重要
この記事では、Azure Machine Learning SDK v1 の使用に関する情報を提供します。 SDK v1 は 2025 年 3 月 31 日の時点で非推奨となり、サポートは 2026 年 6 月 30 日に終了します。 SDK v1 は、その日付までインストールして使用できます。
2026 年 6 月 30 日より前に SDK v2 に移行することをお勧めします。 SDK v2 の詳細については、「 Azure Machine Learning Python SDK v2 と SDK v2 リファレンスとは」を参照してください。
この記事では、 Python スクリプトの実行 コンポーネントを使用して、Azure Machine Learning デザイナーにカスタム ロジックを追加する方法について説明します。 このガイドでは、Pandas ライブラリを使用して簡単な特徴エンジニアリングを行います。
組み込みのコード エディターを使用して、簡単な Python ロジックをすばやく追加できます。 より複雑なコードを追加したり、Python ライブラリをさらにアップロードしたりするには、zip ファイル メソッドを使用する必要があります。
既定の実行環境では、Python の Anaconda ディストリビューションが使用されます。 プレインストールされているパッケージの完全な一覧については、 Python スクリプトの実行 コンポーネントリファレンスを参照してください。

重要
このドキュメントで言及しているグラフィカル要素 (スタジオやデザイナーのボタンなど) が表示されない場合は、そのワークスペースに対する適切なレベルのアクセス許可がない可能性があります。 ご自分の Azure サブスクリプションの管理者に連絡して、適切なレベルのアクセス許可があることを確認してください。 詳細については、「ユーザーとロールを管理する」を参照してください。
デザイナーで Python コードを実行する
Execute Python Script (Python スクリプトの実行) コンポーネントを追加する
Azure Machine Learning Studio にサインインし、使用するワークスペースを選択します。
サイドバー メニューから [デザイナー ] を選択します。 [ クラシック事前構築済み] で、[ クラシック事前構築済みコンポーネントを使用して新しいパイプラインを作成する] を選択します。
パイプライン キャンバスの左側にある [コンポーネント] を選択します。
[ Python 言語 ] セクションで、[ Python スクリプトの実行 ] コンポーネントを見つけます。 コンポーネントをパイプライン キャンバスにドラッグ アンド ドロップします。
入力データセットの接続
サンプルデータセクションで自動車価格データ(生)のサンプルデータセットを見つけてください。 データセットをパイプライン キャンバスにドラッグ アンド ドロップします。
データセットの出力ポートを [Execute Python Script](Python スクリプトの実行) コンポーネントの左上の入力ポートに接続します。 デザイナーは、入力をパラメーターとしてエントリ ポイント スクリプトに公開します。
右側の入力ポートは、zip 圧縮された Python ライブラリ用に予約されています。

使用する特定の入力ポートに注意してください。 デザイナーによって、左側の入力ポートが変数
dataset1に、中央の入力ポートがdataset2に割り当てられます。
Python スクリプトの実行 コンポーネントで直接データの生成やインポートを行えるため、入力コンポーネントは省略可能です。
Python コードの記述
デザイナーには、独自の Python コードを編集および入力するための初期エントリ ポイント スクリプトが用意されています。
この例では、Pandas を使用して、自動車データセット列の Price とHorsepower の 2 つを組み合わせて、 1 馬力あたりドルという新しい列を作成します。 この列は、馬力単位ごとの支払い額を表します。これは、特定の車がその価格に対してお得であるかどうかを判断するのに有用な情報ポイントとなる可能性があります。
Python スクリプトの実行コンポーネントをダブルクリックします。
キャンバスの右側に表示されるペインで、 [Python スクリプト] テキスト ボックスを選択します。
以下のコードをコピーして、テキスト ボックスに貼り付けます。
import pandas as pd def azureml_main(dataframe1 = None, dataframe2 = None): dataframe1['Dollar/HP'] = dataframe1.price / dataframe1.horsepower return dataframe1パイプラインは次のイメージのようになっているはずです。
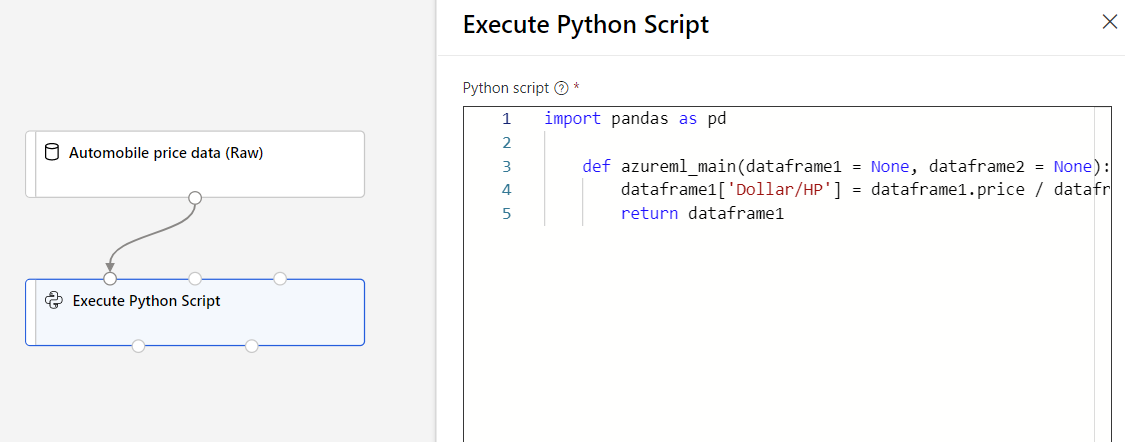
エントリ ポイント スクリプトには、関数
azureml_mainが含まれている必要があります。 関数には 2 つのパラメーターがあり、これらは Python スクリプトの実行コンポーネントの 2 つの入力ポートにマップされます。戻り値は Pandas データフレームである必要があります。 最大 2 つのデータフレームをコンポーネントの出力として返すことができます。
パイプラインを送信します。
これで、新しい Dollars/HP 機能を備えたデータセットが作成されました。 この新機能は、車を推奨する人をトレーニングするのに役立つ可能性があります。 この例では、特徴抽出と次元削減を示しています。