カスタム テキスト分類スキル
カスタム テキスト分類を使用すると、テキストをさまざまなユーザー定義クラスにマップできます。 たとえば、書籍の裏表紙にあるあらすじでモデルをトレーニングして、書籍のジャンルを自動的に識別できるようにすることができます。 その後、その特定されたジャンルを使用して、オンライン ショップの検索エンジンをジャンル ファセットでエンリッチします。

ここでは、カスタム テキスト分類モデルを使用して検索インデックスを強化するために考慮する必要がある事項を確認します。
- Language Studio と Azure AI 検索インデクサーからアクセスできるようにドキュメントを格納します。
- カスタム テキスト分類プロジェクトを作成する。
- モデルをトレーニングしてテストします。
- 格納されているドキュメントに基づいて検索インデックスを作成します。
- デプロイされたトレーニング済みモデルを使用する関数アプリを作成します。
- 検索ソリューション、インデックス、インデクサー、カスタム スキルセットを更新します。
データの格納
Azure Blob Storage には、Language Studio と Azure AI サービスの両方からアクセスできます。 コンテナーはアクセス可能である必要があるため、最も簡単なオプションは [コンテナー] を選択することですが、追加構成を行ってプライベート コンテナーを使用することもできます。
データに加えて、各ドキュメントに分類を割り当てる方法も必要です。 Language Studio には、各ドキュメントを一度に 1 つずつ手動で分類するために使用できるグラフィカル ツールが用意されています。
2 種類のプロジェクトから選択できます。 ドキュメントが単一のクラスにマップされる場合は、単一のラベル分類プロジェクトを使用します。 ドキュメントを複数のクラスにマップする場合は、マルチ ラベル分類プロジェクトを使用します。
各ドキュメントを手動で分類したくない場合は、Azure AI Language プロジェクトを作成する前にすべてのドキュメントにラベルを付けることができます。 このプロセスでは、JSON ドキュメントで、次の形式でラベルを作成する必要があります。
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"___location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
必要な数のクラスを classes 配列に追加します。 documents 配列で、各ドキュメントのエントリ (ドキュメントが一致するクラスなど) を追加します。
Azure AI Language プロジェクトを作成する
Azure AI Language プロジェクトを作成するには、2 つの方法があります。 最初に Azure portal で言語サービスを作成せずに Language Studio の使用を開始した場合、Language Studio によって、言語サービスの作成が提案されます。
Azure AI Language プロジェクトを作成する最も柔軟な方法は、最初に Azure portal を使用して言語サービスを作成することです。 このオプションを選択すると、カスタム機能を追加するオプションが表示されます。
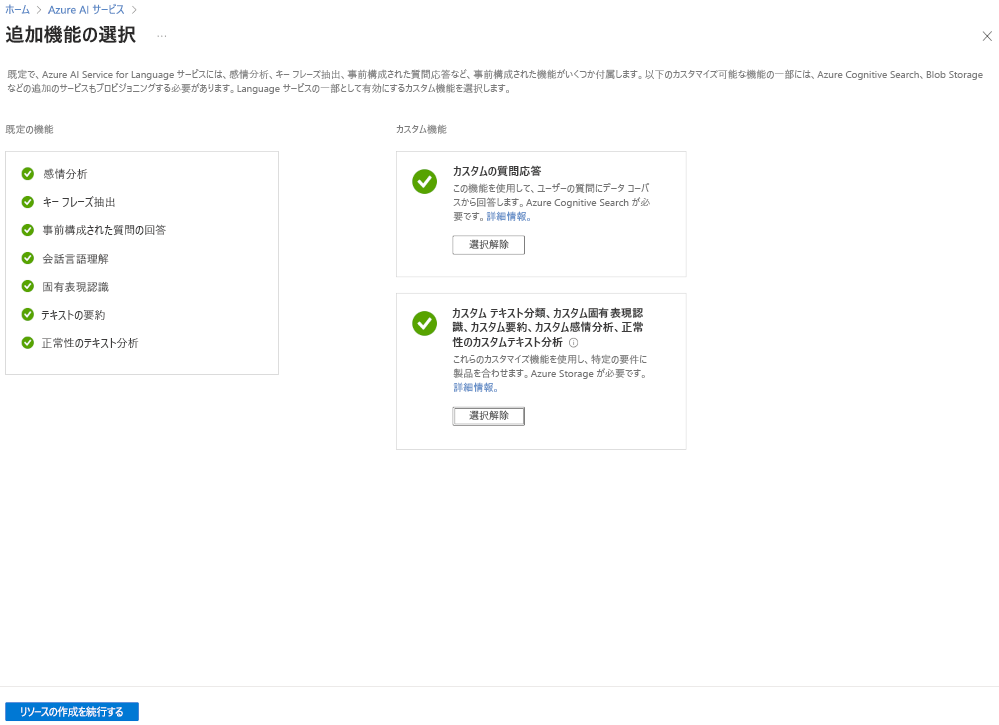
カスタム テキスト分類を作成する場合は、言語サービスの作成時にそのカスタム機能を選択します。 また、この方法を使用して、言語サービスをストレージ アカウントにリンクします。
リソースがデプロイされたら、言語サービスの概要ウィンドウから Language Studio に直接移動できます。 その後、新しいカスタム テキスト分類プロジェクトを作成できます。
Note
Language Studio から言語サービスを作成した場合は、次の手順に従う必要がある可能性があります。 Azure 言語リソースとストレージ アカウントのロールを設定し、ストレージ コンテナーをカスタム テキスト分類プロジェクトに接続します。
分類モデルをトレーニングする
すべての AI モデルと同様に、トレーニングに使用できるデータを特定しておく必要があります。 モデルでは、データをクラスにマップする方法の例を確認する必要があり、モデルのテストに使用できる例をいくつか必要とします。 モデルにトレーニング データを自動的に分割させることを選択できます。既定では、ドキュメントの 80% を使用してモデルをトレーニングし、20% を使用してモデルのブラインド テストを行います。 モデルのテストに使用する特定のドキュメントがある場合は、ドキュメントにテストを行うためのラベルを付けることができます。

Language Studio のプロジェクトで、[データのラベル付け] を選択します。 すべてのドキュメントが表示されます。 テスト セットに追加する各ドキュメントを選択し、[モデルのパフォーマンスのテスト]を選択します。更新したラベルを保存し、新しいトレーニング ジョブを作成します。
検索インデックスを作成する
カスタム テキスト分類モデルによってエンリッチされる検索インデックスを作成するために必要な特定の操作はありません。 「Azure AI 検索ソリューションを作成する」の手順に従ってください。 関数アプリを作成した後、インデックス、インデクサー、カスタム スキルを更新します。
Azure 関数アプリの作成
関数アプリに必要な言語とテクノロジを選択できます。 アプリは、カスタム テキスト分類エンドポイントに JSON を渡すことができる必要があります。次に例を示します。
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
次に、モデルからの JSON 応答を処理します。次に例を示します。
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
次に、この関数は、構造化された JSON メッセージを AI 検索のカスタム スキルセットに返します。次に例を示します。
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
関数アプリでは、次の 5 つのことを知る必要があります。
- 分類するテキスト。
- トレーニング済みのカスタム テキスト分類がデプロイされたモデルのエンドポイント。
- カスタム テキスト分類プロジェクトの主キー。
- プロジェクト名。
- デプロイ名。
分類するテキストは、AI 検索のカスタム スキルセットから入力として関数に渡されます。 残りの 4 つの項目は Language Studio 内にあります。

エンドポイントとデプロイ名は、[モデルのデプロイ] ウィンドウにあります。

プロジェクト名と主キーは、[プロジェクト設定] ウィンドウにあります。
Azure AI 検索ソリューションを更新する
検索インデックスを強化するには、Azure portal で次の 3 つの変更を行う必要があります。
- カスタム テキスト分類エンリッチメントを格納するためのフィールドをインデックスに追加する必要があります。
- 分類するテキストを使用して関数アプリを呼び出すカスタム スキルセットを追加する必要があります。
- スキルセットからの応答をインデックスにマップする必要があります。
既存のインデックスにフィールドを追加する
Azure portal で、AI 検索リソースに移動し、インデックスを選択して、次の形式で JSON を追加します。
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
この JSON は、検索可能な category フィールドにクラスを格納する複合フィールドをインデックスに追加します。 2 番目のフィールド confidenceScore では、信頼度の割合が double フィールドに格納されます。
カスタム スキルセットを編集する
Azure portal でスキルセットを選択し、次の形式で JSON を追加します。
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
この WebApiSill スキル定義では、言語とドキュメントの内容を入力として関数アプリに渡すことを指定します。 アプリは、classという名前の JSON テキストを返します。
関数アプリからの出力をインデックスにマップする
最後の変更として、出力をインデックスにマップします。 Azure portal でインデクサーを選択し、JSON を編集して新しい出力マッピングを作成します。
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
これで、インデクサーは、関数アプリからの出力 document/class を classifiedtext フィールドに格納する必要があることを認識するようになりました。 これは複合フィールドとして定義されているため、関数アプリは、category と confidenceScore フィールドを含む JSON 配列を返す必要があります。
エンリッチされた検索インデックスでカスタム分類テキストを検索できるようになりました。