クエリ アクセラレーションを使用すると、アプリケーションと分析フレームワークは、特定の操作を実行するために必要なデータのみを取得することで、データ処理を大幅に最適化できます。 これにより、保存されたデータに対する重要な分析情報を得るために必要な時間と処理能力が削減されます。
概要
クエリ アクセラレーションは、フィルター 述語 と 列プロジェクションを受け入れます。これを使用すると、データがディスクから読み取られる時点で、アプリケーションで行と列をフィルター処理できます。 述語の条件を満たすデータのみが、ネットワーク経由でアプリケーションに転送されます。 これにより、ネットワークの待機時間とコンピューティング コストが削減されます。
SQL を使用して、クエリ 高速化要求で行フィルター述語と列プロジェクションを指定できます。 要求で処理されるファイルは 1 つだけです。 そのため、結合や集計によるグループ化など、SQL の高度なリレーショナル機能はサポートされていません。 クエリ アクセラレーションでは、CSV と JSON 形式のデータが各要求への入力としてサポートされます。
クエリ アクセラレーション機能は、Data Lake Storage (階層型名前空間が有効になっているストレージ アカウント) に限定されません。 クエリ アクセラレーションは、階層型名前空間が有効になっていないストレージ アカウント内 の BLOB と互換性があります。 つまり、ストレージ アカウントに BLOB として既に格納されているデータを処理するときに、ネットワーク待機時間とコンピューティング コストを同じ削減できます。
クライアント アプリケーションでクエリ アクセラレーションを使用する方法の例については、「 Azure Data Lake Storage クエリ アクセラレーションを使用してデータをフィルター処理する」を参照してください。
データ フロー
次の図は、一般的なアプリケーションでクエリ アクセラレーションを使用してデータを処理する方法を示しています。
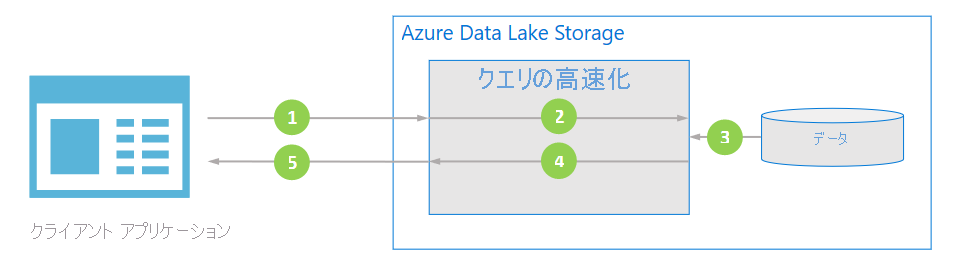
クライアント アプリケーションは、述語と列プロジェクションを指定してファイル データを要求します。
クエリ アクセラレーションは、指定された SQL クエリを解析し、データを解析およびフィルター処理するための作業を分散します。
プロセッサは、ディスクからデータを読み取り、適切な形式を使用してデータを解析した後、指定された述語と列プロジェクションを適用してデータをフィルター処理します。
クエリ アクセラレーションは、応答シャードを組み合わせてクライアント アプリケーションにストリーム バックします。
クライアント アプリケーションは、ストリーミングされた応答を受信して解析します。 アプリケーションは他のデータをフィルター処理する必要はありません。また、必要な計算や変換を直接適用できます。
低コストでパフォーマンスを向上
クエリ アクセラレーションは、アプリケーションによって転送および処理されるデータの量を減らすことで、パフォーマンスを最適化します。
集計された値を計算するために、アプリケーションは通常、ファイルから すべての データを取得し、データをローカルで処理してフィルター処理します。 分析ワークロードの入力/出力パターンを分析すると、アプリケーションでは通常、特定の計算を実行するために読み取ったデータの% が 20 個しか必要とされないことが明らかになります。 この統計は、 パーティションの排除などの手法を適用した後でも当てはまります。 つまり、そのデータの 80% がネットワーク経由で不必要に転送され、解析され、アプリケーションによってフィルター処理されます。 不要なデータを削除するように設計されたこのパターンでは、かなりのコンピューティング コストが発生します。
Azure は業界をリードするネットワークを備えていますが、スループットと待機時間の両方の点で、そのネットワーク間で不必要にデータを転送することは、アプリケーションのパフォーマンスに対して依然としてコストがかかります。 ストレージ要求中に不要なデータを除外することで、クエリ高速化によってこのコストが削減されます。
さらに、不要なデータを解析してフィルター処理するために必要な CPU 負荷では、アプリケーションが処理を行うために、より多くの VM とより大きな VM をプロビジョニングする必要があります。 このコンピューティング負荷をクエリアクセラレーションに転送することで、アプリケーションは大幅なコスト削減を実現できます。
クエリ 高速化のメリットを得られるアプリケーション
クエリ アクセラレーションは、分散分析フレームワークとデータ処理アプリケーション向けに設計されています。
Apache Spark や Apache Hive などの分散分析フレームワークには、フレームワーク内のストレージ抽象化レイヤーが含まれます。 これらのエンジンには、ユーザー クエリの最適なクエリ プランを決定するときに、基になる I/O サービスの機能に関する知識を組み込むことができるクエリ オプティマイザーも含まれます。 これらのフレームワークは、クエリ アクセラレーションの統合を開始しています。 その結果、これらのフレームワークのユーザーは、クエリに変更を加えることなく、クエリの待機時間が短縮され、総保有コストが削減されます。
クエリ アクセラレーションは、データ処理アプリケーション向けに設計されています。 これらの種類のアプリケーションは、通常、分析分析情報に直接結び付かない大規模なデータ変換を実行するため、確立された分散分析フレームワークが常に使用されるとは限りません。 多くの場合、これらのアプリケーションは基になるストレージ サービスとより直接的な関係を持ち、クエリ アクセラレーションなどの機能から直接メリットを得ることができます。
アプリケーションでクエリ アクセラレーションを統合する方法の例については、「 Azure Data Lake Storage クエリ アクセラレーションを使用してデータをフィルター処理する」を参照してください。
価格設定
Azure Data Lake Storage サービス内でのコンピューティング負荷の増加により、クエリ アクセラレーションを使用するための価格モデルは、通常の Azure Data Lake Storage トランザクション モデルとは異なります。 クエリ 高速化では、スキャンされたデータの量に対するコストと、呼び出し元に返されるデータの量のコストが課金されます。 詳細については、 Azure Data Lake Storage の価格に関するページを参照してください。
課金モデルが変更されたにもかかわらず、クエリ アクセラレーションの価格モデルは、はるかに高価な VM コストの削減を考えると、ワークロードの総保有コストを削減するように設計されています。