중요
이 페이지에는 미리 보기 상태인 Kubernetes 배포 매니페스트를 사용하여 Azure IoT 작업 구성 요소를 관리하는 방법에 대한 지침이 포함되어 있습니다. 이 기능은 여러 제한 사항을 가지고 있으므로 프로덕션 워크로드에는 사용하면 안 됩니다.
베타, 미리 보기로 제공되거나 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 약관은 Microsoft Azure 미리 보기에 대한 추가 사용 약관을 참조하세요.
Azure IoT 작업과 Apache Kafka 브로커 간에 양방향 통신을 설정하려면 데이터 흐름 엔드포인트를 구성할 수 있습니다. 이 구성을 사용하면 엔드포인트, TLS(전송 계층 보안), 인증 및 기타 설정을 지정할 수 있습니다.
필수 구성 요소
- Azure IoT 작업의 인스턴스
Azure Event Hubs
Azure Event Hubs는 Kafka 프로토콜과 호환되며 일부 제한 사항이 있는 데이터 흐름과 함께 사용할 수 있습니다.
Azure Event Hubs 네임스페이스 및 이벤트 허브 만들기
먼저, Kafka 지원 Azure Event Hubs 네임스페이스를 만듭니다.
다음으로, 네임스페이스에 이벤트 허브를 만듭니다. 각 이벤트 허브는 Kafka 항목에 해당합니다. 동일한 네임스페이스에 여러 개의 이벤트 허브를 만들어 여러 개의 Kafka 항목을 나타낼 수 있습니다.
관리 ID에 권한 할당
Azure Event Hubs에 대한 데이터 흐름 엔드포인트를 구성하려면 사용자가 할당한 관리 ID나 시스템이 할당한 관리 ID를 사용하는 것이 좋습니다. 이러한 방식은 안전하며 자격 증명을 수동으로 관리할 필요성을 없애줍니다.
Azure Event Hubs 네임스페이스 및 이벤트 허브를 만든 후에는 이벤트 허브에 메시지를 보내거나 받을 수 있는 권한을 부여하는 Azure IoT Operations 관리 ID에 역할을 할당해야 합니다.
시스템이 할당한 관리 ID를 사용하는 경우 Azure Portal에서 Azure IoT 작업 인스턴스로 이동하여 개요를 선택합니다. Azure IoT 작업 Arc 확장 뒤에 나열된 확장 이름을 복사합니다. 예를 들어, azure-iot-operations-xxxx7입니다. 시스템이 할당한 관리 ID는 Azure IoT 작업 Arc 확장과 동일한 이름을 사용하여 찾을 수 있습니다.
그런 다음 Event Hubs 네임스페이스 >액세스 제어(IAM)>역할 할당 추가로 이동합니다.
-
역할 탭에서
Azure Event Hubs Data Sender또는Azure Event Hubs Data Receiver와 같은 적절한 역할을 선택합니다. 이를 통해 관리 ID에 네임스페이스의 모든 이벤트 허브에 대한 메시지를 보내거나 받는 데 필요한 권한이 부여됩니다. 자세한 내용은 Event Hubs 리소스에 액세스하려면 Microsoft Entra ID로 애플리케이션 인증을 참조하세요. -
멤버 탭에서:
- 시스템이 할당한 관리 ID를 사용하는 경우 액세스 권한 할당에서 사용자, 그룹 또는 서비스 주체 옵션을 선택한 다음 + 멤버 선택을 선택하고 Azure IoT 작업 Arc 확장의 이름을 검색합니다.
- 사용자가 할당한 관리 ID를 사용하는 경우 액세스 권한 할당에서 관리 ID 옵션을 선택한 다음 + 멤버 선택을 선택하고 클라우드 연결을 위해 설정된 사용자 할당 관리 ID를 검색합니다.
Azure Event Hubs에 대한 데이터 흐름 엔드포인트 만들기
Azure Event Hubs 네임스페이스 및 이벤트 허브가 구성되면 Kafka 지원 Azure Event Hubs 네임스페이스에 대한 데이터 흐름 엔드포인트를 만들 수 있습니다.
운영 환경에서 데이터 흐름 엔드포인트 탭을 선택합니다.
새 데이터 흐름 엔드포인트 만들기에서 Azure Event Hubs>새로 만들기를 선택합니다.

엔드포인트에 대해 다음 설정을 입력합니다.
설정 설명 이름 데이터 흐름 엔드포인트의 이름입니다. 호스트 Event Hubs 호스트의 호스트 이름입니다. 기존 Event Hubs 호스트를 검색하거나 <NAMESPACE>.servicebus.windows.net형식을 사용하여 호스트 이름을 수동으로 입력할 수 있습니다.항구 Event Hubs 호스트의 포트입니다. Event Hubs의 경우 포트는 9093입니다.인증 방법 인증에 사용되는 방법입니다. 시스템이 할당한 관리 ID 또는 사용자가 할당한 관리 ID를 선택하는 것이 좋습니다. 적용을 선택하여 엔드포인트를 프로비전합니다.
참고
Kafka 항목 또는 개별 이벤트 허브는 나중에 데이터 흐름을 만들 때 구성됩니다. Kafka 항목은 데이터 흐름 메시지의 대상입니다.
Event Hubs 인증을 위해 연결 문자열을 사용합니다.
중요
운영 환경 웹 UI를 사용하여 비밀을 관리하려면 먼저 Azure Key Vault를 구성하고 워크로드 ID를 사용하도록 설정하여 보안 설정으로 Azure IoT 작업을 사용하도록 설정해야 합니다. 자세한 내용은 Azure IoT 작업 배포에서 보안 설정 사용을 참조하세요.
작업 환경 데이터 흐름 엔드포인트 설정 페이지에서 기본 탭을 선택한 다음 인증 방법>SASL을 선택합니다.
엔드포인트에 대해 다음 설정을 입력합니다.
| 설정 | 설명 |
|---|---|
| SASL 형식 |
Plain을 선택합니다. |
| 동기화된 비밀 이름 | 연결 문자열이 포함된 Kubernetes 비밀의 이름을 입력합니다. |
| 사용자 이름 참조 또는 토큰 비밀 | SASL 인증에 사용되는 사용자 이름 또는 토큰 비밀에 대한 참조입니다. Key Vault 목록에서 선택하거나 새로 만듭니다. 값은 $ConnectionString이어야 합니다. |
| 토큰 비밀의 암호 참조 | SASL 인증에 사용되는 암호 또는 토큰 비밀에 대한 참조입니다. Key Vault 목록에서 선택하거나 새로 만듭니다. 값은 Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY> 형식이어야 합니다. |
참조 추가를 선택한 후 새로 만들기를 선택한 경우 다음 설정을 입력합니다.
| 설정 | 설명 |
|---|---|
| 비밀 이름 | Azure Key Vault의 비밀 이름입니다. 나중에 목록에서 비밀을 선택할 때 기억하기 쉬운 이름을 선택합니다. |
| 비밀 값 | 사용자 이름에 $ConnectionString을 입력합니다. 암호의 경우 Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY> 형식으로 연결 문자열을 입력합니다. |
| 활성화 날짜 설정 | 켜져 있는 경우, 비밀이 활성화되는 날짜입니다. |
| 만료 날짜 설정 | 켜져 있는 경우, 비밀이 만료되는 날짜입니다. |
비밀에 대해 자세히 알아보려면 Azure IoT 작업에서 비밀 만들기 및 관리를 참조하세요.
제한 사항
Azure Event Hubs는 Kafka가 지원하는 모든 압축 형식을 지원하지 않습니다. 현재 Azure Event Hubs 프리미엄 및 전용 계층에서는 GZIP 압축만 지원됩니다. 다른 압축 형식을 사용하면 오류가 발생할 수 있습니다.
사용자 지정 Kafka 브로커
이벤트 허브가 아닌 Kafka 브로커에 대한 데이터 흐름 엔드포인트를 구성하려면 필요에 따라 호스트, TLS, 인증 및 기타 설정을 지정합니다.
운영 환경에서 데이터 흐름 엔드포인트 탭을 선택합니다.
새 데이터 흐름 엔드포인트 만들기에서 사용자 지정 Kafka 브로커>새로 만들기를 선택합니다.
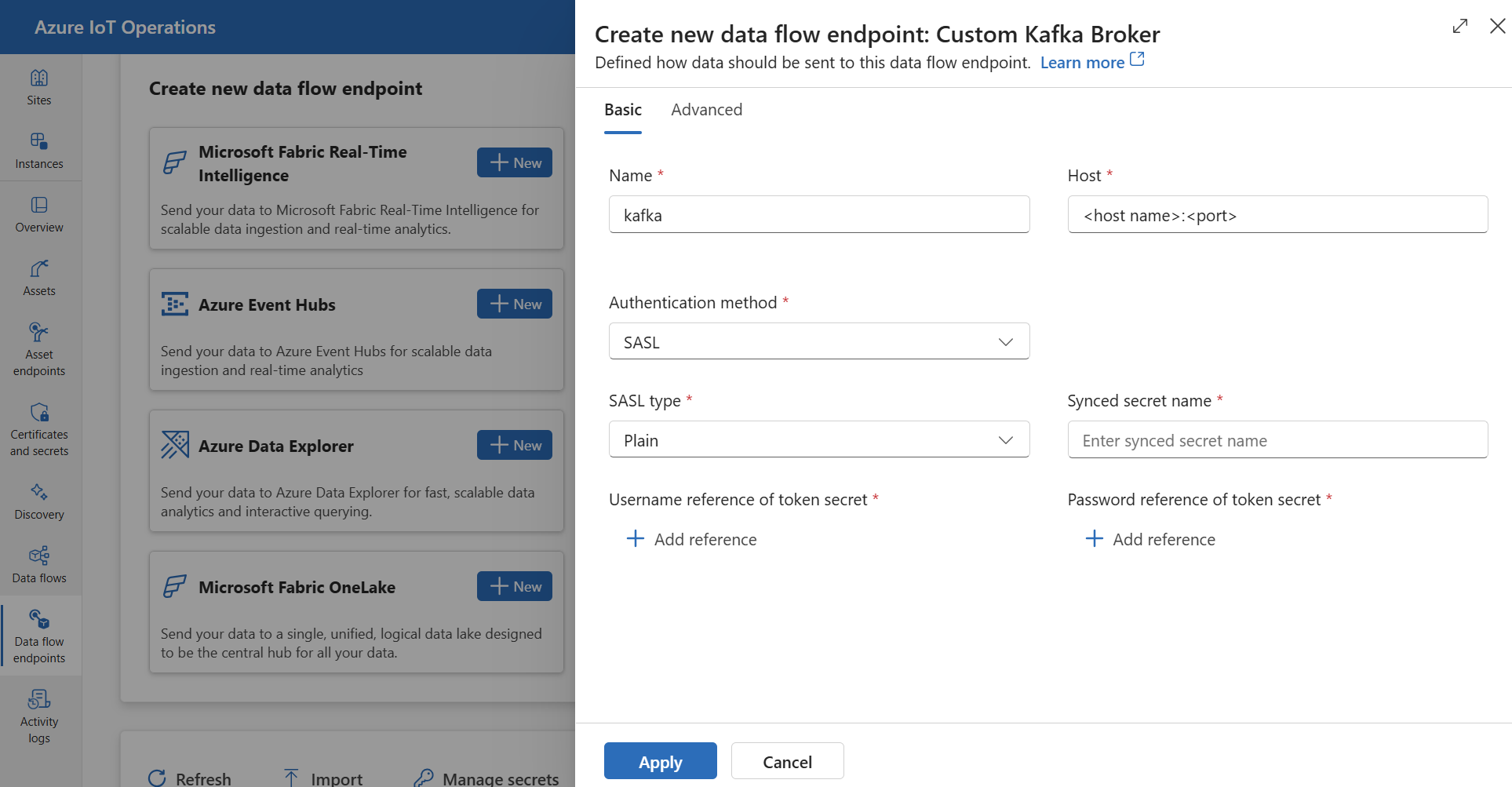
엔드포인트에 대해 다음 설정을 입력합니다.
설정 설명 이름 데이터 흐름 엔드포인트의 이름입니다. 호스트 <Kafka-broker-host>:xxxx형식의 Kafka 브로커의 호스트 이름입니다. 호스트 설정에 포트 번호를 포함합니다.인증 방법 인증에 사용되는 방법입니다. SASL을 선택합니다. SASL 형식 SASL 인증 형식입니다. Plain, ScramSha256 또는 ScramSha512를 선택합니다. SASL을 사용하는 경우 필요합니다. 동기화된 비밀 이름 비밀의 이름입니다. SASL을 사용하는 경우 필요합니다. 토큰 비밀의 사용자 이름 참조 SASL 토큰 비밀의 사용자 이름에 대한 참조입니다. SASL을 사용하는 경우 필요합니다. 적용을 선택하여 엔드포인트를 프로비전합니다.
참고
현재 운영 환경에서는 Kafka 데이터 흐름 엔드포인트를 원본으로 사용하는 것이 지원되지 않습니다. Kubernetes 또는 Bicep을 사용하여 원본 Kafka 데이터 흐름 엔드포인트로 데이터 흐름을 만들 수 있습니다.
엔드포인트 설정을 사용자 지정하려면 다음 섹션에서 자세한 내용을 확인합니다.
사용 가능한 인증 방법
다음 인증 방법은 Kafka 브로커 데이터 흐름 엔드포인트에 사용할 수 있습니다.
시스템 할당 관리 ID
데이터 흐름 엔드포인트를 구성하기 전에 Kafka 브로커에 연결할 수 있는 권한을 부여하는 Azure IoT 작업 관리 ID에 역할을 할당합니다.
- Azure Portal에서 Azure IoT 작업 인스턴스로 이동하여 개요를 선택합니다.
- Azure IoT 작업 Arc 확장 뒤에 나열된 확장 이름을 복사합니다. 예를 들어, azure-iot-operations-xxxx7입니다.
- 권한을 부여해야 하는 클라우드 리소스로 이동합니다. 예를 들어, Event Hubs 네임스페이스 >액세스 제어(IAM)>역할 할당 추가로 이동합니다.
- 역할 탭에서 적절한 역할을 선택합니다.
- 멤버 탭에서 액세스 권한 할당에 대해 사용자, 그룹 또는 서비스 주체 옵션을 선택한 다음 + 멤버 선택을 선택하고 Azure IoT 작업 관리 ID를 검색합니다. 예를 들어, azure-iot-operations-xxxx7입니다.
그런 다음 시스템이 할당한 관리 ID 설정으로 데이터 흐름 엔드포인트를 구성합니다.
운영 환경 데이터 흐름 엔드포인트 설정 페이지에서 기본 탭을 선택한 다음 인증 방법>시스템이 할당한 관리 ID를 선택합니다.
이 구성은 https://<NAMESPACE>.servicebus.windows.net 형식의 Event Hubs 네임스페이스 호스트 값과 동일한 기본 대상 그룹을 사용하여 관리 ID를 만듭니다. 하지만 기본 대상 그룹을 재정의해야 하는 경우 audience 필드를 원하는 값으로 설정할 수 있습니다.
운영 환경에서 지원되지 않습니다.
사용자 할당 관리 ID
사용자가 할당한 관리 ID를 인증에 사용하려면 먼저 보안 설정을 사용하도록 설정하여 Azure IoT 작업을 배포해야 합니다. 그런 다음 클라우드 연결을 위한 사용자 할당 관리 ID를 설정해야 합니다. 자세한 내용은 Azure IoT 작업 배포에서 보안 설정 사용을 참조하세요.
데이터 흐름 엔드포인트를 구성하기 전에 Kafka 브로커에 연결할 수 있는 권한을 부여하는 역할을 사용자가 할당한 관리 ID에 할당합니다.
- Azure Portal에서 권한을 부여해야 하는 클라우드 리소스로 이동합니다. 예를 들어, Event Grid 네임스페이스 >액세스 제어(IAM)>역할 할당 추가로 이동합니다.
- 역할 탭에서 적절한 역할을 선택합니다.
- 멤버 탭에서 액세스 권한 할당에 대해 관리 ID 옵션을 선택한 다음 +멤버 선택을 선택하고 사용자가 할당한 관리 ID를 검색합니다.
그런 다음 사용자가 할당한 관리 ID 설정으로 데이터 흐름 엔드포인트를 구성합니다.
운영 환경 데이터 흐름 엔드포인트 설정 페이지에서 기본 탭을 선택한 다음 인증 방법>사용자가 할당한 관리 ID를 선택합니다.
여기서 범위는 관리 ID의 대상 그룹입니다. 기본값은 https://<NAMESPACE>.servicebus.windows.net 형식의 Event Hubs 네임스페이스 호스트 값과 동일합니다. 하지만 기본 대상 그룹을 재정의해야 하는 경우 Bicep이나 Kubernetes를 사용하여 범위 필드를 원하는 값으로 설정할 수 있습니다.
SASL
인증에 SASL을 사용하려면 SASL 인증 방법을 지정하고 SASL 형식과 SASL 토큰이 포함된 비밀 이름으로 비밀 참조를 구성합니다.
작업 환경 데이터 흐름 엔드포인트 설정 페이지에서 기본 탭을 선택한 다음 인증 방법>SASL을 선택합니다.
엔드포인트에 대해 다음 설정을 입력합니다.
| 설정 | 설명 |
|---|---|
| SASL 형식 | 사용할 SASL 인증 형식입니다. 지원되는 형식은 Plain, ScramSha256 및 ScramSha512입니다. |
| 동기화된 비밀 이름 | SASL 토큰을 포함하는 Kubernetes 비밀의 이름입니다. |
| 사용자 이름 참조 또는 토큰 비밀 | SASL 인증에 사용되는 사용자 이름 또는 토큰 비밀에 대한 참조입니다. |
| 토큰 비밀의 암호 참조 | SASL 인증에 사용되는 암호 또는 토큰 비밀에 대한 참조입니다. |
지원되는 SASL 형식은 다음과 같습니다.
PlainScramSha256ScramSha512
비밀은 Kafka 데이터 흐름 엔드포인트와 동일한 네임스페이스에 있어야 합니다. 비밀에는 SASL 토큰이 키-값 쌍으로 포함되어야 합니다.
익명
익명 인증을 사용하려면 Kafka 설정의 인증 섹션을 업데이트하여 무명 메서드를 사용해야 합니다.
작업 환경 데이터 흐름 엔드포인트 설정 페이지에서 기본 탭을 선택한 다음 인증 방법>없음을 선택합니다.
고급 설정
TLS, 신뢰할 수 있는 CA 인증서, Kafka 메시징 설정, 일괄 처리, CloudEvents와 같은 Kafka 데이터 흐름 엔드포인트에 대한 고급 설정을 지정할 수 있습니다. 이러한 설정은 데이터 흐름 엔드포인트 고급 포털 탭이나 데이터 흐름 엔드포인트 리소스 내에서 설정할 수 있습니다.
운영 환경에서 데이터 흐름 엔드포인트에 대한 고급 탭을 선택합니다.

TLS 설정
TLS 모드
Kafka 엔드포인트에 대해 TLS를 사용하거나 사용하지 않도록 설정하려면 TLS 설정에서 mode 설정을 업데이트합니다.
운영 환경 데이터 흐름 엔드포인트 설정 페이지에서 고급 탭을 선택한 다음 TLS 모드 사용 옆에 있는 확인란을 사용합니다.
TLS 모드는 Enabled 또는 Disabled로 설정할 수 있습니다. 모드가 Enabled로 설정된 경우 데이터 흐름은 Kafka 브로커에 대한 보안 연결을 사용합니다. 모드가 Disabled로 설정된 경우 데이터 흐름은 Kafka 브로커에 대한 안전하지 않은 연결을 사용합니다.
신뢰할 수 있는 CA 인증서
Kafka 브로커에 대한 보안 연결을 설정하려면 Kafka 엔드포인트에 대한 신뢰할 수 있는 CA 인증서를 구성합니다. Kafka 브로커가 자체 서명된 인증서나 기본적으로 신뢰할 수 있는 사용자 지정 CA가 서명한 인증서를 사용하는 경우 이 설정이 중요합니다.
작업 환경 데이터 흐름 엔드포인트 설정 페이지에서 고급 탭을 선택한 다음 신뢰할 수 있는 CA 인증서 구성 맵 필드를 사용하여 신뢰할 수 있는 CA 인증서가 포함된 ConfigMap을 지정합니다.
이 ConfigMap에는 PEM 형식의 CA 인증서가 포함되어야 합니다. ConfigMap은 Kafka 데이터 흐름 리소스와 같은 네임스페이스에 있어야 합니다. 예를 들면 다음과 같습니다.
kubectl create configmap client-ca-configmap --from-file root_ca.crt -n azure-iot-operations
팁
Azure Event Hubs에 연결할 때 CA 인증서가 필요하지 않습니다. Event Hubs 서비스는 기본적으로 신뢰할 수 있는 공용 CA에서 서명한 인증서를 사용하기 때문입니다.
소비자 그룹 ID
소비자 그룹 ID는 데이터 흐름이 Kafka 항목에서 메시지를 읽는 데 사용하는 소비자 그룹을 식별하는 데 사용됩니다. 소비자 그룹 ID는 Kafka 브로커 내에서 고유해야 합니다.
중요
Kafka 엔드포인트가 원본으로 사용되는 경우 소비자 그룹 ID가 필요합니다. 그렇지 않으면 데이터 흐름은 Kafka 항목에서 메시지를 읽을 수 없으며 "Kafka 형식 원본 엔드포인트에는 consumerGroupId가 정의되어 있어야 합니다"라는 오류가 발생합니다.
운영 환경 데이터 흐름 엔드포인트 설정 페이지에서 고급 탭을 선택한 다음 소비자 그룹 ID 필드를 사용하여 소비자 그룹 ID를 지정합니다.
이 설정은 엔드포인트가 원본으로 사용되는 경우에만 적용됩니다(즉, 데이터 흐름이 소비자인 경우).
압축
압축 필드를 사용하면 Kafka 토픽으로 전송된 메시지에 대한 압축을 사용할 수 있습니다. 압축은 데이터 전송에 필요한 네트워크 대역폭 및 스토리지 공간을 줄이는 데 도움이 됩니다. 그러나 압축은 프로세스에 약간의 오버헤드와 대기 시간도 추가합니다. 지원되는 압축 형식은 다음 표에 열거되어 있습니다.
| 값 | 설명 |
|---|---|
None |
압축 또는 일괄 처리가 적용되지 않습니다. 없음은 압축이 지정되지 않은 경우 기본값입니다. |
Gzip |
GZIP 압축 및 일괄 처리가 적용됩니다. GZIP은 압축 비율과 속도 간에 적절한 균형을 제공하는 범용 압축 알고리즘입니다. 현재 Azure Event Hubs 프리미엄 및 전용 계층에서는 GZIP 압축만 지원됩니다. |
Snappy |
Snappy 압축 및 일괄 처리가 적용됩니다. Snappy는 적당한 압축 비율과 속도를 제공하는 빠른 압축 알고리즘입니다. 이 압축 모드는 Azure Event Hubs에서 지원되지 않습니다. |
Lz4 |
LZ4 압축 및 일괄 처리가 적용됩니다. LZ4는 낮은 압축 비율과 고속을 제공하는 빠른 압축 알고리즘입니다. 이 압축 모드는 Azure Event Hubs에서 지원되지 않습니다. |
압축을 구성하려면:
작업 환경 데이터 흐름 엔드포인트 설정 페이지에서 고급 탭을 선택한 다음 압축 필드를 사용하여 압축 형식을 지정합니다.
이 설정은 엔드포인트가 데이터 흐름이 생산자인 대상으로 사용되는 경우에만 적용됩니다.
일괄 처리
압축 외에도 메시지를 Kafka 토픽으로 보내기 전에 메시지에 대한 일괄 처리를 구성할 수도 있습니다. 일괄 처리를 사용하면 여러 메시지를 함께 그룹화하고 단일 단위로 압축하여 압축 효율성을 높이고 네트워크 오버헤드를 줄일 수 있습니다.
| 필드 | 설명 | 필수 |
|---|---|---|
mode |
Enabled 또는 Disabled일 수 있습니다. Kafka에는 Enabled 메시징 개념이 없으므로 기본값은 입니다.
Disabled로 설정하면 일괄 처리가 최소화되어 매번 단일 메시지로 일괄 처리가 만들어집니다. |
아니요 |
latencyMs |
메시지를 보내기 전에 버퍼링할 수 있는 최대 시간 간격(밀리초)입니다. 이 간격에 도달하면 버퍼링된 모든 메시지는 개수나 크기에 상관 없이, 일괄 처리로 전송됩니다. 설정하지 않으면 기본값은 5입니다. | 아니요 |
maxMessages |
메시지를 보내기 전에 버퍼링할 수 있는 최대 메시지 수입니다. 이 숫자에 도달하면 버퍼링된 모든 메시지가 크기나 버퍼링 기간에 관계없이 일괄 처리로 전송됩니다. 설정하지 않으면 기본값은 100000입니다. | 아니요 |
maxBytes |
전송되기 전에 버퍼링할 수 있는 최대 크기(바이트)입니다. 이 크기에 도달하면 버퍼링된 모든 메시지가 버퍼링된 수나 기간에 관계없이 일괄 처리로 전송됩니다. 기본값은 1000000(1MB)입니다. | 아니요 |
예를 들어, latencyMs를 1000으로, maxMessages를 100으로, maxBytes를 1024로 설정하면 버퍼에 메시지가 100개 있거나, 버퍼에 1,024바이트가 있거나, 마지막 전송 이후 1,000밀리초가 경과했을 때 메시지가 전송됩니다.
일괄 처리를 구성하려면:
작업 환경 데이터 흐름 엔드포인트 설정 페이지에서 고급 탭을 선택한 다음 일괄 처리 사용 필드를 사용하여 일괄 처리를 사용하도록 설정합니다. 일괄 처리 대기 시간, 최대 바이트 및 메시지 수 필드를 사용하여 일괄 처리 설정을 지정합니다.
이 설정은 엔드포인트가 데이터 흐름이 생산자인 대상으로 사용되는 경우에만 적용됩니다.
파티션 처리 전략
파티션 처리 전략은 메시지를 Kafka 항목으로 보낼 때 메시지가 Kafka 파티션에 어떻게 할당되는지 제어합니다. Kafka 파티션은 병렬 처리 및 내결함성을 가능하게 하는 Kafka 토픽의 논리적 세그먼트입니다. Kafka 항목의 각 메시지에는 파티션과 오프셋이 있으며, 이는 메시지를 식별하고 정렬하는 데 사용됩니다.
이 설정은 엔드포인트가 데이터 흐름이 생산자인 대상으로 사용되는 경우에만 적용됩니다.
기본적으로 데이터 흐름은 라운드 로빈 알고리즘을 사용하여 메시지를 임의의 파티션에 할당합니다. 그러나 MQTT 토픽 이름 또는 MQTT 메시지 속성과 같은 몇 가지 기준에 따라 다른 전략을 사용하여 파티션에 메시지를 할당할 수 있습니다. 이렇게 하면 부하 분산, 데이터 위치 또는 메시지 순서 지정을 향상할 수 있습니다.
| 값 | 설명 |
|---|---|
Default |
라운드 로빈 알고리즘을 사용하여 임의 파티션에 메시지를 할당합니다. 전략이 지정되지 않은 경우 이는 기본값입니다. |
Static |
데이터 흐름의 인스턴스 ID에서 파생된 고정 파티션 번호에 메시지를 할당합니다. 이는 각 데이터 흐름 인스턴스가 다른 파티션으로 메시지를 보낸다는 것을 의미합니다. 이것은 부하 분산 및 데이터 위치 향상에 도움이 될 수 있습니다. |
Topic |
데이터 흐름 원본의 MQTT 항목 이름을 분할의 키로 사용합니다. 즉, 동일한 MQTT 토픽 이름을 가진 메시지가 동일한 파티션으로 전송됩니다. 이것은 메시지 정렬 및 데이터 위치 향상에 도움이 될 수 있습니다. |
Property |
데이터 흐름 원본의 MQTT 메시지 속성을 분할의 키로 사용합니다.
partitionKeyProperty 필드에 속성의 이름을 지정합니다. 즉, 속성 값이 같은 메시지가 동일한 파티션으로 전송됩니다. 이것은 사용자 지정 기준에 따라 메시지 정렬 및 데이터 위치 향상에 도움이 될 수 있습니다. |
예를 들어, 파티션 처리 전략을 Property로 설정하고 파티션 키 속성을 device-id로 설정하면 동일한 device-id 속성을 가진 메시지가 동일한 파티션으로 전송됩니다.
파티션 처리 전략을 구성하려면:
작업 환경 데이터 흐름 엔드포인트 설정 페이지에서 고급 탭을 선택한 다음 파티션 처리 전략 필드를 사용하여 파티션 처리 전략을 지정합니다. 전략이 로 설정된 경우 분할에 사용되는 속성을 지정하려면 Property 필드를 사용합니다.
Kafka 승인
Kafka 승인(ack)은 Kafka 항목에 전송된 메시지의 내구성과 일관성을 제어하는 데 사용됩니다. 프로듀서가 Kafka 항목에 메시지를 보낼 때, Kafka 브로커에 다양한 수준의 승인을 요청하여 메시지가 항목에 성공적으로 기록되고 Kafka 클러스터 전체에 복제되었는지 승인할 수 있습니다.
이 설정은 엔드포인트가 대상으로 사용되는 경우에만 적용됩니다(즉, 데이터 흐름이 생산자임).
| 값 | 설명 |
|---|---|
None |
데이터 흐름은 Kafka 브로커의 승인을 기다리지 않습니다. 이 설정은 가장 빠르지만 가장 내구성이 낮은 옵션입니다. |
All |
데이터 흐름은 메시지가 리더 파티션과 모든 팔로워 파티션에 기록될 때까지 기다립니다. 이 설정은 가장 느리지만 가장 내구성이 뛰어난 옵션입니다. 이 설정은 기본 옵션이기도 합니다. |
One |
데이터 흐름은 메시지가 리더 파티션과 최소한 하나의 팔로워 파티션에 기록될 때까지 기다립니다. |
Zero |
데이터 흐름은 메시지가 리더 파티션에 기록될 때까지 기다리지만 팔로워로부터 승인을 기다리지 않습니다.
One보다 빠르지만 내구성이 떨어집니다. |
예를 들어, Kafka 승인을 All로 설정하면 데이터 흐름은 다음 메시지를 보내기 전에 메시지가 리더 파티션과 모든 팔로워 파티션에 기록될 때까지 기다립니다.
Kafka 승인을 구성하려면:
작업 환경 데이터 흐름 엔드포인트 설정 페이지에서 고급 탭을 선택한 다음 Kafka 승인 필드를 사용하여 Kafka 승인 수준을 지정합니다.
이 설정은 엔드포인트가 데이터 흐름이 생산자인 대상으로 사용되는 경우에만 적용됩니다.
MQTT 속성 복사
기본적으로 MQTT 속성 복사 설정은 사용하도록 설정되어 있습니다. 이러한 사용자 속성에는 메시지를 보내는 자산의 이름을 저장하는 subject 같은 값이 포함됩니다.
작업 환경 데이터 흐름 엔드포인트 설정 페이지에서 고급 탭을 선택한 다음 MQTT 속성 복사 필드 옆에 있는 확인란을 사용하여 MQTT 속성 복사를 사용하거나 사용하지 않도록 설정합니다.
다음 섹션에서는 해당 설정이 사용하도록 설정된 경우 MQTT 속성이 Kafka 사용자 헤더로 변환되는 방식과 그 반대의 방식을 설명합니다.
Kafka 엔드포인트가 대상임
Kafka 엔드포인트가 데이터 흐름 대상인 경우 MQTT v5 사양에 정의된 모든 속성은 Kafka 사용자 헤더로 변환됩니다. 예를 들어, "콘텐츠 형식"이 포함된 MQTT v5 메시지가 Kafka로 전달되면 Kafka 사용자 헤더"Content Type":{specifiedValue}로 변환됩니다. 다음 표에 정의된 다른 기본 제공 MQTT 속성에도 비슷한 규칙이 적용됩니다.
| MQTT 속성 | 번역된 동작 |
|---|---|
| 페이로드 형식 표시기 | 키: "페이로드 형식 표시기" 값: "0"(페이로드가 바이트) 또는 "1"(페이로드가 UTF-8) |
| 응답 토픽. | 키: "응답 항목" 값: 원본 메시지의 응답 항목 복사본입니다. |
| 메시지 만료 간격 | 키: "메시지 만료 간격" 값: 메시지가 만료되기 전의 시간(초)을 UTF-8로 표현한 값입니다. 자세한 내용은 메시지 만료 간격 속성을 참조하세요. |
| 상관 관계 데이터: | 키: "상관 관계 데이터" 값: 원본 메시지의 상관 관계 데이터 복사본입니다. UTF-8로 인코딩된 많은 MQTT v5 속성과 달리 상관 관계 데이터는 임의의 데이터일 수 있습니다. |
| 콘텐츠 형식: | 키: "콘텐츠 형식" 값: 원본 메시지의 콘텐츠 형식 복사본입니다. |
MQTT v5 사용자 속성 키 값 쌍은 Kafka 사용자 헤더로 직접 변환됩니다. 메시지의 사용자 헤더가 기본 제공 MQTT 속성과 동일한 이름을 가지고 있는 경우(예: "상관 관계 데이터"라는 이름의 사용자 헤더) MQTT v5 사양 속성 값을 전달할지 아니면 사용자 속성을 전달할지는 정의되지 않습니다.
데이터 흐름은 MQTT 브로커로부터 이러한 속성을 수신하지 않습니다. 따라서 데이터 흐름은 결코 이를 전달하지 않습니다.
- 항목 별칭
- 구독 식별자
메시지 만료 간격 속성
메시지 만료 간격은 메시지가 취소되기 전에 MQTT 브로커에 남아 있을 수 있는 시간을 지정합니다.
데이터 흐름이 메시지 만료 간격이 지정된 MQTT 메시지를 수신하는 경우 다음을 수행합니다.
- 메시지가 수신된 시간을 기록합니다.
- 메시지가 대상에 전송되기 전에, 메시지가 대기한 시간에서 원래 만료 간격 시간만큼 시간이 빼집니다.
- 메시지가 만료되지 않은 경우(위의 연산은 > 0) 메시지는 대상에 전송되고 업데이트된 메시지 만료 시간이 포함됩니다.
- 메시지가 만료된 경우(위의 연산이 <= 0인 경우) 해당 메시지는 대상에서 방출되지 않습니다.
예제:
- 데이터 흐름은 메시지 만료 간격이 3600초인 MQTT 메시지를 수신합니다. 해당 대상의 연결이 일시적으로 끊어졌지만 다시 연결할 수 있습니다. 이 MQTT 메시지가 대상에 전송되기까지 1,000초가 걸립니다. 이 경우 대상 메시지의 메시지 만료 간격은 2600(3600 - 1000)초로 설정됩니다.
- 데이터 흐름은 메시지 만료 간격 = 3600초인 MQTT 메시지를 수신합니다. 해당 대상의 연결이 일시적으로 끊어졌지만 다시 연결할 수 있습니다. 하지만 이 경우 다시 연결하는 데 4,000초가 걸립니다. 메시지가 만료되어 데이터 흐름이 이 메시지를 대상에 전달하지 않습니다.
Kafka 엔드포인트는 데이터 흐름 원본입니다.
참고
Event Hubs 엔드포인트를 데이터 흐름 원본으로 사용할 경우 Kafka 헤더가 MQTT로 변환될 때 손상되는 알려진 문제가 있습니다. 이는 AMQP를 내부적으로 사용하는 Event Hubs 클라이언트를 통해 Event Hubs를 사용하는 경우에만 발생합니다. 예를 들어, "foo"="bar"의 경우 "foo"는 변환되지만 값은 "\xa1\x03bar"가 됩니다.
Kafka 엔드포인트가 데이터 흐름 원본인 경우 Kafka 사용자 헤더는 MQTT v5 속성으로 변환됩니다. 다음 표에서는 Kafka 사용자 헤더가 MQTT v5 속성으로 변환되는 방식을 설명합니다.
| Kafka 헤더 | 번역된 동작 |
|---|---|
| 키 | 키: "키" 값: 원본 메시지의 키 복사본입니다. |
| 타임스탬프 | 키: "타임스탬프" 값: Kafka 타임스탬프의 UTF-8 인코딩으로, Unix epoch 이후의 밀리초 수입니다. |
Kafka 사용자 헤더 키/값 쌍은 모두 UTF-8로 인코딩되어 있다면 MQTT 사용자 키/값 속성으로 직접 변환됩니다.
UTF-8 / 이진 불일치
MQTT v5는 UTF-8 기반 속성만 지원할 수 있습니다. 데이터 흐름이 하나 이상의 UTF-8이 아닌 헤더를 포함하는 Kafka 메시지를 수신하는 경우 데이터 흐름은 다음을 수행합니다.
- 문제가 있는 속성을 제거합니다.
- 이전 규칙에 따라 나머지 메시지를 전달합니다.
Kafka 원본 헤더에서 이진 전송이 필요한 애플리케이션 => MQTT 대상 속성은 먼저 UTF-8로 인코딩해야 합니다(예: Base64를 통해).
>=64KB 속성 불일치
MQTT v5 속성은 64KB보다 작아야 합니다. 데이터 흐름이 >= 64KB인 하나 이상의 헤더를 포함하는 Kafka 메시지를 수신하는 경우 데이터 흐름은 다음을 수행합니다.
- 문제가 있는 속성을 제거합니다.
- 이전 규칙에 따라 나머지 메시지를 전달합니다.
AMQP를 사용하는 Event Hubs 및 프로듀서를 사용할 때 속성 변환
클라이언트가 Kafka 데이터 흐름 원본 엔드포인트에 메시지를 전달하여 다음 작업 중 하나를 수행하는 경우:
- Azure.Messaging.EventHubs와 같은 클라이언트 라이브러리를 사용하여 Event Hubs에 메시지 보내기
- AMQP 직접 사용
알아두어야 할 속성 번역의 미묘한 차이점이 있습니다.
다음 중 하나를 수행해야 합니다.
- 속성 전송 방지
- 속성을 보내야 하는 경우 UTF-8로 인코딩된 값을 보냅니다.
Event Hubs가 AMQP에서 Kafka로 속성을 변환할 때 메시지에 기본 AMQP 인코딩 형식이 포함됩니다. 동작에 대한 자세한 내용은 다양한 프로토콜을 사용하여 소비자와 생산자 간 이벤트 교환을 참조하세요.
다음 코드 예에서 데이터 흐름 엔드포인트가 값 "foo":"bar"를 수신하면 속성을 <0xA1 0x03 "bar">로 수신합니다.
using global::Azure.Messaging.EventHubs;
using global::Azure.Messaging.EventHubs.Producer;
var propertyEventBody = new BinaryData("payload");
var propertyEventData = new EventData(propertyEventBody)
{
Properties =
{
{"foo", "bar"},
}
};
var propertyEventAdded = eventBatch.TryAdd(propertyEventData);
await producerClient.SendAsync(eventBatch);
데이터가 UTF-8이 아니기 때문에 데이터 흐름 엔드포인트가 페이로드 속성 <0xA1 0x03 "bar">를 MQTT 메시지로 전달할 수 없습니다. 하지만 UTF-8 문자열을 지정하면 데이터 흐름 엔드포인트는 MQTT로 전송하기 전에 문자열을 변환합니다. UTF-8 문자열을 사용하는 경우 MQTT 메시지는 사용자 속성으로 "foo":"bar"를 갖습니다.
UTF-8 헤더만 번역됩니다. 예를 들어, 속성이 float로 설정된 다음 시나리오를 살펴보겠습니다.
Properties =
{
{"float-value", 11.9 },
}
데이터 흐름 엔드포인트는 "float-value" 필드가 포함된 패킷을 취소합니다.
propertyEventData.correlationId를 포함한 모든 이벤트 데이터 속성이 전달되는 것은 아닙니다. 자세한 내용은 이벤트 사용자 속성을 참조하세요.
CloudEvents
CloudEvents는 이벤트 데이터를 일반적인 방식으로 설명하는 방법입니다. CloudEvents 설정은 CloudEvents 형식으로 메시지를 보내거나 받는 데 사용됩니다. 서로 다른 서비스가 동일하거나 다른 클라우드 공급자 내에서 서로 통신해야 하는 이벤트 기반 아키텍처에 CloudEvents를 사용할 수 있습니다.
CloudEventAttributes 옵션은 Propagate 또는 CreateOrRemap입니다.
운영 환경 데이터 흐름 엔드포인트 설정 페이지에서 고급 탭을 선택한 다음 클라우드 이벤트 특성 필드를 사용하여 CloudEvents 설정을 지정합니다.
다음 섹션에서는 CloudEvent 속성이 전파되거나 만들어져 다시 매핑되는 방식을 설명합니다.
전파 설정
CloudEvent 속성은 필요한 속성이 포함된 메시지에 대해 전달됩니다. 메시지에 필요한 속성이 포함되어 있지 않으면 메시지는 그대로 전달됩니다. 필수 속성이 있는 경우 CloudEvent 속성 이름에 ce_ 접두사가 추가됩니다.
| 이름 | 필수 | 샘플 값 | 출력 이름 | 출력 값 |
|---|---|---|---|---|
specversion |
예 | 1.0 |
ce-specversion |
있는 그대로 전달됨 |
type |
예 | ms.aio.telemetry |
ce-type |
있는 그대로 전달됨 |
source |
예 | aio://mycluster/myoven |
ce-source |
있는 그대로 전달됨 |
id |
예 | A234-1234-1234 |
ce-id |
있는 그대로 전달됨 |
subject |
아니요 | aio/myoven/sensor/temperature |
ce-subject |
있는 그대로 전달됨 |
time |
아니요 | 2018-04-05T17:31:00Z |
ce-time |
있는 그대로 전달됨. 다시 스탬프가 지정되지 않았습니다. |
datacontenttype |
아니요 | application/json |
ce-datacontenttype |
선택적 변환 단계 후에 출력 데이터 콘텐츠 형식으로 변경되었습니다. |
dataschema |
아니요 | sr://fabrikam-schemas/123123123234234234234234#1.0.0 |
ce-dataschema |
변환 구성에 출력 데이터 변환 스키마가 지정된 경우 dataschema가 출력 스키마로 변경됩니다. |
CreateOrRemap 설정
CloudEvent 속성은 필요한 속성이 포함된 메시지에 대해 전달됩니다. 메시지에 필요한 속성이 포함되어 있지 않으면 속성이 생성됩니다.
| 이름 | 필수 | 출력 이름 | 누락된 경우 생성된 값 |
|---|---|---|---|
specversion |
예 | ce-specversion |
1.0 |
type |
예 | ce-type |
ms.aio-dataflow.telemetry |
source |
예 | ce-source |
aio://<target-name> |
id |
예 | ce-id |
대상 클라이언트에서 생성된 UUID |
subject |
아니요 | ce-subject |
메시지가 전송되는 출력 항목 |
time |
아니요 | ce-time |
대상 클라이언트에서 RFC 3339로 생성됨 |
datacontenttype |
아니요 | ce-datacontenttype |
선택적 변환 단계 후 출력 데이터 콘텐츠 형식으로 변경됨 |
dataschema |
아니요 | ce-dataschema |
스키마 레지스트리에 정의된 스키마 |
다음 단계
데이터 흐름에 대해 자세히 알아보려면 데이터 흐름 만들기를 참조하세요.