適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
この記事では、拡張 Spark History Server を使用して、SQL Server ビッグ データ クラスターで Spark アプリケーションをデバッグおよび診断する方法に関するガイダンスを提供します。 これらのデバッグ機能と診断機能は、Microsoft が提供する Spark History Server に組み込まれています。 拡張機能には、データ タブ、グラフ タブ、診断タブがあります。データ タブで、ユーザーは Spark ジョブの入力データと出力データを確認できます。 グラフ タブで、ユーザーはデータフローを確認し、ジョブ グラフを再生できます。 診断タブで、ユーザーはデータ スキュー、時間のずれ、および実行プログラムの使用状況の分析を参照できます。
Spark History Server へのアクセスを取得する
オープン ソースの Spark History Server ユーザー エクスペリエンスは、ジョブ固有のデータや、ビッグ データ クラスターのジョブ グラフとデータ フローの対話型の視覚化などの情報によって強化されています。
URL を指定して Spark History Server Web UI を開く
次の URL を参照して Spark History Server を開き、<Ipaddress> と <Port> をビッグ データ クラスター固有の情報に置き換えます。 SQL Server 2019 CU 5 より前のバージョンで展開されるクラスターで、基本認証 (ユーザー名とパスワード) のビッグ クラスター セットアップを使用する場合、ゲートウェイ (Knox) エンドポイントにログインするように求められたときに、ユーザー root を指定する必要があります。
SQL Server ビッグ データ クラスターの展開に関する記事を参照してください。 SQL Server 2019 (15.x) CU 5 以降、基本認証で新しいクラスターを展開すると、ゲートウェイを含むすべてのエンドポイントで AZDATA_USERNAME と AZDATA_PASSWORD が使用されます。 CU 5 にアップグレードされるクラスターのエンドポイントでは、ゲートウェイ エンドポイントに接続するとき、ユーザー名として root が引き続き使用されます。 この変更は、Active Directory 認証による展開には適用されません。 このリリース ノートの「ゲートウェイ エンドポイント経由でサービスにアクセスするための資格情報」を参照してください。
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
Spark History Server Web UI は次のような外観です。

Spark History Server の [Data](データ) タブ
ジョブ ID を選択し、ツール メニューの [Data](データ) をクリックしてデータ ビューを取得します。
各タブを選択して [Inputs](入力) 、 [Outputs](出力) 、 [Table Operations](テーブルの操作) を確認します。
![Spark History Server の [Data]\(データ\) タブ](media/apache-azure-spark-history-server/sparkui-data-tabs.png?view=sql-server-ver15)
すべての行をコピーするには、ボタン [Copy](コピー) をクリックします。

ボタン [csv] をクリックして、すべてのデータを CSV ファイルとして保存します。

フィールド [Search](検索) にキーワードを入力して検索すると、検索結果がすぐに表示されます。

列ヘッダーをクリックするとテーブルが並べ替えられます。プラス記号をクリックすると、詳細が表示されます。マイナス記号をクリックすると、行が折りたたまれます。

右側にある [Partial Download](部分的なダウンロード) ボタンをクリックして 1 つのファイルをダウンロードすると、選択したファイルがローカルの場所にダウンロードされます。 ファイルが存在しない場合は、新しいタブが開き、エラー メッセージが表示されます。

完全なパスまたは相対パスをコピーするには、ダウンロード メニューから展開して [Copy Full Path](完全なパスのコピー) 、 [Copy Relative Path](相対パスのコピー) を選択します。 Azure データ レイク ストレージ ファイルの場合は、 [Open in Azure Storage Explorer](Azure Storage Explorer で開く) を選択すると Azure Storage Explorer が起動します。 また、サインインするときに、正確なフォルダーを見つけます。

1 ページに表示される行数が多すぎる場合、テーブルの下の数値をクリックするとページに移動します。
![[Data]\(データ\) ページ](media/apache-azure-spark-history-server/sparkui-data-page.png?view=sql-server-ver15)
[Data](データ) の横にある疑問符をポイントすると、ヒントが表示されます。また、疑問符をクリックすると、詳細情報が表示されます。

問題についてフィードバックを送信するには、 [Provide us feedback](フィードバックの送信) をクリックします。

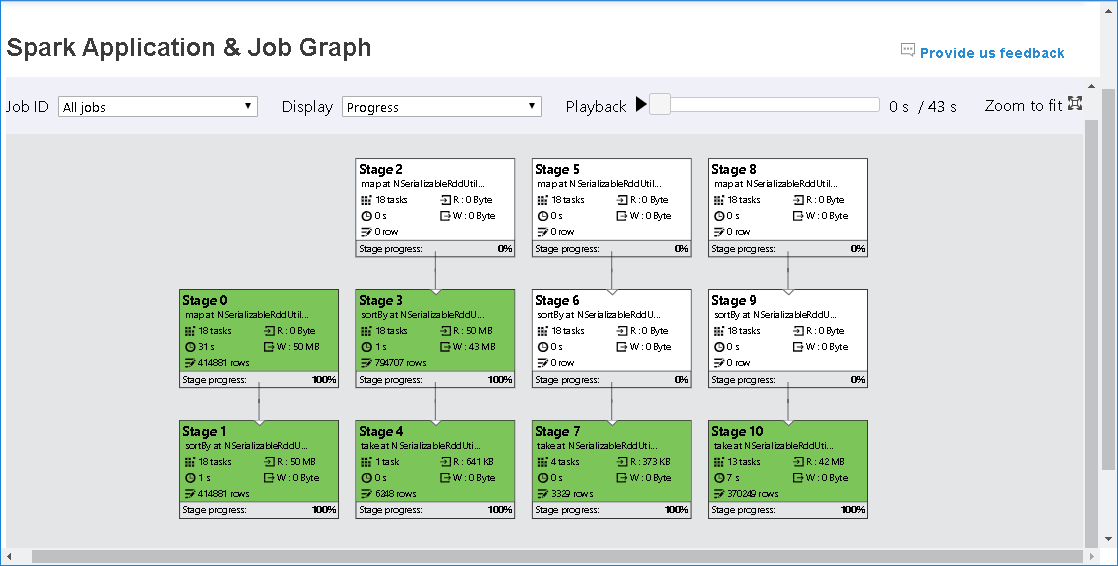
Spark History Server の [Graph](グラフ) タブ
ジョブ ID を選択し、ツール メニューの [Graph](グラフ) をクリックして、ジョブ グラフ ビューを取得します。
生成されたジョブ グラフによるジョブの概要を確認します。
既定では、すべてのジョブが表示され、 [Job ID](ジョブ ID) を指定してフィルター処理できます。

[Progress](進行状況) は既定値のままにします。 ユーザーがデータ フローを確認するには、[Display] (表示) のドロップダウン リストで [Read] (読み取り) または [Written] (書き込み) を選択します。

グラフ ノードは、ヒートマップを示す色で表示されます。

[Playback](再生) ボタンをクリックしてジョブを再生します。また、[Stop](停止) ボタンをクリックしていつでも停止できます。 タスクは、再生時に別の状態を表示する色で表示されます。
- 成功した場合は緑:ジョブは正常に完了しました。
- 再試行の場合はオレンジ:失敗しましたが、ジョブの最終結果には影響しないタスクのインスタンス。 このようなタスクには、後で成功する可能性がある重複するインスタンスまたは再試行インスタンスがあります。
- 実行中の場合は青:タスクは実行中です。
- 待機中またはスキップ済みの場合は白:タスクは実行を待機しているか、ステージがスキップされました。
- 失敗した場合は赤:タスクは失敗しました。

スキップされたステージは白で表示されます。

注
各ジョブを再生できます。 不完全なジョブの場合、再生はサポートされていません。
マウスをスクロールして、ジョブ グラフを拡大/縮小します。また、 [Zoom to fit](ウィンドウのサイズに合わせる) をクリックして、画面のサイズに合わせることができます。

失敗したタスクがある場合にツールヒントを表示するには、グラフ ノードをポイントします。また、ステージをクリックすると、ステージ ページが開きます。

次の条件を満たすタスクがある場合、ジョブ グラフ タブのステージにはツールヒントと小さいアイコンが表示されます。
- データ スキュー: データの読み取りサイズ > このステージ内のすべてのタスクの平均データ読み取りサイズ * 2 とデータ読み取りサイズ > 10 MB
- 時間のずれ: 実行時間 > このステージ内のすべてのタスクの平均実行時間 * 2 と実行時間 > 2 分

ジョブ グラフ ノードには、各ステージの次の情報が表示されます。
- ID。
- 名前または説明。
- 合計タスク数。
- データ読み取り: 入力サイズとシャッフル読み取りサイズの合計。
- データ書き込み: 出力サイズとシャッフル書き込みサイズの合計。
- 実行時間: 最初の試行の開始時刻と最後の試行の完了時刻の間の時間。
- 行数: 入力レコード、出力レコード、シャッフル読み取りレコード、シャッフル書き込みレコードの合計。
- 経過。
注
既定で、ジョブ グラフ ノードには各ステージの最後の試行の情報が表示されます (ステージの実行時間を除く)。ただし、再生中のグラフ ノードには、各試行の情報が表示されます。
注
読み取りと書き込みのデータ サイズの場合は、1 MB = 1000 KB = 1000 * 1000 バイトを使用します。
問題についてフィードバックを送信するには、 [Provide us feedback](フィードバックの送信) をクリックします。
Spark History Server の [Diagnosis](診断) タブ
ジョブ ID を選択し、ツール メニューの [Diagnosis](診断) をクリックして、ジョブの [Diagnosis](診断) ビューを取得します。 [Diagnosis](診断) タブには、 [Data Skew](データ スキュー) 、 [Time Skew](時間のずれ) 、および [Executor Usage Analysis](実行プログラムの使用状況の分析) が含まれます。
[Data Skew](データ スキュー) 、 [Time Skew](時間のずれ) 、および [Executor Usage Analysis](実行プログラムの使用状況の分析) を確認するには、各タブを選択します。
![[Diagnosis]\(診断\) タブ](media/apache-azure-spark-history-server/sparkui-diagnosis-tabs.png?view=sql-server-ver15)
[Data Skew](データ スキュー)
[Data Skew](データ スキュー) タブをクリックすると、指定したパラメーターに基づいて、対応する偏りのあるタスクが表示されます。
[パラメーターの指定] - 最初のセクションには、データ スキューの検出に使用するパラメーターが表示されます。 組み込みの規則は次のとおりです。読み取られたタスク データが、読み取られたタスク データの平均量の 3 倍を超えており、なおかつ 10 MB を超えていることが指定されています。 偏りのあるタスクに対して独自の規則を定義する場合は、 [Skewed Stage](偏りのあるステージ) パラメーターを選択します。それに応じて、 [Skew Char](スキュー グラフ) セクションが更新されます。
[傾斜したステージ] - 2 番目のセクションには、上記で指定した条件を満たす偏りのあるタスクがあるステージが表示されます。 ステージに偏りのあるタスクが複数ある場合、偏りのあるステージ テーブルには、最も偏りの大きなタスク (たとえば、データ スキューの最大データ) のみが表示されます。

[Skew Chart](スキュー グラフ) - スキュー ステージ テーブルの行を選択すると、データの読み取りと実行時間に基づいて、スキュー グラフにさらに多くのタスク分布の詳細が表示されます。 偏りのあるタスクは赤でマークされ、通常のタスクは青でマークされます。 パフォーマンスを考慮し、グラフには最大 100 個のサンプル タスクのみが表示されます。 タスクの詳細は、右下のパネルに表示されます。

[Time Skew](時間のずれ)
[Time Skew](時間のずれ) タブには、タスクの実行時間に基づいて偏りのあるタスクが表示されます。
[パラメーターの指定] - 最初のセクションには、時間のずれの検出に使用するパラメーターが表示されます。 時間のずれを検出する既定の条件は、タスクの実行時間が平均実行時間の 3 倍を超えており、なおかつ 30 秒を超えていることです。 必要に応じてパラメーターを変更できます。 [Skewed Stage](偏りのあるステージ) と [Skew Chart](スキュー グラフ) には、上の [Data Skew](データ スキュー) タブと同様に対応するステージとタスクの情報が表示されます。
[Time Skew](時間のずれ) をクリックすると、 [Specify Parameters](パラメーターの指定) セクションに設定されたパラメーターに従って、フィルター処理された結果が [Skewed Stage](偏りのあるステージ) セクションに表示されます。 [Skewed Stage](偏りのあるステージ) セクションのいずれかの項目をクリックすると、section3 に対応するグラフの下書きが描写され、タスクの詳細が右下のパネルに表示されます。

実行プログラムの使用状況の分析
[Executor Usage Graph](実行プログラムの使用状況グラフ) には、Spark ジョブの実際の実行プログラムの割り当てと実行状態が視覚化されます。
[Executor Usage Analysis](実行プログラムの使用状況の分析) をクリックすると、実行プログラムの使用状況に関する 4 種類の曲線の下書きが描写されます。 これには、 [Allocated Executors](割り当て済みの実行プログラム) 、 [Running Executors](実行中の実行プログラム) 、 [idle Executors](アイドルの実行プログラム) 、 [Max Executor Instances](最大実行プログラム インスタンス) が含まれます。 割り当て済みの実行プログラムについては、"Executor added" (実行プログラムの追加) イベントまたは "Executor removed" (実行プログラムの削除) イベントごとに割り当て済み実行プログラムが増減します。 詳細な比較については、[Jobs](ジョブ) タブの [Event Timeline](イベントのタイムライン) を確認します。
![[Executors]\(実行プログラム\) タブ](media/apache-azure-spark-history-server/sparkui-diagnosis-executors.png?view=sql-server-ver15)
色アイコンをクリックして、すべての下書きの対応する内容を選択または選択解除します。

Spark ログと Yarn ログ
Spark History Server に加えて、Spark と Yarn のログはそれぞれ次の場所で見つけることができます。
- Spark イベント ログ: hdfs:///system/spark-events
- Yarn ログ: hdfs:///tmp/logs/root/logs-tfile
注:これらのログは両方とも、既定の保持期間は 7 日間です。 保持期間を変更する場合は、Apache Spark と Apache Hadoop の構成に関するページを参照してください。 場所は変更することができません。
既知の問題
Spark History Server には、次の既知の問題があります。
現時点では、Spark 3.1 クラスター (CU13+) と Spark 2.4 (CU12-) でのみ機能します。
RDD を使用した入力/出力データは、[Data](データ) タブに表示されません。
次のステップ
- SQL Server ビッグ データ クラスターの概要
- Spark の設定を構成する
- Spark の設定を構成する