 파일을 Blob Storage에 업로드한 다음 등록해야 합니다.
다음 코드는 Azure CLI 명령을 az storage blob upload-batch 사용하여 점수 매기기 파일을 업로드합니다.
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
다음 코드는 템플릿을 사용하여 코드를 등록합니다.
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
이 예제에서는 이전에 복제하거나 다운로드한 리포지토리의 score.py 파일을 사용합니다.
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
컨테이너가 초기화/시작되면 init() 함수가 호출됩니다. 초기화는 일반적으로 배포를 만들거나 업데이트한 직후에 발생합니다. 이 init 함수는 메모리에 모델을 캐싱하는 것과 같은 전역 초기화 작업에 대한 논리를 작성하는 위치입니다(이 score.py 파일에 표시된 대로).
이 run() 함수는 엔드포인트가 호출될 때마다 호출됩니다. 실제 채점 및 예측을 수행합니다. 이 score.py 파일에서 함수는 run() JSON 입력에서 데이터를 추출하고 scikit-learn 모델의 predict() 메서드를 호출한 다음 예측 결과를 반환합니다.
로컬 엔드포인트를 사용하여 로컬로 배포 및 디버그
Azure에 배포하기 전에 엔드포인트를 로컬로 실행하여 코드 및 구성의 유효성을 검사하고 디버그하는 것이 좋습니다 . Azure CLI 및 Python SDK는 로컬 엔드포인트 및 배포를 지원하지만 Azure Machine Learning 스튜디오 및 ARM 템플릿은 지원하지 않습니다.
로컬로 배포하려면 Docker 엔진 을 설치하고 실행해야 합니다. Docker 엔진은 일반적으로 컴퓨터가 시작될 때 시작됩니다. 그렇지 않은 경우 Docker 엔진 문제를 해결할 수 있습니다.
Azure Machine Learning 유추 HTTP 서버 Python 패키지를 사용하여 Docker 엔진 없이 로컬로 점수 매기기 스크립트를 디버그할 수 있습니다. 유추 서버를 사용하여 디버깅하면 배포 컨테이너 구성의 영향을 받지 않고 디버그할 수 있도록 로컬 엔드포인트에 배포하기 전에 점수 매기기 스크립트를 디버그할 수 있습니다.
Azure에 배포하기 전에 온라인 엔드포인트를 로컬로 디버깅하는 방법에 대한 자세한 내용은 온라인 엔드포인트 디버깅을 참조하세요.
로컬에서 모델 배포
먼저 엔드포인트를 만듭니다. 필요에 따라 로컬 엔드포인트의 경우 이 단계를 건너뛸 수 있습니다. 배포를 직접 만들 수 있습니다(다음 단계). 그러면 필요한 메타데이터가 만들어집니다. 모델을 로컬로 배포하는 것은 개발 및 테스트 목적으로 유용합니다.
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
스튜디오는 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
템플릿은 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
이제 엔드포인트 아래에 blue라는 배포를 만듭니다.
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
--local 플래그는 Docker 환경에 엔드포인트를 배포하도록 CLI에 지시합니다.
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
local=True 플래그는 Docker 환경에 엔드포인트를 배포하도록 SDK에 지시합니다.
스튜디오는 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
템플릿은 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
로컬 배포가 성공했는지 확인
모델이 오류 없이 배포되었는지 확인하려면 배포 상태를 확인합니다.
az ml online-endpoint show -n $ENDPOINT_NAME --local
출력은 다음 JSON과 비슷합니다. 매개 변수는 provisioning_state .입니다 Succeeded.
{
"auth_mode": "key",
"___location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
메서드는 엔터티를 반환ManagedOnlineEndpoint합니다. 매개 변수는 provisioning_state .입니다 Succeeded.
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', '___location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
스튜디오는 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
템플릿은 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
다음 표에는 provisioning_state에 대해 가능한 값이 포함되어 있습니다.
| 값 |
설명 |
Creating |
리소스를 만드는 중입니다. |
Updating |
리소스를 업데이트 중입니다. |
Deleting |
리소스를 삭제하는 중입니다. |
Succeeded |
만들기 또는 업데이트 작업이 성공했습니다. |
Failed |
만들기, 업데이트 또는 삭제 작업이 실패했습니다. |
로컬 엔드포인트를 호출하여 모델로 데이터 채점
invoke 명령을 사용하고 JSON 파일에 저장된 쿼리 매개 변수를 전달하여 엔드포인트를 호출하여 모델 점수를 매깁니다.
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
REST 클라이언트(예: curl)를 사용하려면 채점 URI가 있어야 합니다. 채점 URI를 얻으려면 az ml online-endpoint show --local -n $ENDPOINT_NAME을 실행합니다. 반환된 데이터에서 scoring_uri 특성을 찾습니다.
invoke 명령을 사용하고 JSON 파일에 저장된 쿼리 매개 변수를 전달하여 엔드포인트를 호출하여 모델 점수를 매깁니다.
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
REST 클라이언트(예: curl)를 사용하려면 채점 URI가 있어야 합니다. 점수 매기기 URI를 얻으려면 다음 코드를 실행합니다. 반환된 데이터에서 scoring_uri 특성을 찾습니다.
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
스튜디오는 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
템플릿은 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
호출 작업의 출력에 대한 로그를 검토합니다.
예제 score.py 파일에서 메서드는 run() 콘솔에 일부 출력을 기록합니다.
get-logs 명령을 사용하여 이 출력을 볼 수 있습니다.
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
get_logs 메서드를 사용하여 이 출력을 볼 수 있습니다.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
스튜디오는 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
템플릿은 로컬 엔드포인트를 지원하지 않습니다. 엔드포인트를 로컬로 테스트하는 단계는 Azure CLI 또는 Python 탭을 참조하세요.
Azure에 온라인 엔드포인트 배포
다음으로, Azure에 온라인 엔드포인트를 배포합니다. 프로덕션을 위한 모범 사례로 배포에 사용하는 모델 및 환경을 등록하는 것이 좋습니다.
모델 및 환경 등록
배포 중에 등록된 이름과 버전을 지정할 수 있도록 Azure에 배포하기 전에 모델과 환경을 등록하는 것이 좋습니다. 자산을 등록한 후에는 배포를 만들 때마다 업로드할 필요 없이 다시 사용할 수 있습니다. 이렇게 하면 재현성 및 추적성이 향상됩니다.
Azure에 대한 배포와 달리 로컬 배포는 등록된 모델 및 환경 사용을 지원하지 않습니다. 대신 로컬 배포는 로컬 모델 파일을 사용하고 로컬 파일만 있는 환경을 사용합니다.
Azure에 배포하려면 로컬 또는 등록된 자산(모델 및 환경)을 사용할 수 있습니다. 문서의 이 섹션에서는 Azure에 배포할 때 등록된 자산을 사용하지만 대신 로컬 자산을 사용하는 옵션이 있습니다. 로컬 배포에 사용할 로컬 파일을 업로드하는 배포 구성의 예는 배포 구성을 참조하세요.
모델 및 환경을 등록하려면 model: azureml:my-model:1 또는 environment: azureml:my-env:1 형식을 사용합니다.
등록을 위해 model 폴더의 environment YAML 정의를 별도의 YAML 파일로 추출하고 명령 및 az ml model create를 사용할 수 있습니다az ml environment create. 이러한 명령에 대해 자세히 알아보려면 az ml model create -h 및 az ml environment create -h를 실행합니다.
모델에 대한 YAML 정의를 만듭니다. 파일 이름을 model.yml:
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
모델 등록:
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
환경에 대한 YAML 정의를 만듭니다. 파일 이름을 environment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
환경 등록:
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
모델을 자산으로 등록하는 방법에 대한 자세한 내용은 Azure CLI 또는 Python SDK를 사용하여 모델 등록을 참조하세요. 환경을 만드는 방법에 대한 자세한 내용은 사용자 지정 환경 만들기를 참조하세요.
모델 등록:
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
환경 등록:
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
배포 중에 등록된 이름과 버전을 지정할 수 있도록 모델을 자산으로 등록하는 방법을 알아보려면 Azure CLI 또는 Python SDK를 사용하여 모델 등록을 참조하세요.
환경을 만드는 방법에 대한 자세한 내용은 사용자 지정 환경 만들기를 참조하세요.
모델 등록
모델 등록은 단일 모델 파일을 포함할 수 있는 작업 영역의 논리적 엔터티 또는 여러 파일의 디렉터리입니다. 프로덕션을 위한 모범 사례로 모델 및 환경을 등록합니다. 이 문서에서 엔드포인트 및 배포를 만들기 전에 모델이 포함된 모델 폴더 를 등록합니다.
예제 모델을 등록하려면 다음 단계를 따릅니다.
Azure Machine Learning 스튜디오로 이동합니다.
왼쪽 창에서 모델 페이지를 선택합니다.
등록을 선택한 다음 로컬 파일에서 선택합니다.
모델 형식에 대해 지정되지 않은 형식을 선택합니다.
찾아보기를 선택하고 폴더 찾아보기를 선택합니다.

이전에 복제하거나 다운로드한 리포지토리의 로컬 복사본에서 \azureml-examples\cli\endpoints\online\model-1\model 폴더를 선택합니다. 메시지가 표시되면 업로드를 선택하고 업로드 가 완료될 때까지 기다립니다.
다음을 선택합니다.
친근한 이름을 모델에 입력합니다. 이 문서의 단계에서는 모델의 이름을 model-1지정한다고 가정합니다.
다음을 선택한 다음 등록을 선택하여 등록을 완료합니다.
등록된 모델을 사용하여 작업하는 방법에 대한 자세한 내용은 등록된 모델 작업을 참조하세요.
환경 만들기 및 등록
왼쪽 창에서 환경 페이지를 선택합니다.
사용자 지정 환경 탭을 선택한 다음 만들기를 선택합니다.
설정 페이지에서 환경에 대한 my-env와 같은 이름을 입력합니다.
환경 원본 선택에서 선택적 conda 원본과 함께 기존 Docker 이미지 사용을 선택합니다.

다음을 선택하여 사용자 지정 페이지로 이동합니다.
이전에 복제하거나 다운로드한 리포지토리에서 \azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml 파일의 내용을 복사합니다.
콘텐츠를 텍스트 상자에 붙여넣습니다.

만들기 페이지에 도착할 때까지 다음을 선택한 다음 만들기를 선택합니다.
스튜디오에서 환경을 만드는 방법에 대한 자세한 내용은 환경 만들기를 참조하세요.
템플릿을 사용하여 모델을 등록하려면 먼저 모델 파일을 Blob Storage에 업로드해야 합니다. 다음 예제에서는 az storage blob upload-batch 명령을 사용하여 작업 영역의 기본 스토리지에 파일을 업로드합니다.
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
파일을 업로드한 후 템플릿을 사용하여 모델 등록을 만듭니다. 다음 예제에서 modelUri 매개 변수는 모델에 대한 경로를 포함합니다.
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
환경의 일부는 모델을 호스트하는 데 필요한 모델 종속성을 지정하는 conda 파일입니다. 다음 예제에서는 conda 파일의 내용을 환경 변수로 읽는 방법을 보여 줍니다.
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
다음 예제에서는 템플릿을 사용하여 환경을 등록하는 방법을 보여 줍니다. 이전 단계의 conda 파일 내용은 매개 변수를 사용하여 condaFile 템플릿에 전달됩니다.
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
중요합니다
배포에 대한 사용자 지정 환경을 정의할 때 패키지가 azureml-inference-server-http conda 파일에 포함되어 있는지 확인합니다. 이 패키지는 유추 서버가 제대로 작동하기 위해 필수적입니다. 고유한 사용자 정의 환경을 만드는 방법에 익숙하지 않은 경우, minimal-py-inference을 사용하지 않는 모델용 mlflow 또는 mlflow-py-inference을 사용하는 모델용 mlflow와 같은 큐레이팅된 환경 중 하나를 사용하십시오. 이러한 큐레이팅된 환경은 Azure Machine Learning 스튜디오 인스턴스의 환경 탭에서 찾을 수 있습니다.
배포 구성은 배포하려는 등록된 모델과 등록된 환경을 사용합니다.
배포 정의에 등록된 자산(모델 및 환경)을 사용합니다. 다음 코드 조각은 배포를 구성하는 데 필요한 모든 입력과 함께 엔드포인트/온라인/관리/샘플/blue-deployment-with-registered-assets.yml 파일을 보여 줍니다.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
배포를 구성하려면 등록된 모델과 환경을 사용합니다.
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
스튜디오에서 배포할 때, 엔드포인트를 만들고 그에 대한 배포를 추가합니다. 이때 엔드포인트 및 배포의 이름을 입력하라는 메시지가 표시됩니다.
다른 CPU 및 GPU 인스턴스 유형과 이미지 사용
로컬 배포와 Azure 배포 모두에 대해 배포 정의에서 CPU 또는 GPU 인스턴스 형식과 이미지를 지정할 수 있습니다.
blue-deployment-with-registered-assets.yml 파일의 배포 정의는 범용 형식 Standard_DS3_v2 인스턴스와 GPU가 아닌 Docker 이미지를 mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest사용했습니다. GPU 컴퓨팅의 경우 GPU 컴퓨팅 유형 버전 및 GPU Docker 이미지를 선택합니다.
지원되는 범용 및 GPU 인스턴스 유형은 관리형 온라인 엔드포인트 SKU 목록을 참조하세요. Azure Machine Learning CPU 및 GPU 기본 이미지 목록은 Azure Machine Learning 기본 이미지를 참조하세요.
로컬 배포와 Azure 배포 모두에 대한 배포 구성에서 CPU 또는 GPU 인스턴스 형식과 이미지를 지정할 수 있습니다.
이전에는 범용 형식 Standard_DS3_v2 인스턴스와 비 GPU Docker 이미지 mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest를 사용하는 배포를 구성했습니다. GPU 컴퓨팅의 경우 GPU 컴퓨팅 유형 버전 및 GPU Docker 이미지를 선택합니다.
지원되는 범용 및 GPU 인스턴스 유형은 관리형 온라인 엔드포인트 SKU 목록을 참조하세요. Azure Machine Learning CPU 및 GPU 기본 이미지 목록은 Azure Machine Learning 기본 이미지를 참조하세요.
환경의 사전 등록에서는 매개변수 mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04를 사용하여 environment-version.json 템플릿에 값을 전달함으로써 GPU가 아닌 Docker 이미지 dockerImage를 지정합니다. GPU 컴퓨팅의 경우 템플릿에 GPU Docker 이미지의 값을 제공하고(매개 변수 사용 dockerImage ) 템플릿에 GPU 컴퓨팅 형식 버전을 online-endpoint-deployment.json 제공합니다(매개 변수 사용 skuName ).
지원되는 범용 및 GPU 인스턴스 유형은 관리형 온라인 엔드포인트 SKU 목록을 참조하세요. Azure Machine Learning CPU 및 GPU 기본 이미지 목록은 Azure Machine Learning 기본 이미지를 참조하세요.
다음으로, Azure에 온라인 엔드포인트를 배포합니다.
Azure에 배포
Azure 클라우드에서 엔드포인트를 만듭니다.
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
엔드포인트에 blue라는 이름의 배포를 생성하세요.
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
배포 만들기에는 기본 환경이나 이미지가 처음으로 빌드되는지 여부에 따라 최대 15분이 걸릴 수 있습니다. 동일한 환경을 사용하는 후속 배포는 더 빠르게 처리됩니다.
CLI 콘솔을 차단하지 않으려는 경우 명령에 --no-wait 플래그를 추가할 수 있습니다. 그러나 이 옵션은 배포 상태의 대화형 표시를 중지합니다.
배포를 만드는 데 사용되는 코드 --all-traffic의 az ml online-deployment create 플래그는 새로 만들어진 파란색 배포에 엔드포인트 트래픽의 100%를 할당합니다. 이 플래그를 사용하는 것은 개발 및 테스트 목적에 유용하지만 프로덕션의 경우 명시적 명령을 통해 트래픽을 새 배포로 라우팅할 수 있습니다. 예를 들면 az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100"를 사용합니다.
엔드포인트 만들기:
이전에 정의한 endpoint 매개 변수와 이전에 만든 MLClient 매개 변수를 사용하여 이제 작업 영역에서 엔드포인트를 만들 수 있습니다. 이 명령은 엔드포인트 만들기를 시작하고 엔드포인트 만들기가 계속되는 동안 확인 응답을 반환합니다.
ml_client.online_endpoints.begin_create_or_update(endpoint)
배포 만들기:
이전에 정의한 blue_deployment_with_registered_assets 매개 변수와 이전에 만든 MLClient 매개 변수를 사용하여 이제 작업 영역에서 배포를 만들 수 있습니다. 이 명령은 배포 만들기를 시작하고 배포 만들기가 계속되는 동안 확인 응답을 반환합니다.
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Python 콘솔을 차단하지 않으려는 경우 매개 변수에 no_wait=True 플래그를 추가할 수 있습니다. 그러나 이 옵션은 배포 상태의 대화형 표시를 중지합니다.
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
관리형 온라인 엔드포인트 및 배포 만들기
스튜디오를 사용하여 브라우저에서 직접 관리형 온라인 엔드포인트를 만듭니다. 스튜디오에서 관리형 온라인 엔드포인트를 만들 때 초기 배포를 정의해야 합니다. 비어 있는 관리형 온라인 엔드포인트를 만들 수 없습니다.
스튜디오에서 관리되는 온라인 엔드포인트를 만드는 한 가지 방법은 모델 페이지에서 사용하는 것입니다. 이 방법은 또한 기존의 관리형 온라인 배포에 모델을 추가하는 쉬운 방법을 제공합니다. 모델 및 환경 등록 섹션에서 이전에 등록한 명명 model-1 된 모델을 배포하려면 다음 을 수행합니다 .
Azure Machine Learning 스튜디오로 이동합니다.
왼쪽 창에서 모델 페이지를 선택합니다.
model-1이라는 모델을 선택합니다.
배포>실시간 엔드포인트를 선택합니다.

이 작업을 수행하면 엔드포인트에 대한 세부 정보를 지정할 수 있는 창이 열립니다.

Azure 지역에서 고유한 엔드포인트 이름을 입력합니다. 명명 규칙에 대한 자세한 내용은 엔드포인트 제한을 참조하세요.
컴퓨팅 유형에 대해 관리 되는 기본 선택 항목을 유지합니다.
기본 선택 항목인 인증 유형에 대한 키 기반 인증 을 유지합니다. 인증에 대한 자세한 내용은 온라인 엔드포인트에 대한 클라이언트 인증을 참조하세요.
배포 페이지에 도착할 때까지 다음을 선택합니다. 나중에 스튜디오에서 엔드포인트 활동의 그래프를 보고, Application Insights를 사용하여 메트릭과 로그를 분석할 수 있도록 Application Insights 진단을 사용으로 설정합니다.
다음을 선택하여 코드 + 환경 페이지로 이동합니다. 다음 옵션을 선택합니다.
-
추론에 대한 점수 매기기 스크립트 선택: 이전에 복제하거나 다운로드한 리포지토리에서 \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py 파일을 찾아 선택합니다.
-
환경 섹션 선택 : 사용자 지정 환경을 선택한 다음, 이전에 만든 my-env:1 환경을 선택합니다.
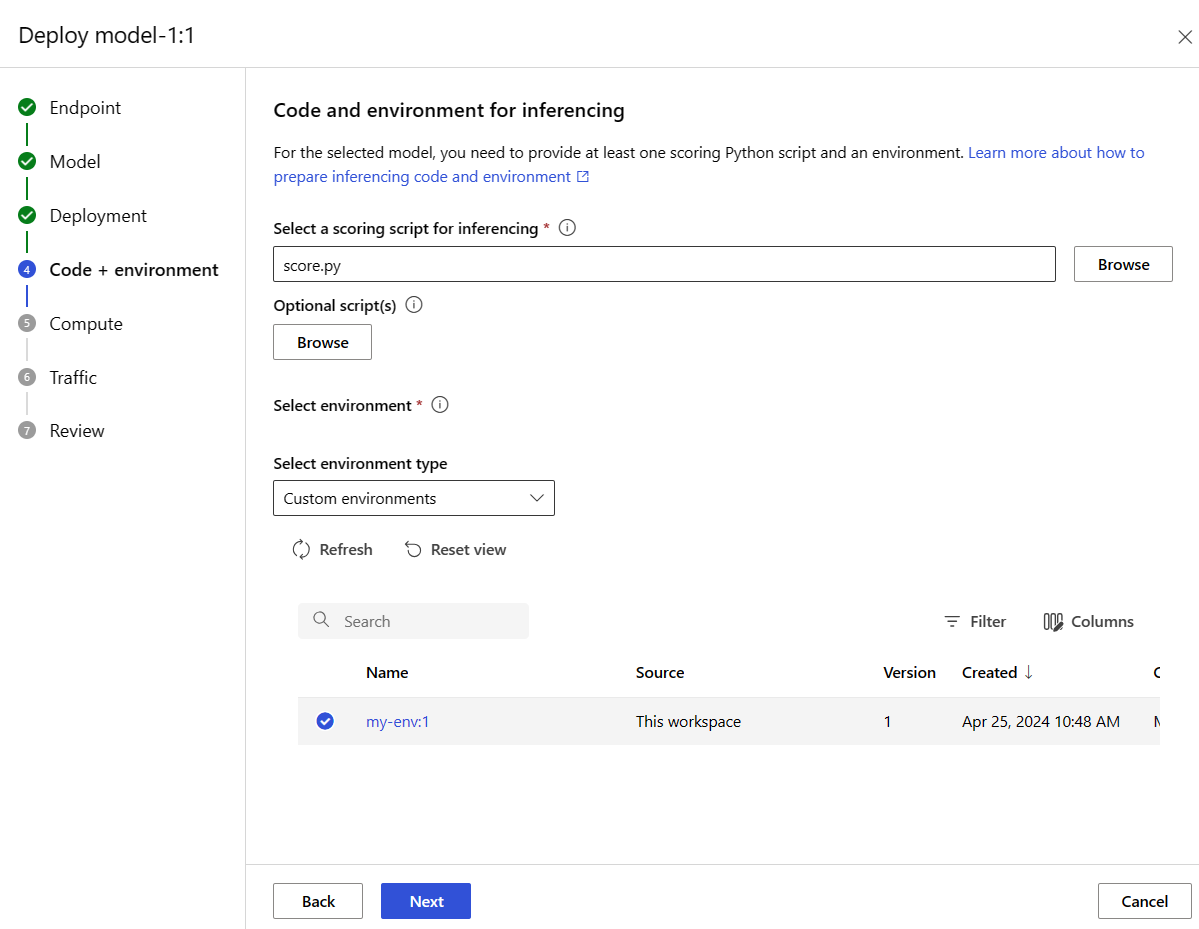
다음을 선택하고 배포를 만들라는 메시지가 표시될 때까지 기본값을 적용합니다.
배포 설정을 검토하고 만들기를 선택합니다.
또는 스튜디오의 엔드포인트 페이지에서 관리되는 온라인 엔드포인트 를 만들 수 있습니다.
Azure Machine Learning 스튜디오로 이동합니다.
왼쪽 창에서 엔드포인트 페이지를 선택합니다.
+만들기를 선택합니다.

이 작업을 수행하면 모델을 선택하고 엔드포인트 및 배포에 대한 세부 정보를 지정할 수 있는 창이 열립니다. 앞에서 설명한 대로 엔드포인트 및 배포에 대한 설정을 입력한 다음 만들기 를 선택하여 배포를 만듭니다.
템플릿을 사용하여 온라인 엔드포인트를 만듭니다.
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
___location=$LOCATION
엔드포인트를 만든 후 엔드포인트에 모델을 배포합니다.
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
___location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
배포에서 오류를 디버그하려면 온라인 엔드포인트 배포 문제 해결을 참조하세요.
온라인 엔드포인트의 상태 확인
엔드포인트 및 배포에 대한 정보를 show에 표시하려면 provisioning_state 명령을 사용합니다.
az ml online-endpoint show -n $ENDPOINT_NAME
list 명령을 사용하여 작업 영역의 모든 엔드포인트를 테이블 형식으로 나열합니다.
az ml online-endpoint list --output table
모델이 오류 없이 배포되었는지 확인하려면 엔드포인트의 상태를 확인합니다.
ml_client.online_endpoints.get(name=endpoint_name)
list 메서드를 사용하여 작업 영역의 모든 엔드포인트를 테이블 형식으로 나열합니다.
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
이 메서드는 ManagedOnlineEndpoint 엔터티의 목록(반복기)을 반환합니다.
더 많은 매개 변수를 지정하여 자세한 정보를 얻을 수 있습니다. 예를 들어 테이블과 같은 엔드포인트 목록을 출력합니다.
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.___location}\t{endpoint.name}")
관리형 온라인 엔드포인트 보기
엔드포인트 페이지에서 관리되는 모든 온라인 엔드포인트를 볼 수 있습니다 . 엔드포인트의 세부 정보 페이지로 이동하여 엔드포인트 URI, 상태, 테스트 도구, 활동 모니터, 배포 로그 및 샘플 소비 코드와 같은 중요한 정보를 찾습니다.
왼쪽 창에서 엔드포인트를 선택하여 작업 영역의 모든 엔드포인트 목록을 확인합니다.
(선택 사항) 컴퓨팅 형식 에 대한 필터를 만들어 관리 형 컴퓨팅 형식만 표시합니다.
엔드포인트 이름을 선택하여 엔드포인트의 세부 정보 페이지를 봅니다.

템플릿은 리소스를 배포하는 데 유용하지만 리소스를 나열, 표시 또는 호출하는 데 사용할 수는 없습니다. Azure CLI, Python SDK 또는 스튜디오를 사용하여 이러한 작업을 수행합니다. 다음 코드는 Azure CLI를 사용합니다.
명령 show를 사용하여 엔드포인트 및 배포에 있는 provisioning_state 매개 변수로 정보를 표시합니다.
az ml online-endpoint show -n $ENDPOINT_NAME
list 명령을 사용하여 작업 영역의 모든 엔드포인트를 테이블 형식으로 나열합니다.
az ml online-endpoint list --output table
온라인 배포 상태 확인
로그를 확인하여 모델이 오류 없이 배포되었는지 확인합니다.
컨테이너에서 로그 출력을 보려면 다음 CLI 명령을 사용합니다.
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
기본적으로 로그는 유추 서버에서 풀합니다. 스토리지 이니셜라이저 컨테이너에서 로그를 보려면 --container storage-initializer 플래그를 추가합니다. 배포 로그에 대한 자세한 내용은 컨테이너 로그 가져오기를 참조하세요.
get_logs 메서드를 사용하여 로그 출력을 볼 수 있습니다.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
기본적으로 로그는 유추 서버에서 풀합니다. 스토리지 이니셜라이저 컨테이너에서 로그를 보려면 container_type="storage-initializer" 옵션을 추가합니다. 배포 로그에 대한 자세한 내용은 컨테이너 로그 가져오기를 참조하세요.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
로그 출력을 보려면 엔드포인트 페이지에서 로그 탭을 선택합니다. 엔드포인트에 여러 배포가 있는 경우 드롭다운 목록을 사용하여 보려는 로그가 있는 배포를 선택합니다.

기본적으로 로그는 유추 서버에서 풀합니다. 스토리지 이니셜라이저 컨테이너에서 로그를 보려면 Azure CLI 또는 Python SDK를 사용합니다(자세한 내용은 각 탭 참조). 스토리지 이니셜라이저의 로그에는 코드 및 모델 데이터가 컨테이너에 성공적으로 다운로드되었는지 여부에 대한 정보가 포함됩니다. 배포 로그에 대한 자세한 내용은 컨테이너 로그 가져오기를 참조하세요.
템플릿은 리소스를 배포하는 데 유용하지만 리소스를 나열, 표시 또는 호출하는 데 사용할 수는 없습니다. Azure CLI, Python SDK 또는 스튜디오를 사용하여 이러한 작업을 수행합니다. 다음 코드는 Azure CLI를 사용합니다.
컨테이너에서 로그 출력을 보려면 다음 CLI 명령을 사용합니다.
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
기본적으로 로그는 유추 서버에서 풀합니다. 스토리지 이니셜라이저 컨테이너에서 로그를 보려면 --container storage-initializer 플래그를 추가합니다. 배포 로그에 대한 자세한 내용은 컨테이너 로그 가져오기를 참조하세요.
엔드포인트를 호출하여 모델을 사용하여 데이터 채점
선택한 invoke 명령 또는 REST 클라이언트를 사용하여 엔드포인트를 호출하고 일부 데이터를 채점합니다.
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
엔드포인트에 인증하는 데 사용되는 키를 가져옵니다.
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action 및 Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action을 허용하는 사용자 지정 역할에 할당하여 인증 키를 가져올 수 있는 Microsoft Entra 보안 주체를 제어할 수 있습니다. 작업 영역에 대한 권한 부여를 관리하는 방법에 대한 자세한 내용은 Azure Machine Learning 작업 영역에 대한 액세스 관리를 참조하세요.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
curl을 사용하여 데이터 점수를 매깁니다.
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
알림: 인증 자격 증명을 가져오는 데 show 및 get-credentials 명령을 사용합니다. 또한 플래그를 --query 사용하여 필요한 특성만 필터링합니다. 플래그에 대한 --query 자세한 내용은 Azure CLI 명령 출력 쿼리를 참조하세요.
호출 로그를 보려면 get-logs를 다시 실행합니다.
앞에서 만든 매개변수 MLClient를 사용하여 엔드포인트에 대한 핸들을 얻습니다. 그런 다음, 다음 매개 변수와 함께 명령을 사용하여 invoke 엔드포인트를 호출할 수 있습니다.
-
endpoint_name: 엔드포인트의 이름
-
request_file: 요청 데이터가 있는 파일입니다.
-
deployment_name: 엔드포인트에서 테스트할 특정 배포의 이름입니다.
JSON 파일을 사용하여 샘플 요청을 보냅니다.
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
엔드포인트 세부 정보 페이지의 테스트 탭을 사용하여 관리되는 온라인 배포를 테스트합니다. 샘플 입력을 입력하고 결과를 봅니다.
엔드포인트의 세부 정보 페이지에서 테스트 탭을 선택합니다.
드롭다운 목록을 사용하여 테스트할 배포를 선택합니다.
샘플 입력을 입력합니다.
테스트를 선택합니다.

템플릿은 리소스를 배포하는 데 유용하지만 리소스를 나열, 표시 또는 호출하는 데 사용할 수는 없습니다. Azure CLI, Python SDK 또는 스튜디오를 사용하여 이러한 작업을 수행합니다. 다음 코드는 Azure CLI를 사용합니다.
선택한 invoke 명령 또는 REST 클라이언트를 사용하여 엔드포인트를 호출하고 일부 데이터를 채점합니다.
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(선택 사항) 배포 업데이트
코드, 모델 또는 환경을 업데이트하려면 YAML 파일을 업데이트합니다. 그런 다음, 명령을 실행합니다 az ml online-endpoint update .
단일 update 명령에서 다른 모델 설정(예: 코드, 모델 또는 환경)과 함께 인스턴스 수를 업데이트(배포 크기 조정)하는 경우 크기 조정 작업이 먼저 수행됩니다. 다른 업데이트는 다음에 적용됩니다. 프로덕션 환경에서는 이러한 작업을 별도로 수행하는 것이 좋습니다.
update의 작동 방식을 이해하려면 다음을 수행합니다.
온라인/model-1/onlinescoring/score.py 파일을 엽니다.
init() 함수의 마지막 줄을 변경합니다. logging.info("Init complete") 다음에 logging.info("Updated successfully")를 추가합니다.
파일을 저장합니다.
다음 명령을 실행합니다.
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
YAML을 사용한 업데이트는 선언적입니다. 즉, YAML의 변경 내용은 기본 Resource Manager 리소스(엔드포인트 및 배포)에 반영됩니다. 선언적 접근 방식은 GitOps를 용이하게 합니다. 엔드포인트 및 배포에 대한 모든 변경 내용(짝수 instance_count)은 YAML을 통과합니다.
CLI 명령을 사용하여 --set, 예를 들어 update 매개 변수를 사용하면 YAML의 속성을 재정의하거나 YAML 파일에 전달하지 않고 특정 속성을 설정할 수 있습니다. 단일 특성에 --set를 사용하는 것은 개발 및 테스트 시나리오에서 특히 중요합니다. 예를 들어 첫 번째 배포의 instance_count 값을 스케일 업하려면 --set instance_count=2 플래그를 사용하면 됩니다. 그러나 YAML이 업데이트되지 않으므로 이 기술은 GitOps를 용이하게 하지 않습니다.
YAML 파일을 지정하는 것은 필수가 아닙니다 . 예를 들어 특정 배포에 대해 다른 동시성 설정을 테스트하려는 경우 다음과 같이 az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4시도할 수 있습니다. 이 방법은 모든 기존 구성을 유지하지만 지정된 매개 변수만 업데이트합니다.
엔드포인트를 init() 만들거나 업데이트할 때 실행되는 함수를 수정했기 때문에 메시지가 Updated successfully 로그에 나타납니다. 다음을 실행하여 로그를 검색합니다.
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
update 명령은 로컬 배포에서도 작동합니다. 동일한 az ml online-deployment update 명령에 --local 플래그를 사용합니다.
코드, 모델 또는 환경을 업데이트하려면 구성을 업데이트한 다음 ' MLClient 메서드를 online_deployments.begin_create_or_update실행하여 배포를 만들거나 업데이트합니다.
단일 begin_create_or_update 메서드에서 다른 모델 설정(예: 코드, 모델 또는 환경)과 함께 인스턴스 수를 업데이트(배포 크기 조정)하는 경우 크기 조정 작업이 먼저 수행됩니다. 그런 다음 다른 업데이트가 적용됩니다. 프로덕션 환경에서는 이러한 작업을 별도로 수행하는 것이 좋습니다.
begin_create_or_update의 작동 방식을 이해하려면 다음을 수행합니다.
온라인/model-1/onlinescoring/score.py 파일을 엽니다.
init() 함수의 마지막 줄을 변경합니다. logging.info("Init complete") 다음에 logging.info("Updated successfully")를 추가합니다.
파일을 저장합니다.
다음과 같이 메서드를 실행합니다.
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
엔드포인트를 init() 만들거나 업데이트할 때 실행되는 함수를 수정했기 때문에 메시지가 Updated successfully 로그에 나타납니다. 다음을 실행하여 로그를 검색합니다.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
begin_create_or_update 메서드는 로컬 배포에서도 작동합니다.
local=True 플래그와 함께 동일한 메서드를 사용합니다.
현재 배포의 인스턴스 수만 업데이트할 수 있습니다. 다음 지침에 따라 인스턴스 수를 조정하여 개별 배포를 스케일 업 또는 다운합니다.
- 엔드포인트의 세부 정보 페이지를 열고 업데이트하려는 배포용 카드를 찾습니다.
- 배포 이름 옆에 있는 편집 아이콘(연필 아이콘)을 선택합니다.
- 배포와 연결된 인스턴스 수를 업데이트합니다.
배포 크기 조정 유형에 대한 기본 또는 대상 사용률 중에서 선택합니다.
-
기본값을 선택하는 경우 인스턴스 수에 대한 숫자 값을 지정할 수도 있습니다.
-
대상 사용률을 선택하는 경우 배포를 자동 크기 조정할 때 매개 변수에 사용할 값을 지정할 수 있습니다.
-
업데이트를 선택하여 배포에 대한 인스턴스 수 업데이트를 완료합니다.
현재 ARM 템플릿을 사용하여 배포를 업데이트하는 옵션은 없습니다.
참고 항목
이 섹션의 배포 업데이트는 현재 위치 롤링 업데이트의 예입니다.
- 관리형 온라인 엔드포인트의 경우 한 번에 20개의% 노드를 사용하여 배포가 새 구성으로 업데이트됩니다. 즉, 배포에 10개의 노드가 있으면 한 번에 2개의 노드가 업데이트됩니다.
- Kubernetes 온라인 엔드포인트의 경우 시스템은 새 구성으로 새 배포 인스턴스를 반복적으로 만들고 이전 인스턴스를 삭제합니다.
- 프로덕션 사용의 경우 웹 서비스를 업데이트하기 위한 보다 안전한 대안을 제공하는 청록색 배포를 고려합니다.
자동 크기 조정은 애플리케이션의 로드를 처리하기 위해 적절한 양의 리소스를 자동으로 실행합니다. 관리형 온라인 엔드포인트는 Azure Monitor 자동 크기 조정 기능과의 통합을 통해 자동 크기 조정을 지원합니다. 자동 크기 조정을 구성하려면 온라인 엔드포인트 자동 크기 조정을 참조하세요.
(선택 사항) Azure Monitor를 사용하여 SLA 모니터링
메트릭을 보고 SLA를 기반으로 경고를 설정하려면 Monitor 온라인 엔드포인트에 설명된 단계를 따릅니다.
(선택 사항) Log Analytics와 통합
get-logs CLI 또는 get_logs SDK 메서드에 대한 명령은 자동으로 선택된 인스턴스의 마지막 수백 줄의 로그만 제공합니다. 그러나 Log Analytics는 지속적으로 로그를 저장하고 분석하는 방법을 제공합니다. 로깅을 사용하는 방법에 대한 자세한 내용은 로그 사용을 참조하세요.
엔드포인트 및 배포 삭제
다음 명령을 사용하여 엔드포인트 및 모든 기본 배포를 삭제합니다.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
다음 명령을 사용하여 엔드포인트 및 모든 기본 배포를 삭제합니다.
ml_client.online_endpoints.begin_delete(name=endpoint_name)
엔드포인트 및 배포를 사용하지 않을 경우 삭제합니다. 엔드포인트를 삭제하면 모든 기본 배포도 삭제됩니다.
-
Azure Machine Learning 스튜디오로 이동합니다.
- 왼쪽 창에서 엔드포인트 페이지를 선택합니다.
- 엔드포인트를 선택합니다.
-
삭제를 선택합니다.
또는 엔드포인트 세부 정보 페이지에서 삭제 아이콘을 선택하여 관리되는 온라인 엔드포인트를 직접 삭제할 수 있습니다.
다음 명령을 사용하여 엔드포인트 및 모든 기본 배포를 삭제합니다.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
관련 콘텐츠









