ヒント
このコンテンツは、.NET Docs で入手できる、またはオフラインで読み取ることができる無料のダウンロード可能な PDF として入手できる、コンテナー化された .NET アプリケーションの電子ブックである .NET マイクロサービス アーキテクチャからの抜粋です。

予期しないエラーの対処は、特に分散システムにおいて、解決が最も難しい問題の 1 つです。 開発者が記述するコードの多くは例外の処理を伴い、これはテストに最も多くの時間が費やされる場所でもあります。 この問題は、エラーを処理するコードを記述するよりも複雑です。 マイクロサービスが実行されているマシンが失敗した場合はどうなりますか? このマイクロサービスの障害 (それ自体が難しい問題) を検出する必要があるだけでなく、マイクロサービスを再起動するために何かが必要です。
マイクロサービスは、障害に対する回復性があり、可用性のために別のマシンで頻繁に再起動できる必要があります。 また、この回復性は、マイクロサービスの代わりに保存された状態、マイクロサービスがこの状態を復旧できる状態、およびマイクロサービスが正常に再起動できるかどうかを示します。 言い換えると、コンピューティング機能には回復性 (プロセスはいつでも再起動できます) と、状態またはデータの回復性 (データ損失がなく、データの整合性が維持される) が必要です。
回復性の問題は、アプリケーションのアップグレード中にエラーが発生した場合など、他のシナリオで複合化されます。 マイクロサービスは、デプロイ システムと連携して、一貫性のある状態を維持するために、引き続き新しいバージョンに移行できるか、または以前のバージョンにロールバックできるかを判断する必要があります。 今後も使用できる十分なマシンがあるかどうか、および以前のバージョンのマイクロサービスを復旧する方法などの質問を考慮する必要があります。 このアプローチでは、アプリケーションとオーケストレーター全体でこれらの決定を行うことができるように、マイクロサービスが正常性情報を出力する必要があります。
さらに、回復性は、クラウドベースのシステムの動作に関連しています。 前述のように、クラウドベースのシステムは障害を受け入れ、障害から自動的に復旧する必要があります。 たとえば、ネットワークまたはコンテナーの障害が発生した場合、クライアント アプリまたはクライアント サービスには、メッセージの送信を再試行するか、要求を再試行する戦略が必要です。多くの場合、クラウドでのエラーは部分的であるためです。 このガイドの 「回復性のあるアプリケーションの実装 」セクションでは、部分的な障害を処理する方法について説明します。 ここでは、 Polly などのライブラリを使用して、指数バックオフによる再試行や .NET のサーキット ブレーカー パターンなどの手法について説明します。このパターンには、この問題を処理するためのさまざまなポリシーが用意されています。
マイクロサービスでの健康管理と診断
それは明白に思えるかもしれません、そしてそれはしばしば見落とされますが、マイクロサービスはその正常性と診断を報告する必要があります。 それ以外に、操作の観点から得られる洞察はほとんどありません。 独立した一連のサービス間で診断イベントを関連付け、その上でマシンのクロックスキューを調整してイベントの順序を理解することは困難です。 合意されたプロトコルとデータ形式を介してマイクロサービスと対話するのと同じ方法で、最終的にクエリと表示のためにイベント ストアに入る正常性イベントと診断イベントをログに記録する方法を標準化する必要があります。 マイクロサービス アプローチでは、異なるチームが 1 つのログ形式で同意することが重要です。 アプリケーションで診断イベントを表示するには、一貫したアプローチが必要です。
健康診断
正常性は診断とは異なります。 正常性は、適切なアクションを実行するためにマイクロサービスが現在の状態を報告することです。 典型的な例としては、アップグレードとデプロイメントによる可用性の維持があります。 プロセスのクラッシュまたはマシンの再起動により、サービスが現在異常である可能性がありますが、サービスは引き続き動作している可能性があります。 最後に必要なのは、アップグレードを実行してこの問題を悪化させることです。 最善の方法は、最初に調査を行うか、マイクロサービスが復旧する時間を許可することです。 マイクロサービスの正常性イベントにより、得られた十分な情報に基づいて判断することが可能になり、事実上、自己回復サービスを作成できます。
このガイドの 「ASP.NET Core サービスでの正常性チェックの実装 」セクションでは、マイクロサービスで新しい ASP.NET HealthChecks ライブラリを使用して、それらの状態を監視サービスに報告して適切なアクションを実行できるようにする方法について説明します。
また、AspNetCore.Diagnostics.HealthChecks と呼ばれる優れたオープン ソース ライブラリを使用することもできます。 GitHub および NuGet パッケージとして利用できます。 このライブラリでは、ひねりの利いた方法で正常性チェックを行い、2種類のチェックを処理します。
- Liveness: マイクロサービスが有効かどうかを確認します。つまり、要求を受け入れて応答できるかどうかを確認します。
- 準備: マイクロサービスの依存関係 (データベース、キュー サービスなど) 自体が準備ができているかどうかを確認し、マイクロサービスが実行する必要があることを実行できるようにします。
診断およびログイベントストリームの利用
ログは、例外、警告、単純な情報メッセージなど、アプリケーションまたはサービスの実行方法に関する情報を提供します。 通常、各ログはイベントごとに 1 行のテキスト形式ですが、例外では複数行にわたるスタック トレースも表示されることがよくあります。
モノリシック サーバー ベースのアプリケーションでは、ディスク上のファイル (ログ ファイル) にログを書き込み、任意のツールで分析できます。 アプリケーションの実行は固定サーバーまたは VM に限定されるため、一般に、イベントのフローを分析するのにそれほど複雑ではありません。 ただし、オーケストレーター クラスター内の多数のノード間で複数のサービスが実行される分散アプリケーションでは、分散イベントを関連付けることができるのは困難です。
マイクロサービス ベースのアプリケーションでは、イベントまたはログ ファイルの出力ストリームを単独で格納しないでください。また、中央の場所へのイベントのルーティングを管理しようともしないでください。 これは透過的である必要があります。つまり、各プロセスは、実行中の実行環境インフラストラクチャによってその下に収集される標準出力にイベント ストリームを書き込むだけです。 これらのイベント ストリーム ルーターの例として、複数のソースからイベント ストリームを収集し、出力システムに発行する Microsoft.Diagnostic.EventFlow があります。 これには、開発環境や Azure Monitor や Azure Diagnostics などのクラウド システムの単純な標準出力を含めることができます。 Splunk やミドルウェアなど、リアルタイムでもログを検索、アラート、レポート、監視できる優れたサードパーティのログ分析プラットフォームとツールもあります。
正常性と診断情報を管理するオーケストレーター
マイクロサービス ベースのアプリケーションを作成するときは、複雑さに対処する必要があります。 もちろん、1 つのマイクロサービスは簡単に処理できますが、マイクロサービスの数十または数百の種類と数千のインスタンスは複雑な問題です。 マイクロサービス アーキテクチャを構築するだけでなく、安定したまとまりのあるシステムを使用する場合は、高可用性、アドレス指定可能性、回復性、正常性、診断も必要です。
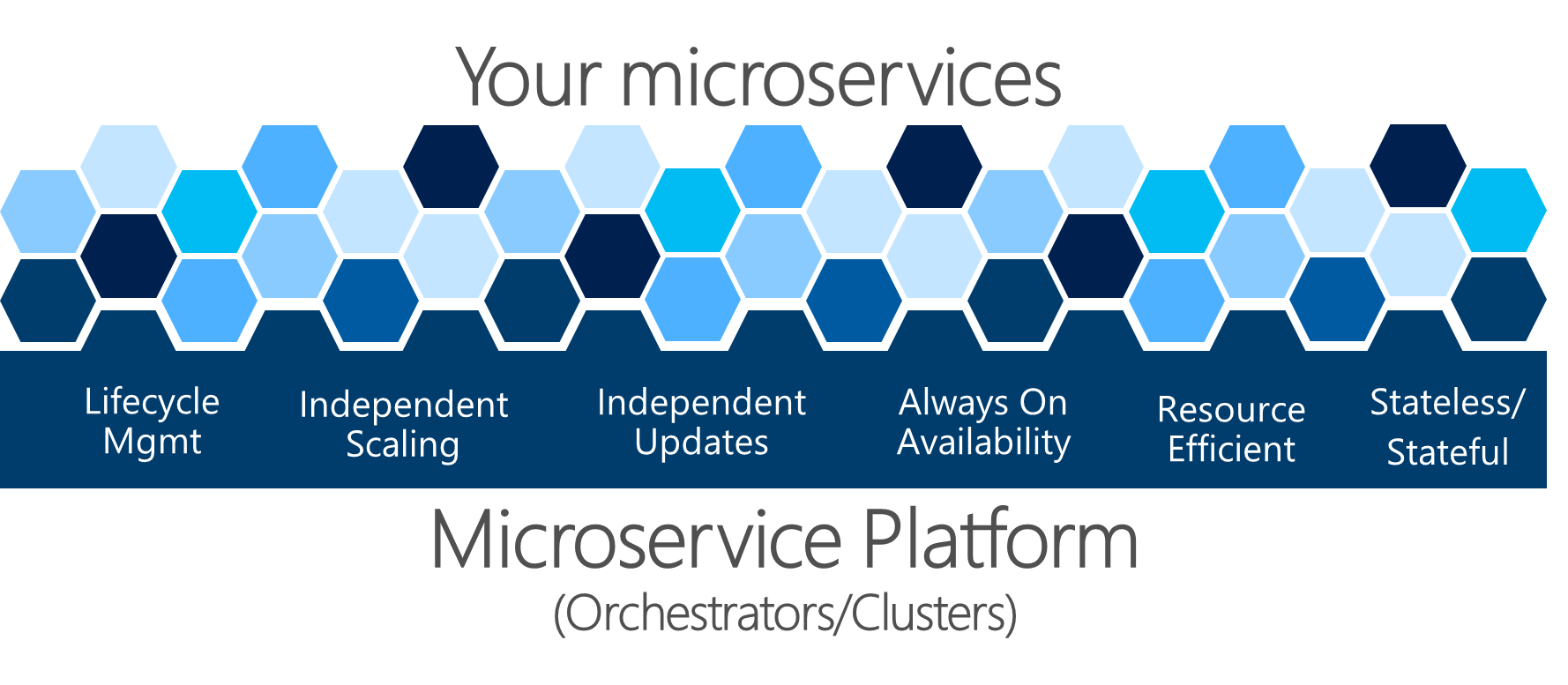
図 4-22 マイクロサービス プラットフォームは、アプリケーションの正常性管理の基礎です
図 4-22 に示す複雑な問題は、自分で解決するのは困難です。 開発チームは、ビジネス上の問題を解決し、マイクロサービス ベースのアプローチを使用してカスタム アプリケーションを構築することに重点を置く必要があります。 複雑なインフラストラクチャの問題を解決することに重点を置くべきではありません。その場合、マイクロサービス ベースのアプリケーションのコストは膨大になります。 そのため、オーケストレーターまたはマイクロサービス クラスターと呼ばれるマイクロサービス指向プラットフォームがあり、サービスの構築と実行とインフラストラクチャ リソースの効率的な使用に関する困難な問題を解決しようとします。 この方法により、マイクロサービス アプローチを使用するアプリケーションの構築の複雑さが軽減されます。
オーケストレーターが異なる場合は似ていますが、次のセクションで説明するように、各オーケストレーターによって提供される診断と正常性チェックは、OS プラットフォームに応じて機能と成熟度の状態が異なります。
その他のリソース
Twelve-Factor アプリ。 十一 ログ: ログをイベント ストリームとして扱う
https://12factor.net/logsMicrosoft Diagnostic EventFlow ライブラリ GitHub リポジトリ。
https://github.com/Azure/diagnostics-eventflowAzure Diagnostics とは
https://learn.microsoft.com/azure/azure-diagnosticsWindows コンピューターを Azure Monitor サービスに接続する
https://learn.microsoft.com/azure/azure-monitor/platform/agent-windows意味をログに記録する: セマンティック ログ アプリケーション ブロックの使用
https://learn.microsoft.com/previous-versions/msp-n-p/dn440729(v=pandp.60)Splunk 公式サイト。
https://www.splunk.com/ミドルウェア 公式サイト。
https://middleware.io/EventSource クラス Windows のイベント トレース用 API (ETW)
https://learn.microsoft.com/dotnet/api/system.diagnostics.tracing.eventsource
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET