適用対象: Azure CLI ml 拡張機能 v2 (現行)
Azure CLI ml 拡張機能 v2 (現行)
この記事では、Azure CLI とコンポーネントを使用して、機械学習パイプラインを作成して実行する方法について説明します。 コンポーネントを使用せずにパイプラインを作成できますが、コンポーネントは柔軟性を提供し、再利用を可能にします。 Azure Machine Learning パイプラインは、YAML で定義し、CLI から実行するか、Python で作成するか、ドラッグ アンド ドロップ UI を使用して Azure Machine Learning Studio Designer で構成できます。 この記事では、CLI に焦点を当てます。
前提条件
Azure サブスクリプション。 お持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
Machine Learning 用の Azure CLI 拡張機能。インストールおよび設定されています。
サンプル リポジトリの複製。 次のコマンドを使用して、リポジトリを複製できます。
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
先に読んでおくことが推奨される記事
コンポーネントを使用して最初のパイプラインを作成する
最初に、例を使用してコンポーネントを含むパイプラインを作成します。 そうすることで、Azure Machine Learning でのパイプラインとコンポーネントの外観が最初に示されます。
azureml-examples リポジトリのcli/jobs/pipelines-with-components/basics ディレクトリで、3b_pipeline_with_data サブディレクトリに移動します。 このディレクトリには 3 種類のファイルがあります。 これらは、独自のパイプラインを構築するときに作成する必要があるファイルです。
pipeline.yml。 この YAML ファイルは、機械学習パイプラインを定義します。 ここでは、完全な機械学習タスクをマルチステップ ワークフローに分割する方法について説明します。 たとえば、履歴データを使用して売上予測モデルをトレーニングする単純な機械学習タスクを考えてみましょう。 データ処理、モデル トレーニング、モデル評価の手順を含むシーケンシャル ワークフローを構築できます。 各ステップは、明確に定義されたインターフェイスを持ち、個別に開発、テスト、最適化できるコンポーネントです。 パイプライン YAML では、子ステップがパイプライン内の他のステップに接続する方法も定義されます。 たとえば、モデルトレーニングステップはモデルファイルを生成し、モデルファイルはモデル評価ステップに渡されます。
component.yml。 これらの YAML ファイルは、コンポーネントを定義します。 次の情報が含まれています。
- メタデータ: 名前、表示名、バージョン、説明、種類など。 メタデータは、コンポーネントの説明と管理に役立ちます。
- インターフェイス: 入力と出力。 たとえば、モデル トレーニング コンポーネントは、トレーニング データとエポックの数を入力として受け取り、トレーニング済みのモデル ファイルを出力として生成します。 インターフェイスが定義された後、さまざまなチームがコンポーネントを個別に開発およびテストできます。
- コマンド、コード、環境: コンポーネントを実行するコマンド、コード、環境。 このコマンドは、コンポーネントを実行するシェル コマンドです。 通常、コードはソース コード ディレクトリを参照します。 環境には、Azure Machine Learning 環境 (キュレーションまたは顧客作成)、Docker イメージ、または conda 環境を指定できます。
component_src。 これらは、特定のコンポーネントのソース コード ディレクトリです。 コンポーネントで実行されるソース コードが含まれています。 Python、R などの任意の言語を使用できます。 コードはシェル コマンドで実行する必要があります。 ソース コードでは、シェル コマンド ラインからいくつかの入力を受け取って、この手順の実行方法を制御できます。 たとえば、トレーニング ステップでは、トレーニング データ、学習率、トレーニング プロセスを制御するエポックの数を取得できます。 シェル コマンドの引数は、入力と出力をコードに渡すのに使用されます。
次に、 3b_pipeline_with_data 例を使用してパイプラインを作成します。 各ファイルについては、以降のセクションで詳しく説明します。
まず、次のコマンドを使用して、使用可能なコンピューティング リソースを一覧表示します。
az ml compute list
お持ちでない場合は、次のコマンドを実行して、 cpu-cluster という名前のクラスターを作成します。
注
サーバーレス コンピューティングを使う場合は、このステップをスキップしてください。
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
次のコマンドを実行して、pipeline.yml ファイルで定義されているパイプライン ジョブを作成します。 コンピューティング先は、pipeline.yml ファイルで azureml:cpu-cluster として参照されます。 コンピューティング先で別の名前が使用される場合は、必ず pipeline.yml ファイルで更新してください。
az ml job create --file pipeline.yml
次のようなパイプライン ジョブに関する情報を含む JSON ディクショナリを受け取る必要があります。
| キー | 説明 |
|---|---|
name |
ジョブの GUID ベースの名前。 |
experiment_name |
Studio でジョブが整理されるときに使用される名前。 |
services.Studio.endpoint |
パイプライン ジョブを監視および確認するための URL。 |
status |
ジョブの状態。 おそらく、この時点で Preparing だろう。 |
services.Studio.endpoint URL に移動して、パイプラインの視覚化を確認します。
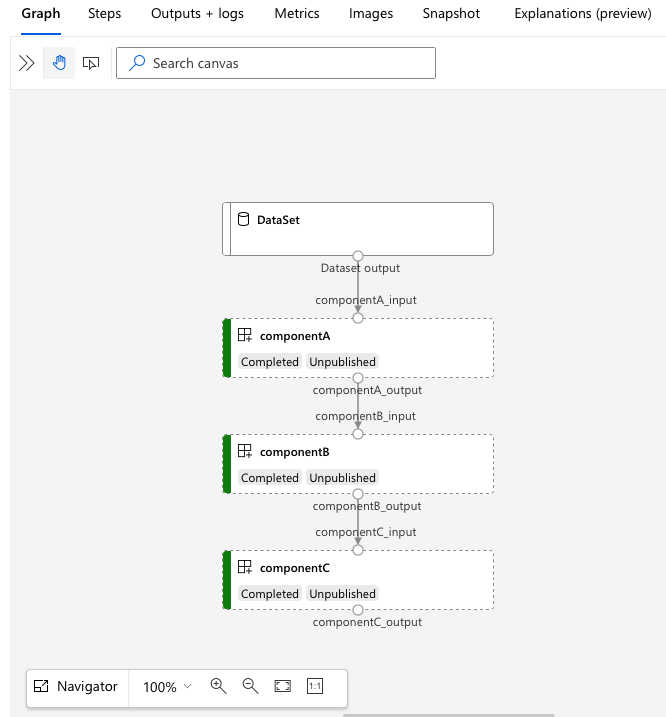
パイプライン定義 YAML について
次に、 3b_pipeline_with_data/pipeline.yml ファイル内のパイプライン定義を確認します。
注
サーバーレス コンピューティングを使う場合は、このファイルで default_compute: azureml:cpu-cluster を default_compute: azureml:serverless に置き換えてください。
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
次の表では、パイプライン YAML スキーマの最も一般的に使用されるフィールドについて説明します。 詳細については、「完全なパイプライン YAML スキーマ」を参照してください。
| キー | 説明 |
|---|---|
type |
必須。 ジョブの種類。 パイプライン ジョブ用に pipeline である必要があります。 |
display_name |
スタジオ UI のパイプライン ジョブの表示名。 Studio UI で編集可能。 ワークスペース内のすべてのジョブで一意である必要はありません。 |
jobs |
必須。 パイプライン内のステップとして実行する個々のジョブのセットのディクショナリ。 これらのジョブは、親パイプライン ジョブの子ジョブと見なされます。 現在のリリースでは、パイプラインでサポートされているジョブの種類はcommandとsweepが含まれています。 |
inputs |
パイプライン ジョブへの入力の辞書。 キーはジョブのコンテキスト内の入力の名前であり、値は入力値です。 これらのパイプライン入力は、 ${{ parent.inputs.<input_name> }} 式を使用して、パイプライン内の個々のステップ ジョブの入力によって参照できます。 |
outputs |
パイプライン ジョブの出力構成のディクショナリ。 キーはジョブのコンテキストでの出力の名前であり、値は出力構成です。 これらのパイプライン出力は、 ${{ parents.outputs.<output_name> }} 式を使用して、パイプライン内の個々のステップ ジョブの出力によって参照できます。 |
3b_pipeline_with_dataの例には、3 段階のパイプラインが含まれています。
- これらの 3 つのステップは
jobsで定義されています。 3 つのステップはすべてcommand型です。 各ステップの定義は、対応するcomponent*.ymlファイル内にあります。 コンポーネントの YAML ファイルは 、3b_pipeline_with_data ディレクトリで確認できます。componentA.ymlについては、次のセクションで説明します。 - このパイプラインには、実際のパイプラインで一般的なデータ依存関係があります。 コンポーネント A は、
./data(18 行目から 21 行目) のローカル フォルダーからデータ入力を受け取り、その出力をコンポーネント B (29 行目) に渡します。 コンポーネント A の出力は、${{parent.jobs.component_a.outputs.component_a_output}}として参照できます。 default_computeは、パイプラインの既定のコンピューティングを定義します。jobsのコンポーネントで別のコンピューティングが定義されている場合は、コンポーネント固有の設定が適用されます。

パイプライン内のデータの読み取りと書き込み
一般的なシナリオの 1 つは、パイプライン内のデータの読み取りと書き込みです。 Azure Machine Learning では、同じスキーマを使用して、すべての種類のジョブ (パイプライン ジョブ、コマンド ジョブ、スイープ ジョブ) の データの読み取りと書き込 みを行います。 一般的なシナリオでパイプラインでデータを使用する例を次に示します。
コンポーネント定義 YAML について
コンポーネントを定義する YAML の例である 、componentA.yml ファイルを次に示します。
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
この表では、コンポーネント YAML の最も一般的に使用されるフィールドを定義します。 詳細については、「完全なコンポーネント YAML スキーマ」を参照してください。
| キー | 説明 |
|---|---|
name |
必須。 コンポーネントの名前。 Azure Machine Learning ワークスペース全体で一意である必要があります。 小文字で始まる必要があります。 小文字、数字、アンダースコア (_) を使用できます。 最大文字数は 255 文字です。 |
display_name |
Studio UI のコンポーネントの表示名。 ワークスペース内で一意である必要はありません。 |
command |
必須。 実行するコマンド。 |
code |
コンポーネントにアップロードして使用するソース コード ディレクトリへのローカル パス。 |
environment |
必須。 コンポーネントの実行に使用される環境。 |
inputs |
コンポーネント入力のディクショナリ。 キーはコンポーネントのコンテキスト内の入力の名前であり、値はコンポーネント入力定義です。 ${{ inputs.<input_name> }}式を使用して、コマンド内の入力を参照できます。 |
outputs |
コンポーネント出力のディクショナリ。 キーはコンポーネントのコンテキスト内の出力の名前であり、値はコンポーネントの出力定義です。 ${{ outputs.<output_name> }}式を使用して、コマンドの出力を参照できます。 |
is_deterministic |
コンポーネントの入力が変更されない場合に、前のジョブの結果を再利用するかどうか。 既定値は true です。 この設定は 、既定では再利用とも呼ばれます。 falseに設定した場合の一般的なシナリオは、クラウド ストレージまたは URL からデータを強制的に再読み込みすることです。 |
3b_pipeline_with_data/componentA.ymlの例では、コンポーネント A には 1 つのデータ入力と 1 つのデータ出力があり、親パイプラインの他のステップに接続できます。 パイプライン ジョブが送信されると、コンポーネント YAML の code セクション内のすべてのファイルが Azure Machine Learning にアップロードされます。 この例では、 ./componentA_src の下のファイルがアップロードされます。 ( componentA.yml の 16 行目)。Studio UI でアップロードされたソース コードを確認できます。次のスクリーンショットに示すように、グラフで componentA ステップをダブルクリックし、[ コード ] タブに移動します。 これは簡単な印刷を行う hello-world スクリプトであり、現在の日時を componentA_output パスに書き込むことがわかります。 コンポーネントは入力を受け取り、コマンド ラインを介して出力を提供します。 argparse経由で hello.py で処理されます。

入力と出力
入力と出力は、コンポーネントのインターフェイスを定義します。 入力と出力には、リテラル値 ( string、 number、 integer、または boolean) または入力スキーマを含むオブジェクトを指定できます。
オブジェクト入力 ( uri_file、 uri_folder、 mltable、 mlflow_model、または custom_modelの種類) は、親パイプライン ジョブの他のステップに接続して、データ/モデルを他のステップに渡すことができます。 パイプライン グラフでは、オブジェクトの種類の入力が接続ドットとしてレンダリングされます。
リテラル値の入力 (string、 number、 integer、 boolean) は、実行時にコンポーネントに渡すことができるパラメーターです。 default フィールドには、リテラル入力の既定値を追加できます。 number型とinteger型の場合は、minフィールドとmax フィールドを使用して、最小値と最大値を追加することもできます。 入力値が最小値より小さいか、最大値を超える場合、パイプラインは検証時に失敗します。 パイプライン ジョブを送信する前に検証が行われるため、時間を節約できます。 検証は、CLI、Python SDK、およびデザイナー UI に対して機能します。 次のスクリーンショットは、デザイナー UI の検証例を示しています。 同様に、 enum フィールドで許可される値を定義できます。

コンポーネントに入力を追加する場合は、次の 3 つの場所で編集する必要があります。
- コンポーネント YAML の
inputsフィールド。 - コンポーネント YAML の
commandフィールド。 - コマンド ライン入力を処理するコンポーネント ソース コード。
これらの場所は、前のスクリーンショットの緑色のボックスでマークされています。
入力と出力の詳細については、「 コンポーネントとパイプラインの入力と出力の管理」を参照してください。
環境
環境は、コンポーネントが実行される環境です。 Azure Machine Learning 環境 (キュレーションまたはカスタム登録済み)、Docker イメージ、または conda 環境を指定できます。 次の例を参照してください。
- 登録済みの Azure Machine Learning 環境資産。 環境は、
azureml:<environment-name>:<environment-version>構文を使用してコンポーネントで参照されます。 - パブリック Docker イメージ。
- Conda ファイル。 conda ファイルは、基本イメージと共に使用する必要があります。
再利用と共有のためにコンポーネントを登録する
一部のコンポーネントは特定のパイプラインに固有ですが、コンポーネントの本当の利点は再利用と共有によって得られます。 Machine Learning ワークスペースにコンポーネントを登録して、再利用できるようにします。 登録済みコンポーネントでは自動バージョン管理がサポートされているため、コンポーネントを更新できますが、古いバージョンを必要とするパイプラインは引き続き機能します。
azureml-examples リポジトリで、 cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components ディレクトリに移動します。
コンポーネントを登録するには、az ml component create コマンドを使用します。
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
これらのコマンドが完了すると、 Studio の [Assets>Components] の下にコンポーネントが表示されます。

コンポーネントを選択します。 コンポーネントのバージョンごとに詳細情報が表示されます。
[ 詳細 ] タブには、コンポーネント名、作成者、バージョンなどの基本情報が表示されます。 [タグ] と [説明] には編集可能なフィールドがあります。 タグを使用して検索キーワードを追加できます。 説明フィールドは、Markdown の書式設定をサポートしています。 これを使用して、コンポーネントの機能と基本的な使用方法を説明する必要があります。
[ ジョブ ] タブには、コンポーネントを使用するすべてのジョブの履歴が表示されます。
パイプライン ジョブ YAML ファイルの登録済みコンポーネントを使用する
ここでは、パイプライン YAML で登録済みコンポーネントを使用する方法の例として、 1b_e2e_registered_components を使用します。 1b_e2e_registered_components ディレクトリに移動し、pipeline.yml ファイルを開きます。 inputs および outputs フィールドのキーと値は、既に説明したものに似ています。 唯一の重要な違いは、component エントリの jobs.<job_name>.component フィールドの値です。 component値は、azureml:<component_name>:<component_version>形式です。 たとえば、 train-job 定義では、登録済みコンポーネント my_train の最新バージョンを使用する必要があることを指定します。
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
コンポーネントを管理する
CLI v2 を使用して、コンポーネントの詳細を確認し、コンポーネントを管理できます。 az ml component -hを使用して、コンポーネント コマンドの詳細な手順を取得します。 次の表は、すべての使用可能なコマンドの一覧です。 「Azure CLI リファレンス」でその他の例を参照してください。
| コマンド | 説明 |
|---|---|
az ml component create |
コンポーネントを作成する。 |
az ml component list |
ワークスペース内のコンポーネントを一覧表示します。 |
az ml component show |
コンポーネントの詳細を表示します。 |
az ml component update |
コンポーネントを更新します。 更新プログラムは、いくつかのフィールド (説明、display_name) でのみサポートされます。 |
az ml component archive |
コンポーネント コンテナーをアーカイブします。 |
az ml component restore |
アーカイブされたコンポーネントを復元します。 |