バッチ エンドポイントは Microsoft Entra 認証 (つまり aad_token) をサポートします。 そのため、バッチ エンドポイントを呼び出すには、ユーザーが有効な Microsoft Entra 認証トークンをバッチ エンドポイント URI に提示する必要があります。 承認はエンドポイント レベルで適用されます。 次の記事では、バッチ エンドポイントを正しく操作する方法と、そのセキュリティ要件について説明します。
承認のしくみ
バッチ エンドポイントを呼び出すには、ユーザーがセキュリティ プリンシパルを表す有効な Microsoft Entra トークンを提示する必要があります。 このプリンシパルには、ユーザー プリンシパルまたはサービス プリンシパルを指定できます。 いずれの場合も、エンドポイントが呼び出されると、トークンに関連付けられている ID の下にバッチ デプロイ ジョブが作成されます。 ジョブを正常に作成するには、ID に次のアクセス許可が必要です。
- バッチ エンドポイント/デプロイを読み取る。
- バッチ推論エンドポイント/デプロイでジョブを作成する。
- 実験/実行を作成する。
- データ ストアとの間で読み取りと書き込みを行う。
- データストア シークレットを一覧表示する。
RBAC のアクセス許可の詳細な一覧については、「バッチ エンドポイントの呼び出し用に RBAC を構成する」を参照してください。
重要
データ ストアの構成方法によっては、バッチ エンドポイントの呼び出しに使用される ID は、基になるデータの読み取りには使用されない場合があります。 詳細については、「データ アクセス用にコンピューティング クラスターを構成する」を参照してください。
さまざまな種類の資格情報を使用してジョブを実行する方法
次の例では、さまざまな種類の資格情報を使用してバッチ デプロイ ジョブを開始するさまざまな方法を示します。
重要
プライベート リンクが有効なワークスペースで作業している場合、Azure Machine Learning Studio の UI からバッチ エンドポイントを呼び出すことはできません。 代わりに、Azure Machine Learning CLI v2 を使用してジョブを作成してください。
前提条件
- この例は、モデルがバッチ エンドポイントとして正しくデプロイされていることを前提としています。 具体的には、バッチ デプロイでの MLflow モデルの使用に関するチュートリアルで作成した "心臓病分類器" を使います。
ユーザーの資格情報を使用してジョブを実行する
この場合は、現在ログインしているユーザーの ID を使ってバッチ エンドポイントを実行します。 次の手順のようにします。
Azure CLI を使用して、対話型認証またはデバイス コード認証を使用してログインします。
az login認証が完了したら、次のコマンドを使用してバッチ デプロイ ジョブを実行します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
サービス プリンシパルを使用してジョブを実行する
この場合、Microsoft Entra ID で既に作成されているサービス プリンシパルを使って、バッチ エンドポイントを実行します。 認証を完了するには、認証を実行するためのシークレットを作成する必要があります。 次の手順のようにします。
「オプション 3: 新しいクライアント シークレットを作成する」の説明に従って、認証に使うシークレットを作成します。
サービス プリンシパルを使って認証を行うには、次のコマンドを使います。 詳細については、「Azure CLI を使用してサインインする」を参照してください。
az login --service-principal \ --tenant <tenant> \ -u <app-id> \ -p <password-or-cert>認証が完了したら、次のコマンドを使用してバッチ デプロイ ジョブを実行します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/
マネージド ID を使用してジョブを実行する
マネージド ID を使って、バッチ エンドポイントとデプロイを呼び出すことができます。 この管理 ID はバッチ エンドポイントに属しているのではなく、エンドポイントを実行するために使われる ID であり、したがってバッチ ジョブを作成することに注意してください。 このシナリオでは、ユーザー割り当て ID とシステム割り当て ID の両方を使用できます。
Azure リソースのマネージド ID 用に構成されたリソースでは、マネージド ID を使用してサインインできます。 リソースの ID を使用したサインインは、--identity フラグを介して行われます。 詳細については、「Azure CLI を使用してサインインする」を参照してください。
az login --identity
認証が完了したら、次のコマンドを使用してバッチ デプロイ ジョブを実行します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
バッチ エンドポイントの呼び出し用に RBAC を構成する
バッチ エンドポイントにより、コンシューマーがジョブの生成に使用できる永続的な API が公開されます。 呼び出し元は、これらのジョブを生成できるように適切なアクセス許可を要求します。 組み込みのセキュリティ ロールのいずれかを使用することも、目的に合わせてカスタム ロールを作成することもできます。
バッチ エンドポイントを正常に呼び出すには、エンドポイントの呼び出しに使用される ID に次の明示的なアクションを許可する必要があります。 Azure ロールを割り当てる手順については、「Azure ロールを割り当てる手順」を参照してください。
"actions": [
"Microsoft.MachineLearningServices/workspaces/read",
"Microsoft.MachineLearningServices/workspaces/data/versions/write",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/write",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/write",
"Microsoft.MachineLearningServices/workspaces/datastores/read",
"Microsoft.MachineLearningServices/workspaces/datastores/write",
"Microsoft.MachineLearningServices/workspaces/datastores/listsecrets/action",
"Microsoft.MachineLearningServices/workspaces/listStorageAccountKeys/action",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/jobs/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/jobs/write",
"Microsoft.MachineLearningServices/workspaces/computes/read",
"Microsoft.MachineLearningServices/workspaces/computes/listKeys/action",
"Microsoft.MachineLearningServices/workspaces/metadata/secrets/read",
"Microsoft.MachineLearningServices/workspaces/metadata/snapshots/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/write",
"Microsoft.MachineLearningServices/workspaces/experiments/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/submit/action",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/write",
"Microsoft.MachineLearningServices/workspaces/metrics/resource/write",
"Microsoft.MachineLearningServices/workspaces/modules/read",
"Microsoft.MachineLearningServices/workspaces/models/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/write",
"Microsoft.MachineLearningServices/workspaces/environments/read",
"Microsoft.MachineLearningServices/workspaces/environments/write",
"Microsoft.MachineLearningServices/workspaces/environments/build/action",
"Microsoft.MachineLearningServices/workspaces/environments/readSecrets/action"
]
データ アクセス用にコンピューティング クラスターを構成する
バッチ エンドポイントを使用すると、承認されたユーザーのみがバッチ デプロイを呼び出してジョブを生成できるようになります。 ただし、入力データの構成方法によっては、基になるデータの読み取りに他の資格情報を使用できます。 次の表を使用して、使用される資格情報を理解します。
| データ入力の種類 | ストア内の資格情報 | 使用される資格情報 | アクセス許可の付与 |
|---|---|---|---|
| データ ストア | はい | ワークスペース内のデータ ストアの資格情報 | アクセス キーまたは SAS |
| データ資産 | はい | ワークスペース内のデータ ストアの資格情報 | アクセス キーまたは SAS |
| データ ストア | いいえ | ジョブの ID + コンピューティング クラスターのマネージド ID | RBAC |
| データ資産 | いいえ | ジョブの ID + コンピューティング クラスターのマネージド ID | RBAC |
| Azure Blob Storage (アジュール・ブロブ・ストレージ) | 適用しない | ジョブの ID + コンピューティング クラスターのマネージド ID | RBAC |
| Azure Data Lake Storage Gen1 | 適用しない | ジョブの ID + コンピューティング クラスターのマネージド ID | POSIX |
| Azure Data Lake Storage Gen2 | 適用しない | ジョブの ID + コンピューティング クラスターのマネージド ID | POSIX と RBAC |
表内の「ジョブの ID + コンピューティング クラスターのマネージド ID」と表示されている項目については、マウントとストレージ アカウントの構成にコンピューティング クラスターのマネージド ID が使われます。 ただし、ジョブの ID は、基になるデータを読み取るために引き続き使用され、きめ細かいアクセス制御を実現します。 つまり、ストレージからデータを正常に読み取るには、デプロイが実行されているコンピューティング クラスターのマネージド ID に、少なくともストレージ アカウントへのストレージ BLOB データ閲覧者アクセス権が必要になります。
データ アクセス用にコンピューティング クラスターを構成するには、次の手順を実行します。
[Azure Machine Learning Studio] に移動します。
[コンピューティング]、[コンピューティング クラスター] の順に移動します。
デプロイで使用しているコンピューティング クラスターを選択します。 このアクションにより、コンピューティング クラスターの [詳細] ページが開きます。
マネージド ID をコンピューティング クラスターに割り当てます。
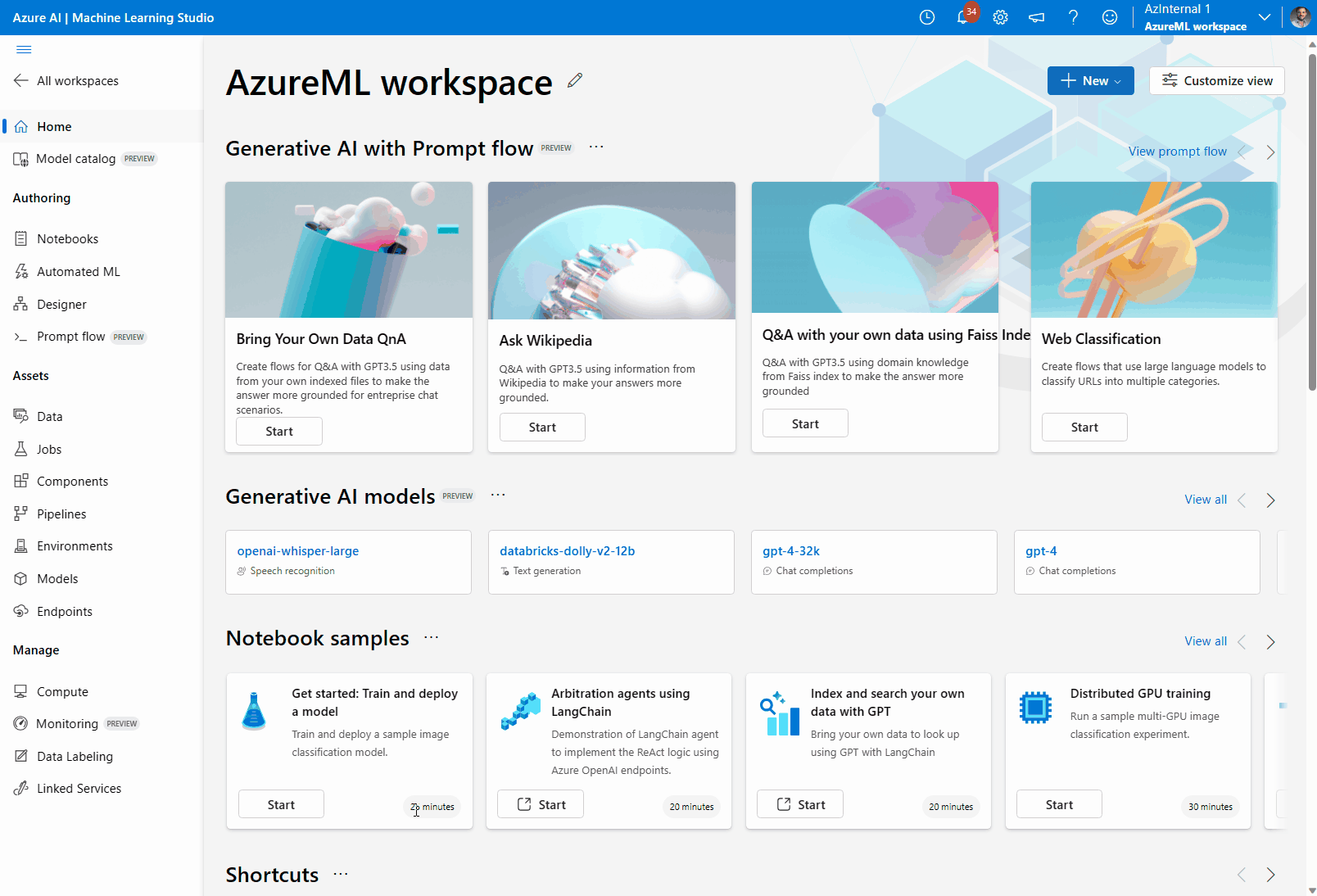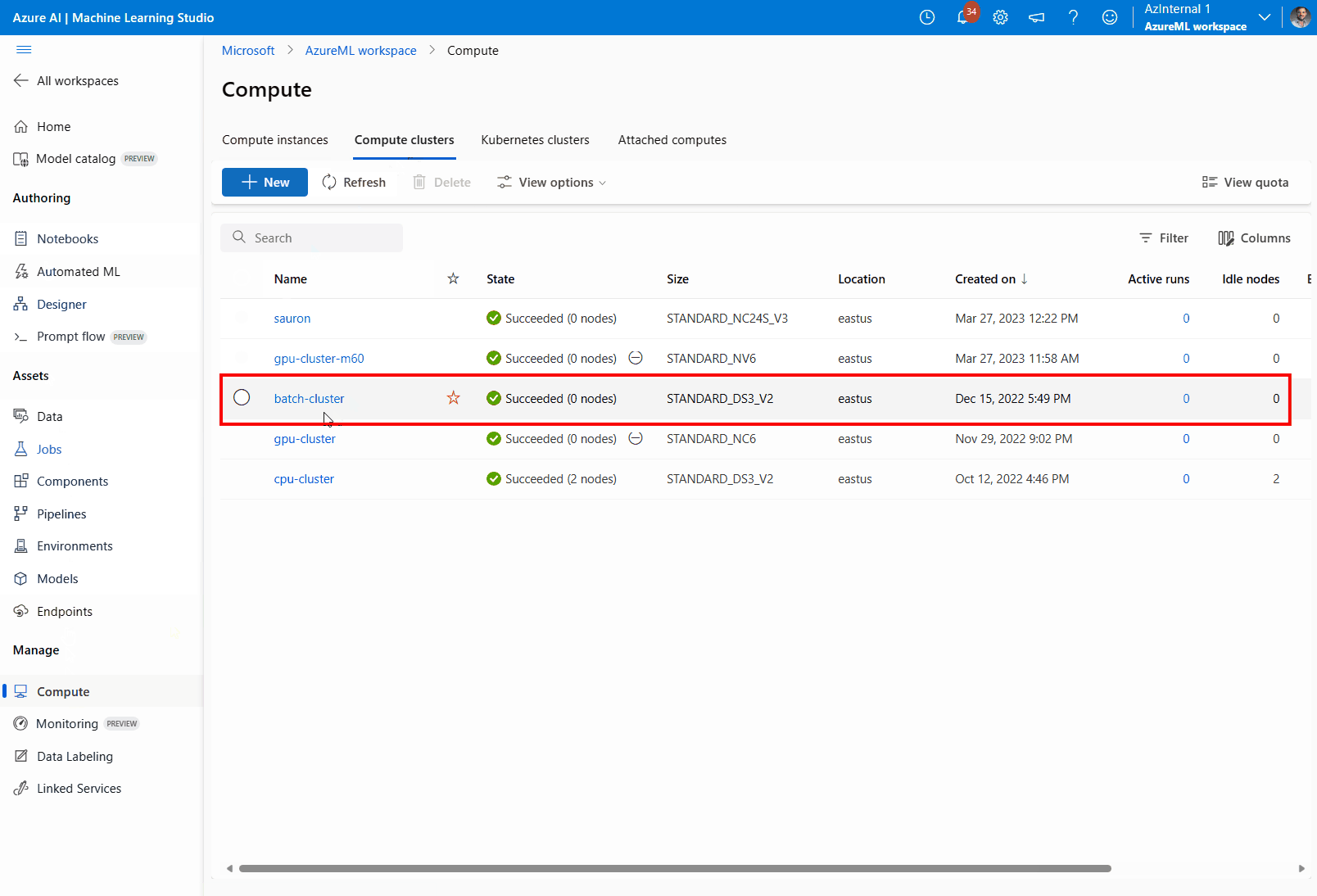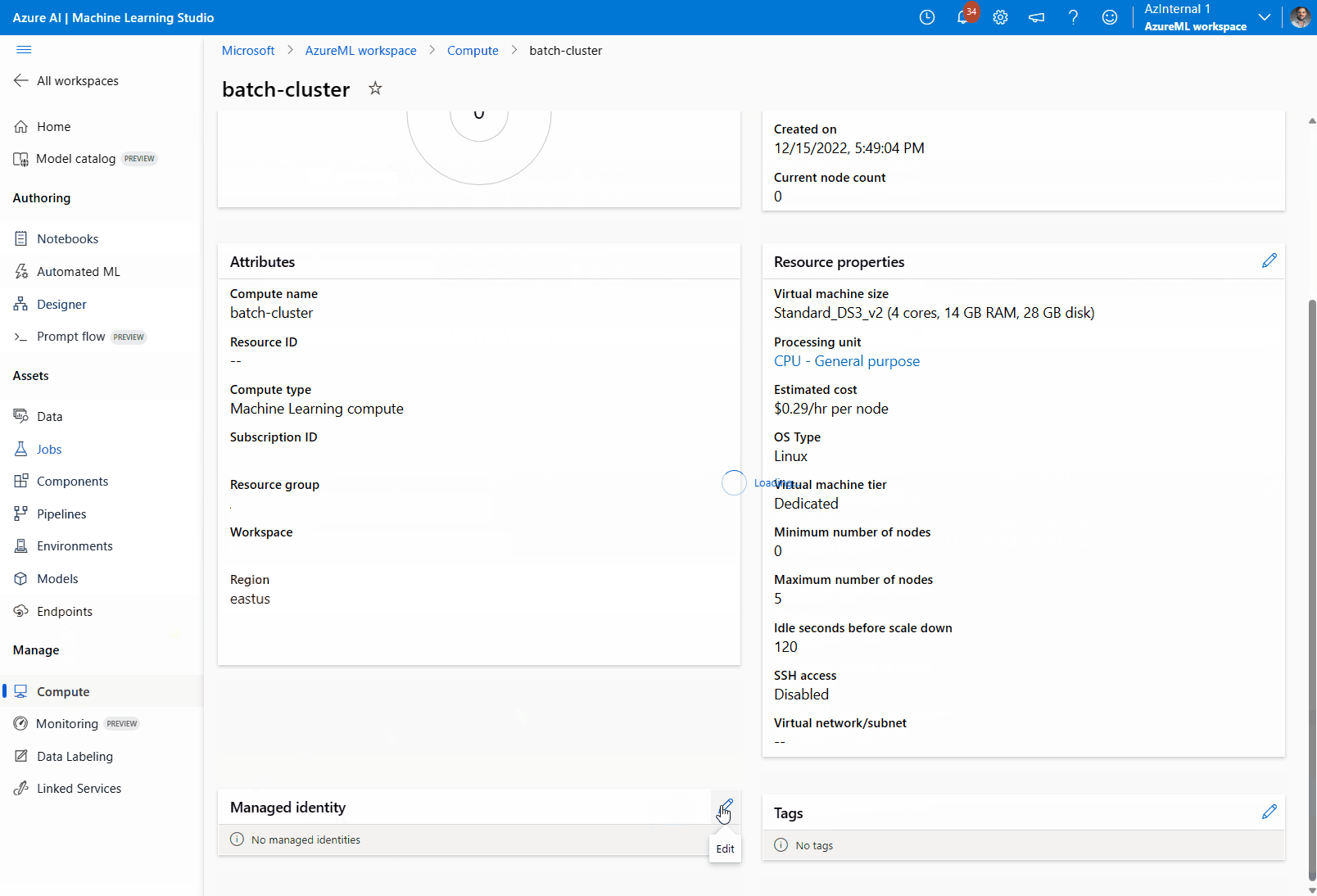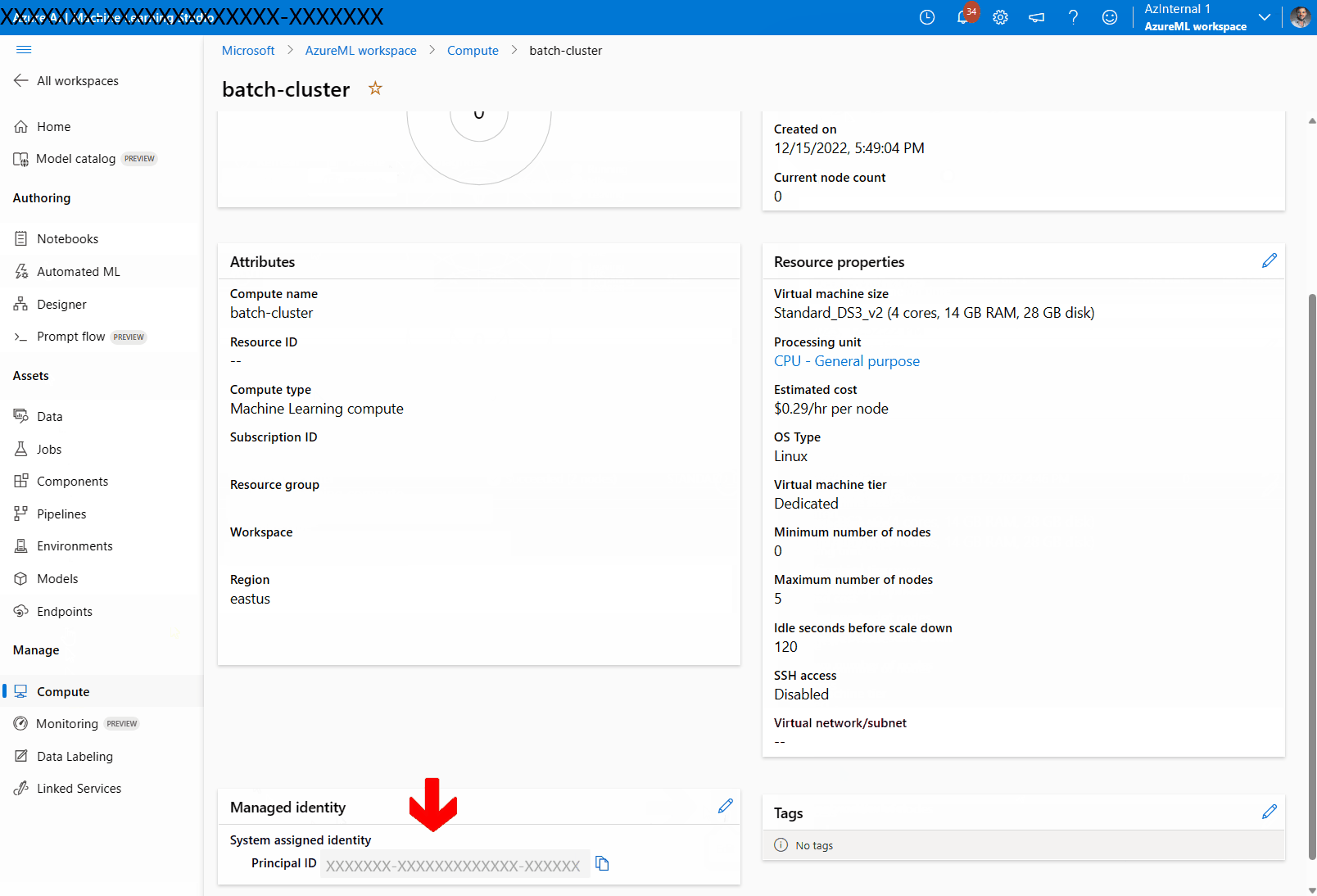
ページの [マネージド ID] セクションに移動し、コンピューティングにマネージド ID が割り当てられているかどうかを確認します。 そうでない場合は、鉛筆アイコンを選択してマネージド ID を編集します。
[ マネージド ID の割り当て ] の横にあるスライダーを選択して有効にし、必要に応じて構成します。 システム割り当てマネージド ID またはユーザー割り当てマネージド ID を使用できます。 システム割り当てマネージド ID を使っている場合は、"[ワークスペース名]/computes/[コンピューティング クラスター名]" という名前です。
変更を保存します。
Azure portal に移動し、データが配置されている関連ストレージ アカウントに移動します。 データ入力がデータ資産またはデータ ストアの場合は、それらの資産が配置されているストレージ アカウントを探します。
ストレージ アカウントでストレージ BLOB データ閲覧者のアクセス レベルを割り当てます。
[アクセス制御 (IAM)] セクションに移動します。
[ロールの割り当て] タブを選び、[追加]>[ロールの割り当て] をクリックします。
ストレージ BLOB データ閲覧者というロールを探して選び、[次へ] をクリックします。
[メンバーの選択] をクリックします。
作成したマネージド ID を探します。 システム割り当てマネージド ID を使っている場合は、"[ワークスペース名]/computes/[コンピューティング クラスター名]" という名前です。
アカウントを追加し、ウィザードを完了します。
エンドポイントは、選んだストレージ アカウントからジョブと入力データを受け取る準備が整いました。