注
Time Series Insights サービスは、2024 年 7 月 7 日に廃止されます。 既存の環境をできるだけ早く別のソリューションに移行することを検討してください。 非推奨と移行の詳細については、
注意事項
これは Gen1 の記事です。
この記事では、Azure Time Series Insights 環境に参照データ セットを追加する方法について説明します。 参照データは、ソース データに結合することにより値を増幅するのに役立ちます。
参照データ セットは、イベント ソースからのイベントを増幅する項目の集まりです。 イベント ソースから受信した各イベントは、Azure Time Series Insights のイングレス エンジンによって、指定した参照データ セット内の対応するデータ行と結合されます。 こうして増幅されたイベントをクエリで利用することができます。 この結合操作は、参照データ セットに定義されている主キー列に基づいて行われます。
参照データは、遡及的に結合されることはありません。 そのため、データが構成されてアップロードされると、現在および将来のイングレス データのみが対応付けられ、参照日付セットに結合されます。
ビデオ
Time Series Insight の参照データ モデルについて説明します。
参照データ セットを追加する
Azure portal にサインインします。
既存の Azure Time Series Insights 環境を見つけます。 Azure portal の左側にあるメニューで [ すべてのリソース ] を選択します。 Azure Time Series Insights 環境を選択します。
[ 概要 ] ページを選択します。 ページの上部付近にある [要点 ] セクションを展開して 、Time Series Insights Explorer の URL を 見つけてリンクを開きます。
![[Essentials] セクションを展開する](media/add-reference-data-set/essentials.png)
お使いの Azure Time Series Insights 環境に対するExplorer を表示します。
Azure Time Series Insights Explorer で環境セレクターを展開します。 アクティブな環境を選択します。 Explorer ページの右上にある参照データ アイコンを選択します。
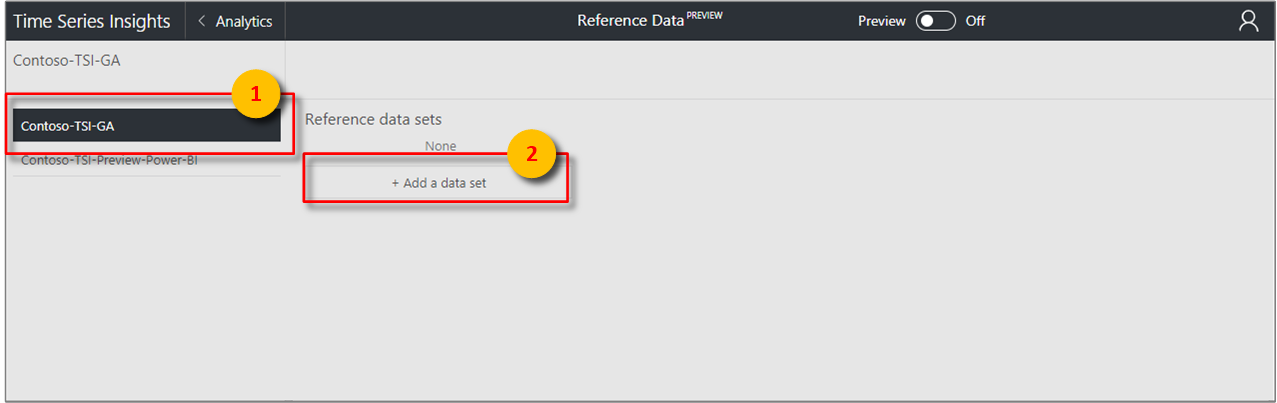
[+ データ セットの追加] ボタンを選択して、新しいデータ セットの追加を開始します。
[ 新しい参照データ セット ] ページで、データの形式を選択します。
- コンマ区切りのデータには CSV を選択します。 最初の行は、ヘッダー行として扱われます。
- JavaScript オブジェクト表記 (JSON) 形式のデータの JSON 配列 を選択します。
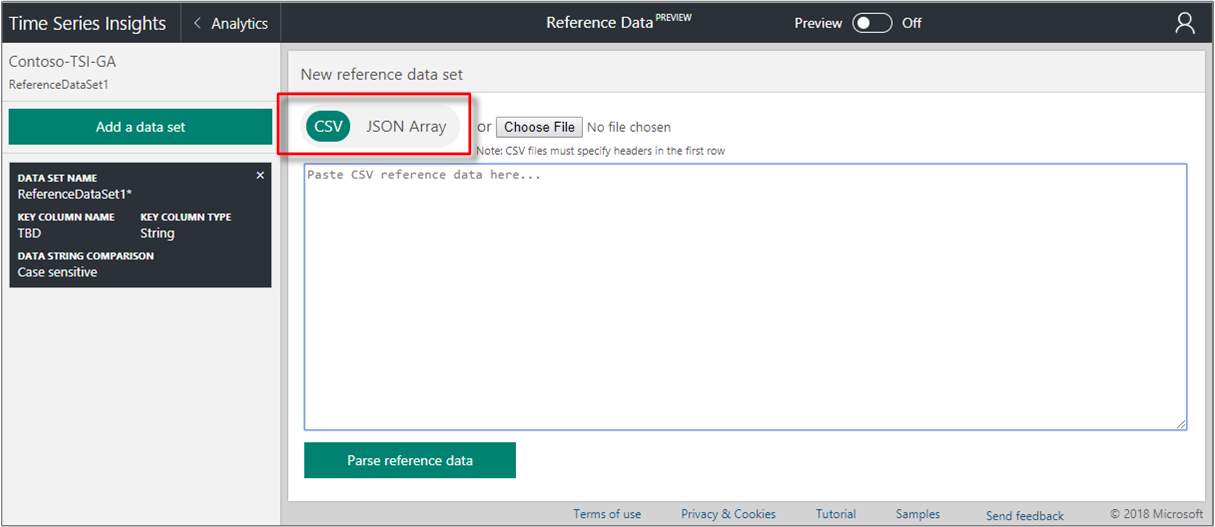
次のいずれかの方法を使用して、データを指定します。
- データをテキスト エディターに貼り付けます。 次に、[ 参照データの解析 ] ボタンを選択します。
- [ ファイルの選択 ] ボタンを選択して、ローカル テキスト ファイルからデータを追加します。
例えば、CSV データを貼り付け:

たとえば、JSON 配列データの貼り付け:

データ値の解析中にエラーが発生した場合は、ページの下部に赤色でエラーが表示されます (たとえば、
CSV parsing error, no rows extracted)。データが正常に解析されると、データ グリッドが表示され、データを表す行と列が表示されます。 データ グリッドをレビューし、内容が正しいこと確認してください。

各列をレビューして、仮定されたデータ型を理解し、必要であればデータ型を変更します。 列見出しでデータ型の記号を選択します。# は double(数値データ)、T|F はブール値、Abc は文字列用です。

必要であれば、列見出しの名前を変更します。 キー列の名前は、イベント ソース内の対応するプロパティに結合させるために必要です。
重要
参照データのキー列名が、大文字小文字の区別も含め、受信データへのイベント名と正確に一致することを確認してください。 非キー列の名前は、受信データを対応する参照データの値で増幅するために使用されます。
[ 行のフィルター]... フィールドに値を 入力して、必要に応じて特定の行を確認します。 フィルターはデータをレビューするのに便利ですが、データのアップロード中には適用されません。
データ・グリッドの上にある「データ・ セット名 」フィールドに入力して、データ・セットに名前を付けます。

データ グリッドの上にあるドロップダウンを選択して、データ セットの [主キー ] 列を指定します。

(省略可能)+ ボタンを選択して、複合主キーとしてセカンダリ キー列を追加します。 選択を元に戻す必要がある場合は、ドロップダウン リストから空の値を選択して、セカンダリ キーを削除します。
データをアップロードするには、[行の アップロード ] ボタンを選択します。

このページでは、アップロードが完了したことを確認し、 正常にアップロードされたデータセットのメッセージが表示されます。
警告
参照データ セット間で共有される列またはプロパティには、 重複するプロパティ名 のアップロード エラーが表示されます。 このエラーが発生すると、参照データセットを正常にアップロードすることはできません。 重複するプロパティ名を共有する行を結合することによって削除できます。
必要 に応じて、[行の追加]、[ 行の一括インポート]、または [列の追加] を選択して参照データ値を追加します。
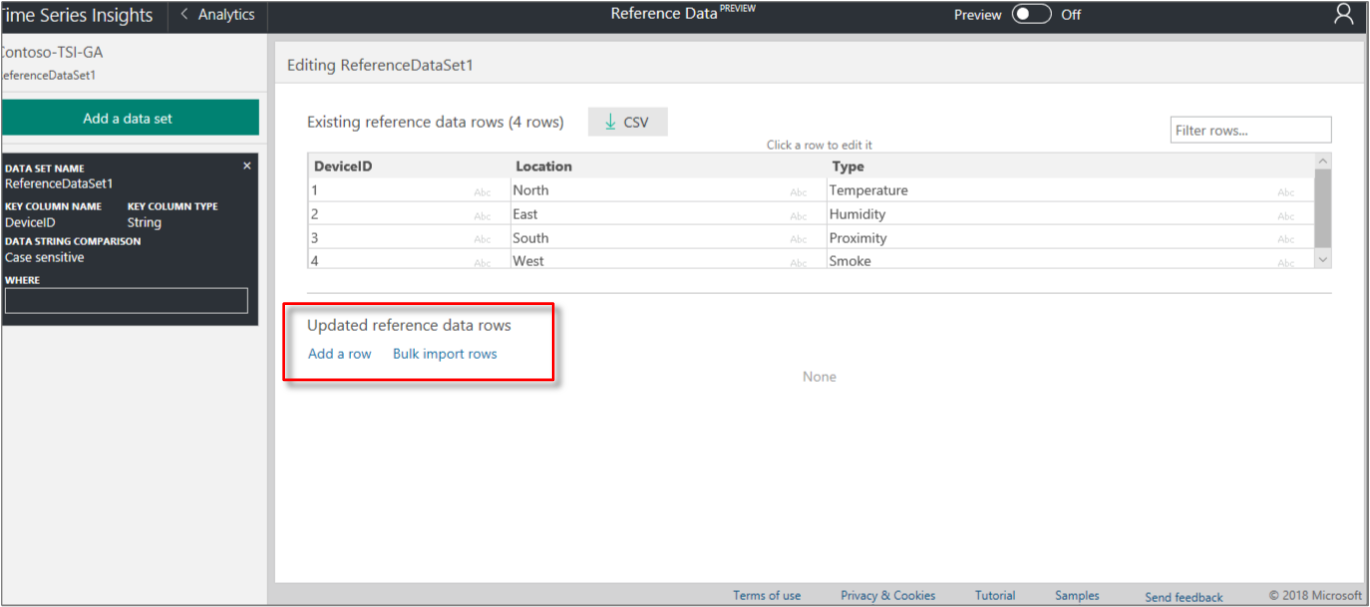
重要
一意のキーを別の行と共有する行は、その一意のキーを共有する最後に追加された行によってオーバーライドされる列を含みます。
注
追加された行は四角形である必要はありません。参照データ セット内の他のエントリの列数が少ない、大きい、または異なる場合があります。
![[Essentials] セクションを展開する](media/add-reference-data-set/essentials.png#lightbox)










次のステップ
参照データ をプログラムで管理します。
完全な API リファレンスについては、 リファレンス データ API ドキュメントを参照 してください。