人工知能 (AI) エージェントは、大規模な言語モデル (LLM) と外部のツールやデータベースを組み合わせることで、アプリケーションがデータと対話する方法を変革しています。 エージェントを使用すると、複雑なワークフローの自動化、情報取得の精度の向上、データベースへの自然言語インターフェイスの容易化を実現できます。 この記事では、Azure Database for PostgreSQL でデータを検索および分析できるインテリジェントな AI エージェントを作成する方法について説明します。 この例では、法律研究アシスタントを使用して、セットアップ、実装、テストについて説明します。
AI エージェントとは
AI エージェントは、大規模な言語モデル (LLM) と外部ツールとデータベースを組み合わせることによって、単純なチャットボットを超えています。 スタンドアロンの LLM や標準の RAG システムとは異なり、AI エージェントは次のことができます。
- 計画: 複雑なタスクを、より小さい順番な手順に分割します。
- ツールの使用: API、コード実行、検索システムを使用して情報を収集したり、アクションを実行したりします。
- 認識: さまざまなデータ ソースからの入力を理解して処理します。
- 注意: 以前の操作を保存して思い出して、より適切な意思決定を行います。
AI エージェントを Azure Database for PostgreSQL などのデータベースに接続することで、エージェントはデータに基づいて、より正確でコンテキストに対応した応答を提供できます。 AI エージェントは、基本的な人間の会話を超えて、自然言語に基づいてタスクを実行します。 これらのタスクには、従来、コード化されたロジックが必要です。ただし、エージェントは、ユーザーが指定したコンテキストに基づいて実行に必要なタスクを計画できます。
AI エージェントの実装
Azure Database for PostgreSQL を使用して AI エージェントを実装するには、高度な AI 機能と堅牢なデータベース機能を統合して、インテリジェントなコンテキスト対応システムを作成する必要があります。 開発者は、ベクター検索、埋め込み、Azure AI Agent Service などのツールを利用することで、自然言語クエリを理解し、関連するデータを取得し、実用的な分析情報を提供できるエージェントを構築できます。 このセクションでは、AI エージェントを設定、構成、デプロイする手順について説明します。これにより、AI モデルと PostgreSQL データベース間のシームレスな対話が可能になります。
フレームワーク
各種のフレームワークとツールを使用することで、AI エージェントの開発とデプロイが容易になります。 これらのフレームワークはすべて、ツールとしての Azure Database for PostgreSQL の使用をサポートしています
実装サンプル
エージェントの計画、ツールの使用、認識には Azure AI Agent Service を使用し、ベクター データベースとセマンティック検索機能のツールとして Azure Database for PostgreSQL を使用します。
このチュートリアルでは、法務チームがワシントン州のクライアントをサポートするために関連するケースを調査するのに役立つ AI エージェントを構築します。 エージェント:
- 法的状況に関する自然言語クエリを受け入れます。
- Azure Database for PostgreSQL でベクター検索を使用して、関連するケースの優先順位を見つけます。
- 法的専門家にとって役立つ形式で調査結果を分析し、要約します。
[前提条件]
拡張機能を有効化して設定します
azure_aipg_vectorモデルをデプロイします
gpt-4o-mini&text-embedding-smallVisual Studio Code をインストールします。
Python 拡張機能をインストールします。
Azure CLI をインストールします。(最新バージョン)
注
エージェント用に作成したデプロイ済みモデルのキーとエンドポイントが必要です。
作業の開始
すべてのコードとサンプル データセットは、 この GitHub リポジトリで入手できます。
手順 1: Azure Database for PostgreSQL でベクター検索を設定する
まず、ベクター埋め込みを使用して訴訟ケースデータを格納および検索するためのデータベースを準備します。
環境のセットアップ
macOS/bash を使用している場合:
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
Windows/PowerShell
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
Windows / cmd.exe:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
環境変数を構成する
資格情報を使用して .env ファイルを作成します。
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
ドキュメントとベクトルを読み込む
Python ファイル load_data/main.py は、Azure Database for PostgreSQL にデータを読み込むための中心的なエントリ ポイントとして機能します。 このコードは、ワシントンのケースに関する情報を含む サンプル ケース データを処理します。
main.py の詳細な概要:
- データベースのセットアップとテーブルの作成: 必要な拡張機能を作成し、OpenAI API 設定を設定し、データベース テーブルを管理します。既存の拡張機能を削除し、ケース データを格納するための新しい拡張機能を作成します。
- データ インジェスト: このプロセスは、CSV ファイルからデータを読み取り、一時テーブルに挿入してから、メイン ケース テーブルに処理して転送します。
- 埋め込み生成: ケース テーブルに埋め込み用の新しい列を追加し、OpenAI の API を使用してケースの意見の埋め込みを生成し、新しい列に格納します。 埋め込みプロセスには約 3 ~ 5 分かかります
データ読み込みプロセスを開始するには、 load_data ディレクトリから次のコマンドを実行します。
python main.py
main.py の出力を次に示します。
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
手順 2: エージェントの Postgres ツールを作成する
Postgres からデータを取得するように AI エージェント ツールを構成し、 Azure AI Agent Service SDK を使用して AI エージェントを Postgres データベースに接続します。
エージェントが呼び出す関数を定義する
まず、エージェントの構造と docstring 内の必要なパラメーターを記述して、呼び出す関数を定義します。 すべての関数定義を 1 つのファイル (legal_agent_tools.py) に含め、メイン スクリプトにインポートできます。
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch cases information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
手順 3: Postgres を使用して AI エージェントを作成して構成する
次に、AI エージェントを設定し、PostgreSQL ツールと統合します。 Python ファイル src/simple_postgres_and_ai_agent.py は、エージェントを作成して使用するための中心的なエントリ ポイントとして機能します。
simple_postgres_and_ai_agent.pyの概要:
- エージェントの作成: 特定のモデルを使用して、Azure AI プロジェクトでエージェントを初期化します。
- Postgres ツールの追加: エージェントの初期化中に、データベースのベクター検索用 Postgres ツールが追加されます。
- スレッドの作成: 通信スレッドを設定します。 これは、エージェントにメッセージを送信して処理するために使用されます。
- エージェントと呼び出し Postgres ツールを実行する: エージェントとツールを使用してユーザーのクエリを処理します。 エージェントは、正しい回答を得るために使用するツールを計画できます。 このユース ケースでは、エージェントは関数シグネチャと docstring に基づいて Postgres ツールを呼び出してベクター検索を実行し、関連するデータを取得して質問に回答します。
- エージェントの応答を表示する: この関数は、エージェントの応答をユーザーのクエリに出力します。
Azure AI Foundry でプロジェクト接続文字列を検索する
Azure AI Foundry プロジェクトで、プロジェクトの [概要] ページからプロジェクト接続文字列を見つけます。 この文字列を使用して、プロジェクトを AI エージェント SDK に接続します。 この文字列を .env ファイルに追加します。

接続のセットアップ
ルート ディレクトリの .env ファイルに次の変数を追加します。
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the Agent with Tool Access
We created the agent in the AI Foundry project and added the Postgres tools needed to query the Database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/src/simple_postgres_and_ai_agent.py).
# Create an Azure AI Client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
通信スレッドを作成する
このコード スニペットは、エージェントが実行中に処理するエージェント スレッドとメッセージを作成する方法を示しています。
# Create thread for communication
thread = project_client.agents.create_thread()
# Create message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
要求を処理する
このコード スニペットは、エージェントがメッセージを処理し、適切なツールを使用して最適な結果を得るための実行を作成します。
このツールを使用して、エージェントは Postgres を呼び出し、クエリ 「上の階からアパートに漏れる水」* のベクター検索を呼び出して、質問に最適に回答するために必要なデータを取得できます。
from pprint import pprint
# Create and process agent run in thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
エージェントの実行
エージェントを実行するには、src ディレクトリから次のコマンドを実行します。
python simple_postgres_and_ai_agent.py
このエージェントは、Azure Database for PostgreSQL ツールを使用して、Postgres Database に保存されているケース データにアクセスするために同様の結果を生成します。
エージェントからの出力のスニペット:
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
手順 4: Azure AI Foundry プレイグラウンドを使用したテストとデバッグ
Azure AI Agent SDK を使用してエージェントを実行すると、エージェントがプロジェクトに格納され、エージェントプレイグラウンドでエージェントを試すことができます。
エージェントプレイグラウンドの使用
Azure AI Foundry の [エージェント] セクションに移動します
一覧でエージェントを検索し、[選択して開く]
プレイグラウンド インターフェイスを使用して、さまざまな法的クエリをテストします

「上の階からアパートに水が漏れる、ワシントンの著名な法的判例は何ですか?」というクエリをテストします。エージェントは、使用する適切なツールを選択し、そのクエリに対して予想される出力を要求します。 サンプル出力として sample_vector_search_cases_output.json を使用します。
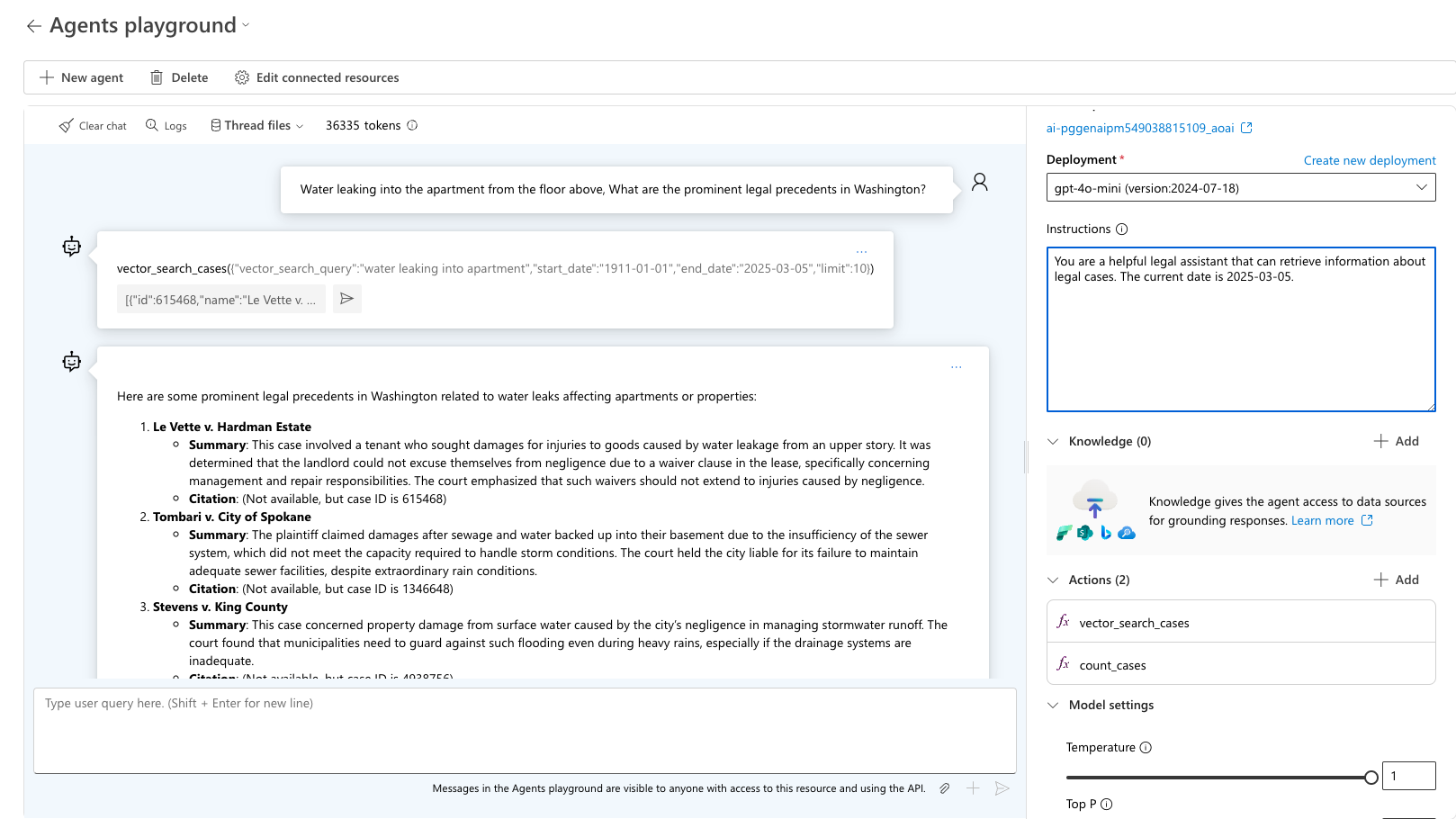
手順 5: Azure AI Foundry トレースを使用したデバッグ
Azure AI Foundry SDK を使用してエージェントを開発する場合は、 Tracing を使用してエージェントをデバッグできます。これにより、Postgres などのツールへの呼び出しをデバッグし、エージェントが各タスクを調整する方法を確認できます。
トレースを使用したデバッグ
Azure AI Foundry メニューの [トレース] を選択する
新しい Application Insights リソースを作成するか、トレースを
 接続します。
接続します。 を表示し、エージェントの操作の詳細なトレースを確認します。
を表示し、エージェントの操作の詳細なトレースを確認します。
AI エージェントと Postgres を使用してトレースを設定する方法の詳細については、 GitHub の advanced_postgres_and_ai_agent_with_tracing.py ファイルを参照してください。
関連コンテンツ
- GenAI Framework と Azure Database for PostgreSQL
- Azure Database for PostgreSQL での LangChain の使用
- Azure OpenAI Service 統合に関する詳細情報
- Azure Database for PostgreSQL フレキシブル サーバーの Azure AI 拡張機能。
- Azure Database for PostgreSQL フレキシブル サーバーと Azure OpenAI を使用したセマンティック検索。
- Azure Database for PostgreSQL フレキシブル サーバーで pgvector を有効にして使用します。