重要
このページには、プレビュー段階にある Kubernetes デプロイ マニフェストを使用して Azure IoT Operations コンポーネントを管理する手順が含まれます。 この機能はいくつかの制限を設けて提供されており、運用環境のワークロードには使用しないでください。
ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用される法律条項については、「Microsoft Azure プレビューの追加使用条件」を参照してください。
データ フローとは、データがソースから宛先までたどるパスであり、必要に応じて変換が行われます。 データ フローのカスタム リソースを作成するか、操作エクスペリエンス Web UI を使用して 、データ フロー を構成できます。 データ フローは次の 3 つの部分で構成されます: ソース、変換、宛先。

ソースと宛先を定義するには、データ フロー エンドポイントを構成する必要があります。 変換は省略可能であり、データのエンリッチメント、データのフィルター処理、データの別のフィールドへのマッピングなどの操作を含めることができます。
Azure IoT Operations の操作エクスペリエンスを使用して、データ フローを作成できます。 操作エクスペリエンスには、データ フローを構成するためのビジュアル インターフェイスが用意されています。 Bicep を使用して Bicep ファイルを使用してデータ フローを作成したり、Kubernetes を使用して YAML ファイルを使用してデータ フローを作成したりすることもできます。
ソース、変換、宛先を構成する方法については、引き続きお読みください。
前提条件
既定のデータ フロー プロファイルとエンドポイントを使用して Azure IoT Operations のインスタンスが作成されたら、すぐにデータ フローを展開できます。 ただし、データ フロー プロファイルとエンドポイントを構成してデータ フローをカスタマイズしたい場合があります。
データ フロー プロファイル
データ フローに複数の異なるスケーリング設定が必要ない場合は、Azure IoT Operations が提供する既定のデータ フロー プロファイルを使用します。 新しいデータ フロー プロファイルを構成する方法については、「データ フロー プロファイルの 構成」を参照してください。
データ フロー エンドポイント
データ フローのソースと宛先を構成するには、データ フロー エンドポイントが必要です。 すぐに開始するには、ローカル MQTT ブローカー の既定のデータ フロー エンドポイントを使用できます。 Kafka、Event Hubs、Azure Data Lake Storage などの他の種類のデータ フロー エンドポイントを作成することもできます。 各種のデータ フロー エンドポイントを構成する方法については、「データ フロー エンドポイントを構成する」を参照してください。
作業の開始
前提条件を満たしたら、データ フローの作成を開始できます。
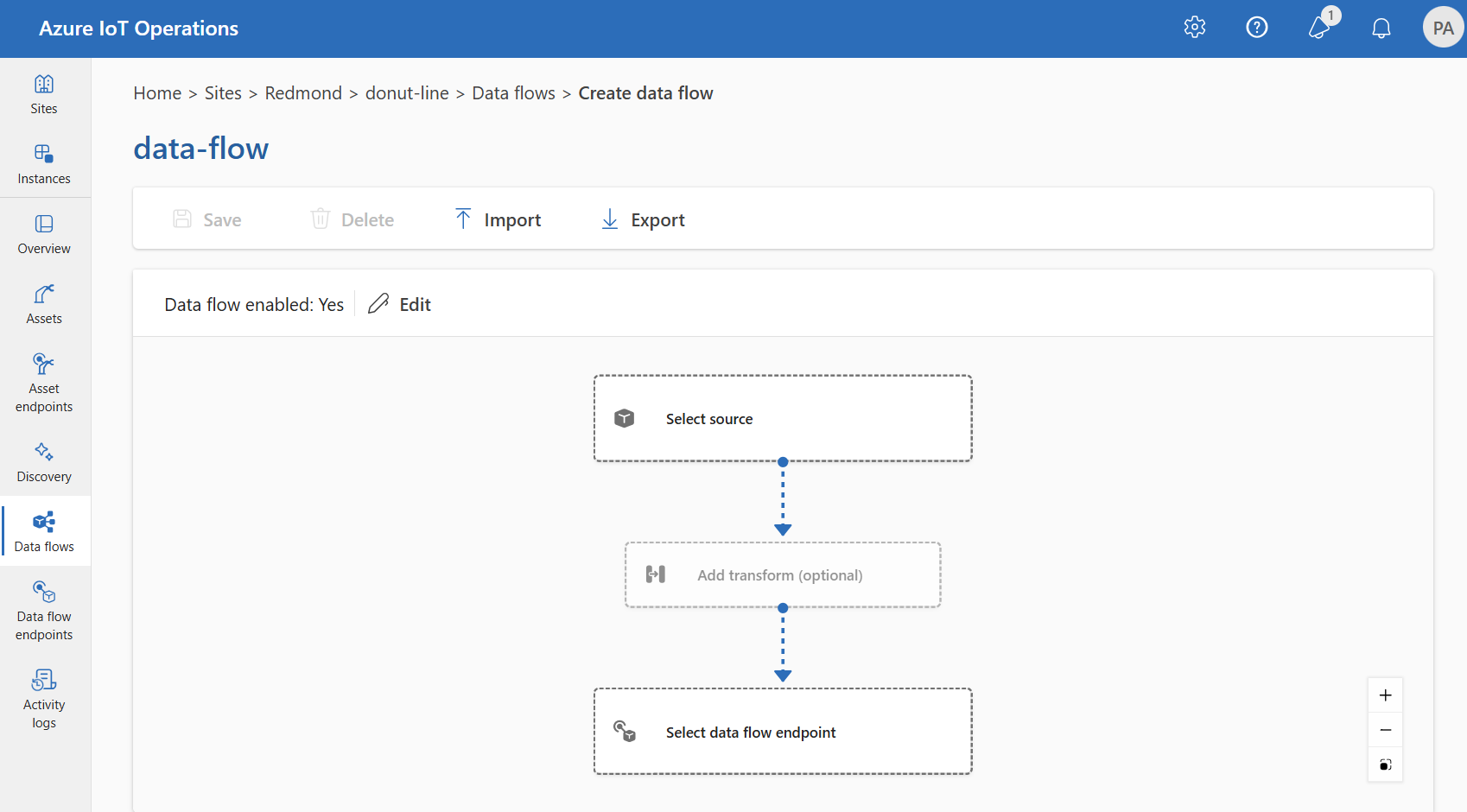
操作エクスペリエンスでデータ フローを作成するには、[データ フロー]>[データ フローを作成する] を選択します。
プレースホルダー名 new-data-flow を選択して、データ フローのプロパティを設定します。 データ フローの名前を入力し、使用するデータ フロー プロファイルを選択します。 既定では、既定のデータ フロー プロファイルが選択されています。 データ フロー プロファイルの詳細については、「データ フロー プロファイルの構成」を参照してください。

重要
データ フロー プロファイルは、データ フローの作成時にのみ選択できます。 データ フローの作成後にデータ フロー プロファイルを変更することはできません。
既存のデータ フローのデータ フロー プロファイルを変更する場合は、元のデータ フローを削除し、新しいデータ フロー プロファイルを使用して新しいデータ フロー を作成します。
データ フローダイアグラムの項目を選択して、データ フローのソース、変換、および変換先のエンドポイントを構成します。
az iot ops dataflow apply コマンドを使用して、データ フローを作成または変更します。
az iot ops dataflow apply --resource-group <ResourceGroupName> --instance <AioInstanceName> --profile <DataflowProfileName> --name <DataflowName> --config-file <ConfigFilePathAndName>
--config-file パラメーターは、リソース プロパティを含む JSON 構成ファイルのパスとファイル名です。
この例では、ユーザーのホーム ディレクトリに格納されている次のコンテンツを含む data-flow.json という名前の構成ファイルを想定しています。
{
"mode": "Enabled",
"operations": [
{
"operationType": "Source",
"sourceSettings": {
// See source configuration section
}
},
{
"operationType": "BuiltInTransformation",
"builtInTransformationSettings": {
// See transformation configuration section
}
},
{
"operationType": "Destination",
"destinationSettings": {
// See destination configuration section
}
}
]
}
既定のデータフロー プロファイルを使用してデータ フローを作成または更新するコマンドの例を次に示します。
az iot ops dataflow apply --resource-group myResourceGroup --instance myAioInstance --profile default --name data-flow --config-file ~/data-flow.json
Bicep .bicep ファイルを作成して、データ フローの作成を開始します。 この例では、ソース、変換、宛先の構成を含むデータ フローの構造を示します。
param aioInstanceName string = '<AIO_INSTANCE_NAME>'
param customLocationName string = '<CUSTOM_LOCATION_NAME>'
param dataflowName string = '<DATAFLOW_NAME>'
resource aioInstance 'Microsoft.IoTOperations/instances@2024-11-01' existing = {
name: aioInstanceName
}
resource customLocation 'Microsoft.ExtendedLocation/customLocations@2021-08-31-preview' existing = {
name: customLocationName
}
resource defaultDataflowEndpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
// Pointer to the default data flow profile
resource defaultDataflowProfile 'Microsoft.IoTOperations/instances/dataflowProfiles@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
resource dataflow 'Microsoft.IoTOperations/instances/dataflowProfiles/dataflows@2024-11-01' = {
// Reference to the parent data flow profile, the default profile in this case
// Same usage as profileRef in Kubernetes YAML
parent: defaultDataflowProfile
name: dataflowName
extendedLocation: {
name: customLocation.id
type: 'CustomLocation'
}
properties: {
mode: 'Enabled'
operations: [
{
operationType: 'Source'
sourceSettings: {
// See source configuration section
}
}
// Transformation optional
{
operationType: 'BuiltInTransformation'
builtInTransformationSettings: {
// See transformation configuration section
}
}
{
operationType: 'Destination'
destinationSettings: {
// See destination configuration section
}
}
]
}
}
Kubernetes マニフェスト .yaml ファイルを作成して、データ フローの作成を開始します。 この例では、ソース、変換、宛先の構成を含むデータ フローの構造を示します。
apiVersion: connectivity.iotoperations.azure.com/v1
kind: Dataflow
metadata:
name: <DATAFLOW_NAME>
namespace: azure-iot-operations
spec:
# Reference to the default data flow profile
# This field is required when configuring via Kubernetes YAML
# The syntax is different when using Bicep
profileRef: default
mode: Enabled
operations:
- operationType: Source
sourceSettings:
# See source configuration section
# Transformation optional
- operationType: BuiltInTransformation
builtInTransformationSettings:
# See transformation configuration section
- operationType: Destination
destinationSettings:
# See destination configuration section
データ フローの操作の種類を構成する方法については、以下のセクションを参照してください。
ソース
データ フローのソースを構成するには、エンドポイント参照とエンドポイントのデータ ソースの一覧を指定します。 データ フローのソースとして、次のいずれかのオプションを選択します。
既定のエンドポイントがソースとして使用されていない場合は、宛先として使用する必要があります。 ローカル MQTT ブローカー エンドポイントの使用の詳細については、 データ フローでローカル MQTT ブローカー エンドポイントを使用する必要がある方法に関するページを参照してください。
オプション 1: 既定のメッセージ ブローカー エンドポイントをソースとして使用する
[ソースの詳細] で、[メッセージ ブローカー] を選択します。
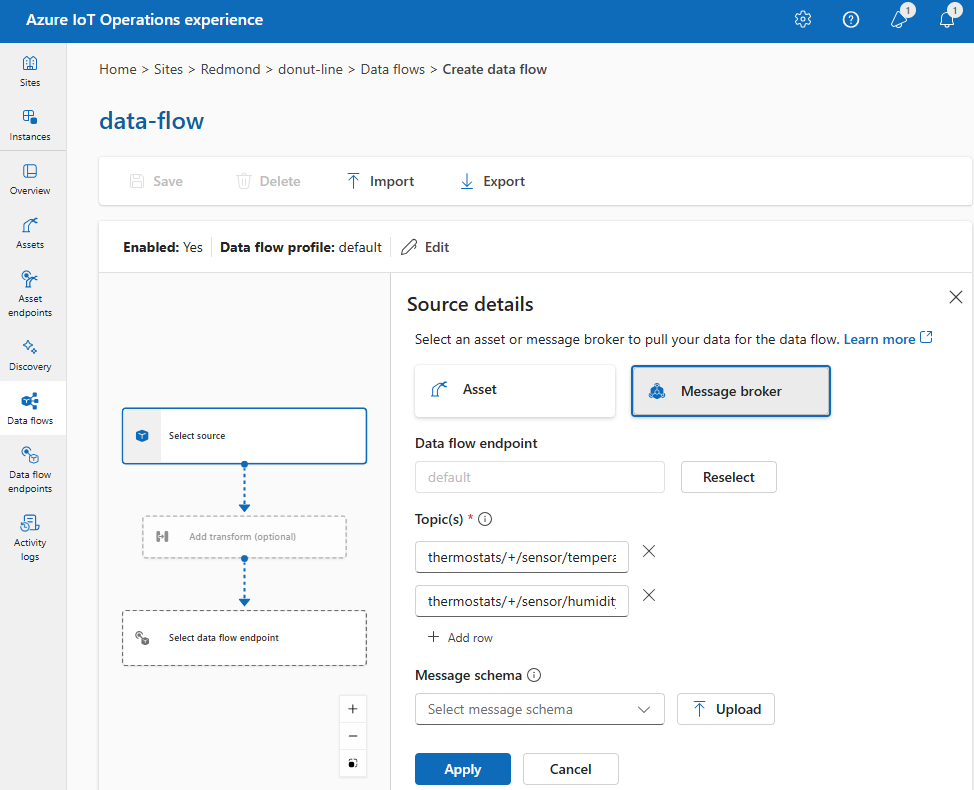
メッセージ ブローカー ソースについて次の設定を入力します。
| 設定 |
説明 |
| データ フロー エンドポイント |
既定の MQTT メッセージ ブローカー エンドポイントを使用するには、"既定値" を選択します。 |
| トピック |
受信メッセージをサブスクライブするための MQTT トピック フィルター。
[トピック]>[行の追加] を使用して、複数のトピックを追加します。 トピックの詳細については、「MQTT または Kafka トピックの構成」を参照してください。 |
| メッセージ スキーマ |
受信メッセージの逆シリアル化に使用するスキーマ。 「データを逆シリアル化するスキーマを指定する」を参照してください。 |
適用を選択します。
既定の MQTT ブローカー エンドポイントのソース エンドポイント構成の例を次に示します。
{
"operationType": "Source",
"sourceSettings": {
"endpointRef": "default",
"dataSources": [
"thermostats/+/sensor/temperature/#",
"humidifiers/+/sensor/humidity/#"
],
"endpointRef": "default"
}
}
メッセージ ブローカー エンドポイントは、Bicep ファイルで構成されます。 たとえば、次のエンドポイントはデータ フローのソースです。
sourceSettings: {
endpointRef: 'default'
dataSources: [
'thermostats/+/sensor/temperature/#'
'humidifiers/+/sensor/humidity/#'
]
}
たとえば、1 つのメッセージ ブローカー エンドポイントと 2 つのトピック フィルターを使ってソースを構成するには、次の構成を使用します。
sourceSettings:
endpointRef: default
dataSources:
- thermostats/+/sensor/temperature/#
- humidifiers/+/sensor/humidity/#
dataSources ではエンドポイント構成を変更せずに MQTT または Kafka トピックを指定できるため、トピックが異なる場合でも複数のデータ フローに対してエンドポイントを再利用できます。 詳細については、「データソースを構成する」を参照してください。
オプション 2: 資産をソースとして使用する
資産をデータ フローのソースとして使用できます。 資産をソースとして使用することは、操作エクスペリエンスでのみ使用できます。
[ソースの詳細] で、[資産] を選択します。
ソース エンドポイントとして使用する資産を選択します。
[続行] を選択します。
選択した資産のデータポイントの一覧が表示されます。

[適用] を選択して、資産をソース エンドポイントとして使用します。
資産のソースとしての構成は、操作エクスペリエンスでのみ可能です。
資産のソースとしての構成は、操作エクスペリエンスでのみ可能です。
資産のソースとしての構成は、操作エクスペリエンスでのみ可能です。
資産をソースとして使用する場合、資産定義はデータ フローのスキーマを推論するために使用されます。 資産定義には、資産のデータ ポイントのスキーマが含まれます。 詳細については、「資産の構成をリモートで管理する」を参照してください。
構成が完了すると、資産からのデータは、ローカル MQTT ブローカーを介してデータ フローに到達します。 そのため、ソースとして資産を使用する場合、データ フローはローカル MQTT ブローカーの既定のエンドポイントを実際のソースとして使用します。
オプション 3: カスタム MQTT または Kafka データ フロー エンドポイントをソースとして使用する
カスタム MQTT または Kafka データ フロー エンドポイントを作成した場合 (たとえば、Event Grid または Event Hubs で使用する場合)、データ フローのソースとして使用できます。 Data Lake や Fabric OneLake などのストレージ タイプのエンドポイントは、ソースとして使用できないことに注意してください。
[ソースの詳細] で、[メッセージ ブローカー] を選択します。
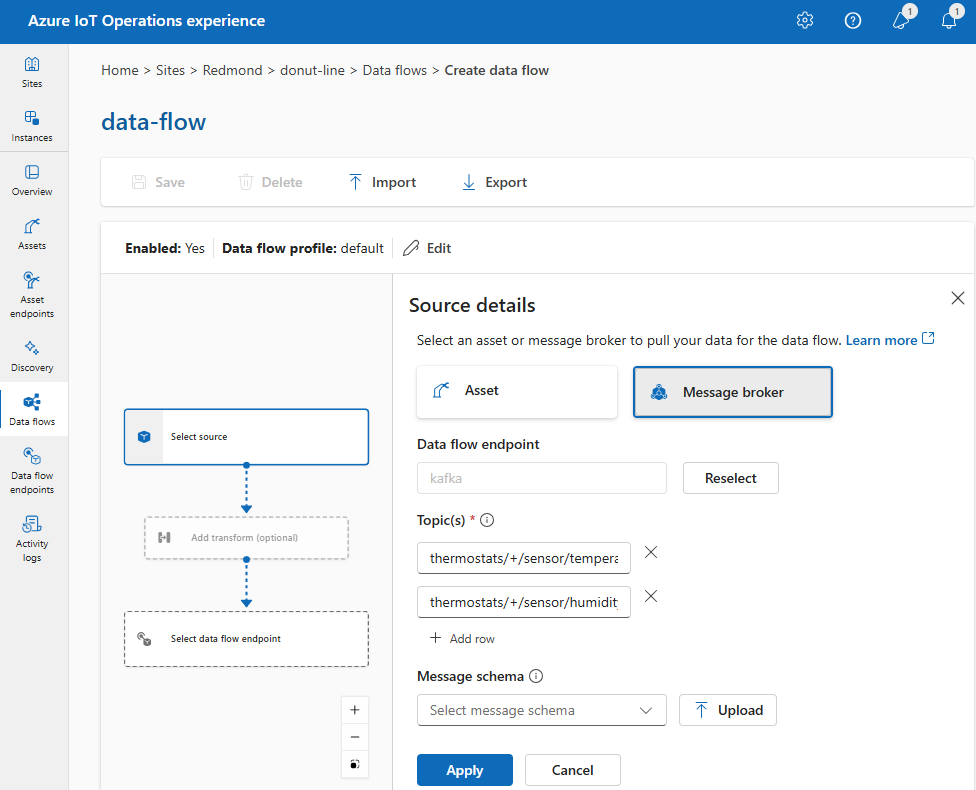
メッセージ ブローカー ソースについて次の設定を入力します。
適用を選択します。
プレースホルダーの値をカスタム エンドポイントの名前とトピックに置き換えます。
{
"operationType": "Source",
"sourceSettings": {
"endpointRef": "<CUSTOM_ENDPOINT_NAME>",
"dataSources": [
"<TOPIC_1>",
"<TOPIC_2>"
]
}
}
プレースホルダーの値をカスタム エンドポイントの名前とトピックに置き換えます。
sourceSettings: {
endpointRef: '<CUSTOM_ENDPOINT_NAME>'
dataSources: [
'<TOPIC_1>'
'<TOPIC_2>'
// See section on configuring MQTT or Kafka topics for more information
]
}
プレースホルダーの値をカスタム エンドポイントの名前とトピックに置き換えます。
sourceSettings:
endpointRef: <CUSTOM_ENDPOINT_NAME>
dataSources:
- <TOPIC_1>
- <TOPIC_2>
# See section on configuring MQTT or Kafka topics for more information
データ フロー エンドポイントの構成を変更しなくても、ソースに複数の MQTT または Kafka トピックを指定できます。 この柔軟性により、トピックが異なる場合でも、複数のデータ フロー間で同じエンドポイントを再利用できます。 詳細については、データ フロー エンドポイントの再利用に関するセクションを参照してください。
MQTT のトピック
ソースが MQTT (Event Grid を含む) エンドポイントの場合は、MQTT トピック フィルターを使用して受信メッセージをサブスクライブできます。 トピック フィルターには、複数のトピックをサブスクライブするためのワイルドカードを含めることができます。 たとえば、 thermostats/+/sensor/temperature/# はサーモスタットからのすべての温度センサー メッセージをサブスクライブします。 MQTT トピック フィルターを構成するには:
操作エクスペリエンスのデータ フローの [ソースの詳細] で [メッセージ ブローカー] を選択してから、[トピック] フィールドを使用して、受信メッセージをサブスクライブするための MQTT トピック フィルターを指定します。
[行の追加] を選択し、新しいトピックを入力することで、複数の MQTT トピックを追加できます。
{
"operationType": "Source",
"sourceSettings": {
"endpointRef": "<MESSAGE_BROKER_ENDPOINT_NAME>",
"dataSources": [
"<TOPIC_FILTER_1>",
"<TOPIC_FILTER_2>"
// Add more topic filters as needed
]
}
}
ワイルドカードを含む複数の MQTT トピック フィルターの例:
{
"operationType": "Source",
"sourceSettings": {
"endpointRef": "default",
"dataSources": [
"thermostats/+/sensor/temperature/#",
"humidifiers/+/sensor/humidity/#"
]
}
}
ここでは、ワイルドカード + を使用して、thermostats と humidifiers トピックの下にあるすべてのデバイスを選択します。
#ワイルドカードは、temperatureトピックとhumidityトピックのすべてのサブトピックのすべてのセンサー メッセージを選択するために使用されます。
sourceSettings: {
endpointRef: '<MESSAGE_BROKER_ENDPOINT_NAME>'
dataSources: [
'<TOPIC_FILTER_1>'
'<TOPIC_FILTER_2>'
// Add more topic filters as needed
]
}
ワイルドカードを含む複数の MQTT トピック フィルターの例:
sourceSettings: {
endpointRef: 'default'
dataSources: [
'thermostats/+/sensor/temperature/#'
'humidifiers/+/sensor/humidity/#'
]
}
ここでは、ワイルドカード + を使用して、thermostats と humidifiers トピックの下にあるすべてのデバイスを選択します。
#ワイルドカードは、temperatureトピックとhumidityトピックのすべてのサブトピックのすべてのセンサー メッセージを選択するために使用されます。
sourceSettings:
endpointRef: <ENDPOINT_NAME>
dataSources:
- <TOPIC_FILTER_1>
- <TOPIC_FILTER_2>
# Add more topic filters as needed
ワイルドカードを含む複数のトピック フィルターの例:
sourceSettings:
endpointRef: default
dataSources:
- thermostats/+/sensor/temperature/#
- humidifiers/+/sensor/humidity/#
ここでは、ワイルドカード + を使用して、thermostats と humidifiers トピックの下にあるすべてのデバイスを選択します。
#ワイルドカードは、temperatureおよびhumidityトピックのすべてのサブトピックのすべてのメッセージを選択するために使用されます。
共有サブスクリプション
メッセージ ブローカー ソースで共有サブスクリプションを使用するには、$shared/<GROUP_NAME>/<TOPIC_FILTER> の形式で共有サブスクリプション トピックを指定します。
操作エクスペリエンスのデータ フローの [ソースの詳細] で、[メッセージ ブローカー] を選択し、[トピック] フィールドを使用して共有サブスクリプション グループとトピックを指定します。
{
"operationType": "Source",
"sourceSettings": {
"dataSources": [
"$shared/<GROUP_NAME>/<TOPIC_FILTER>"
]
}
}
sourceSettings: {
dataSources: [
'$shared/<GROUP_NAME>/<TOPIC_FILTER>'
]
}
sourceSettings:
dataSources:
- $shared/<GROUP_NAME>/<TOPIC_FILTER>
データ フロー プロファイルのインスタンス数が 1 より大きい場合は、メッセージ ブローカー ソースを使用するすべてのデータ フローに対して共有サブスクリプションが自動で有効になります。 この場合、$shared プレフィックスが追加され、共有サブスクリプション グループ名が自動的に生成されます。 たとえば、インスタンス数が 3 のデータ フロー プロファイルがあり、データ フローがトピック topic1 と topic2 で構成されたソースとしてメッセージ ブローカー エンドポイントを使用している場合、それらは自動的に共有サブスクリプションに $shared/<GENERATED_GROUP_NAME>/topic1 および $shared/<GENERATED_GROUP_NAME>/topic2 として変換されます。
構成内に $shared/mygroup/topic という名前のトピックを明示的に作成できます。 ただし、$shared プレフィックスは必要に応じて自動的に追加されるため、$shared トピックを明示的に追加することはお勧めしません。 データ フローが設定されていない場合は、グループ名を使用して最適化を行うことができます。 たとえば、$share は設定されておらず、データ フローはトピック名に対してのみ動作する必要がある場合があります。
重要
インスタンス数が 1 つ以上のときに共有サブスクリプションを必要とするデータ フローは、Event Grid MQTT ブローカーをソースとして使用する場合に、共有サブスクリプションをサポートしていないため重要となります。 メッセージの欠落を回避するため、Event Grid MQTT ブローカーをソースとして使用するときは、データ フロー プロファイル インスタンス数を 1 に設定します。 これは、データ フローがサブスクライバーで、クラウドからメッセージを受信する場合です。
Kafka トピック
ソースが Kafka (Event Hubs を含む) エンドポイントの場合は、受信メッセージをサブスクライブする個々の Kafka トピックを指定します。 ワイルドカードはサポートされていないため、各トピックを静的に指定する必要があります。
注
Kafka エンドポイント経由で Event Hubs を使用する場合、名前空間内の個々のイベント ハブは Kafka トピックです。 たとえば、thermostats と humidifiers の 2 つのイベント ハブを含む Event Hubs 名前空間がある場合、各イベント ハブを Kafka トピックとして指定できます。
Kafka トピックを構成するには:
操作エクスペリエンスのデータ フローの [ソースの詳細] で [メッセージ ブローカー] を選択してから、[トピック] フィールドを使用して、受信メッセージをサブスクライブするための Kafka トピック フィルターを指定します。
注
操作エクスペリエンスで指定できるトピック フィルターは 1 つだけです。 複数のトピック フィルターを使用するには、Bicep または Kubernetes を使用してください。
{
"operationType": "Source",
"sourceSettings": {
"endpointRef": "<KAFKA_ENDPOINT_NAME>",
"dataSources": [
"<KAFKA_TOPIC_1>",
"<KAFKA_TOPIC_2>"
// Add more Kafka topics as needed
]
}
}
sourceSettings: {
endpointRef: '<KAFKA_ENDPOINT_NAME>'
dataSources: [
'<KAFKA_TOPIC_1>'
'<KAFKA_TOPIC_2>'
// Add more Kafka topics as needed
]
}
sourceSettings:
endpointRef: <KAFKA_ENDPOINT_NAME>
dataSources:
- <KAFKA_TOPIC_1>
- <KAFKA_TOPIC_2>
# Add more Kafka topics as needed
ソース スキーマを指定する
MQTT または Kafka をソースとして使用する場合は、操作エクスペリエンス Web UI でデータ ポイントの一覧を表示する スキーマ を指定できます。 受信メッセージの逆シリアル化および検証のためのスキーマの使用は、現在サポートされていません。
ソースが資産の場合、スキーマは資産定義から自動的に推論されます。
ソースからの受信メッセージを逆シリアル化するために使用するスキーマを構成するには:
操作エクスペリエンスのデータ フローの [ソースの詳細] で [メッセージ ブローカー] を選択し、[メッセージ スキーマ] フィールドを使用してスキーマを指定します。
[アップロード] ボタンを使用して、最初にスキーマ ファイルをアップロードできます。 詳細については、「メッセージ スキーマを理解する」を参照してください。
{
"operationType": "Source",
"sourceSettings": {
"endpointRef": "<ENDPOINT_NAME>",
"serializationFormat": "Json",
"schemaRef": "aio-sr://<SCHEMA_NAMESPACE>/<SCHEMA_NAME>:<VERSION>"
}
}
スキーマ レジストリを使用してスキーマを格納したら、それをデータ フロー構成で参照できます。
sourceSettings: {
serializationFormat: 'Json'
schemaRef: 'aio-sr://<SCHEMA_NAMESPACE>/<SCHEMA_NAME>:<VERSION>'
}
スキーマ レジストリを使用してスキーマを格納したら、それをデータ フロー構成で参照できます。
sourceSettings:
serializationFormat: Json
schemaRef: 'aio-sr://<SCHEMA_NAMESPACE>/<SCHEMA_NAME>:<VERSION>'
詳細については、「メッセージ スキーマを理解する」を参照してください。
変換操作では、宛先に送信する前にソースからのデータを変換できます。 変換は省略可能です。 データを変更する必要がない場合は、データ フロー構成に変換操作を含めないでください。 複数の変換は、構成で指定した順序に関係なく、段階的に連結されます。 ステージの順序は常に次のようになります。
-
エンリッチ: 一致するデータセットと条件を指定して、ソース データにデータを追加します。
-
フィルター: 条件に基づいてデータをフィルター処理します。
-
[マップ]、[コンピューティング]、[名前の変更]、または [新しいプロパティ] の追加: 省略可能な変換を使用して、あるフィールドから別のフィールドにデータを移動します。
このセクションでは、データ フロー変換の概要について説明します。 詳細については、「データ フローを使用してデータをマップする」、「データ フロー変換を使用してデータを変換する」、「データ フローを使用してデータをエンリッチする」を参照してください。
操作エクスペリエンスで、[データ フロー]>[変換の追加 (省略可能)] を選びます。

{
"operationType": "BuiltInTransformation",
"builtInTransformationSettings": {
"datasets": [
// See section on enriching data
],
"filter": [
// See section on filtering data
],
"map": [
// See section on mapping data
]
}
}
builtInTransformationSettings: {
datasets: [
// See section on enriching data
]
filter: [
// See section on filtering data
]
map: [
// See section on mapping data
]
}
builtInTransformationSettings:
datasets:
# See section on enriching data
filter:
# See section on filtering data
map:
# See section on mapping data
エンリッチ: 参照データを追加する
データをエンリッチするには、まず Azure IoT Operations の状態ストアに参照データセットを追加します。 データセットは、条件に基づいてソース データにさらにデータを追加するために使用されます。 条件は、データセット内のフィールドと一致するソース データ内のフィールドとして指定されます。
状態ストア CLI を使用して、状態ストアにサンプル データを読み込むことができます。 状態ストア内のキー名は、データ フロー構成のデータセットに対応します。
現在、"エンリッチ" ステージは操作エクスペリエンスではサポートされていません。
データをエンリッチするには、データ フロー構成で builtInTransformationSettings プロパティを使用できます。
datasets プロパティは、エンリッチメントに使用するデータセットを指定するために使用されます。
{
"operationType": "BuiltInTransformation",
"builtInTransformationSettings": {
"datasets": [
{
"key": "<DATASET_KEY>",
"inputs": [
"$source.<SOURCE_FIELD>" // ---------------- $1
"$context(<DATASET_KEY>).<DATASET_FIELD>" // - $2
],
"expression": "$1 == $2"
}
]
}
}
この例に、ソース データの deviceId フィールドを使用して、データセットの asset フィールドと一致させる方法を示しています。
builtInTransformationSettings: {
datasets: [
{
key: 'assetDataset'
inputs: [
'$source.deviceId' // ---------------- $1
'$context(assetDataset).asset' // ---- $2
]
expression: '$1 == $2'
}
]
}
たとえば、ソース データの deviceId フィールドを使用して、データセットの asset フィールドと一致させることができます。
builtInTransformationSettings:
datasets:
- key: assetDataset
inputs:
- $source.deviceId # ------------- $1
- $context(assetDataset).asset # - $2
expression: $1 == $2
データセットに asset フィールドを持つレコードがある場合は、次のようになります。
{
"asset": "thermostat1",
"___location": "room1",
"manufacturer": "Contoso"
}
deviceId と一致する thermostat1 フィールドを持つソースのデータには、フィルターとマップのステージで使用できる ___location と manufacturer のフィールドがあります。
条件構文の詳細については、「データ フローを使用してデータをエンリッチする」と「データ フローを使用したデータの変換」に関する記事を参照してください。
フィルター: 条件に基づいてデータをフィルター処理する
条件に基づいてデータをフィルター処理するには、filter ステージを使用できます。 条件は、値と一致するソース データ内のフィールドとして指定されます。
[変換 (省略可能)] で、[フィルター]>[追加] を選びます。

必要な設定を入力します。
| 設定 |
説明 |
| フィルターの条件 |
ソース データのフィールドに基づいてデータをフィルター処理する条件。 |
| 説明 |
フィルター条件の説明を入力します。 |
フィルター条件フィールドに「@」と入力するか、Ctrl + Space キーを押して、ドロップダウンからデータポイントを選択します。
MQTT メタデータ プロパティは、形式 @$metadata.user_properties.<property> または @$metadata.topic を使用して入力できます。
@$metadata.<header> 形式を使用して、$metadata ヘッダーを入力することもできます。
$metadata 構文は、メッセージ ヘッダーの一部である MQTT プロパティにのみ必要です。 詳細については、「フィールド参照」を参照してください。
条件では、ソース データのフィールドを使用できます。 たとえば、@temperature > 20 のようなフィルター条件を使用して、温度フィールドに基づいて 20 以下のデータをフィルター処理できます。
適用を選択します。
たとえば、ソース データの temperature フィールドを使用してデータをフィルター処理できます。
{
"operationType": "BuiltInTransformation",
"builtInTransformationSettings": {
"filter": [
{
"inputs": [
"$source.temperature ? $last" // ---------------- $1
],
"expression": "$1 > 20"
}
]
}
}
たとえば、ソース データの temperature フィールドを使用してデータをフィルター処理できます。
builtInTransformationSettings: {
filter: [
{
inputs: [
'temperature ? $last'
]
expression: '$1 > 20'
}
]
}
temperature フィールドが 20 より大きい場合、データは次のステージに渡されます。
temperature フィールドが 20 以下の場合、データはフィルター処理されます。
たとえば、ソース データの temperature フィールドを使用してデータをフィルター処理できます。
builtInTransformationSettings:
filter:
- inputs:
- temperature ? $last # - $1
expression: "$1 > 20"
temperature フィールドが 20 より大きい場合、データは次のステージに渡されます。
temperature フィールドが 20 以下の場合、データはフィルター処理されます。
マップ: あるフィールドから別のフィールドにデータを移動する
省略可能な変換を使用してデータを別のフィールドにマップするには、map 操作を使用できます。 変換は、ソース データのフィールドを使用する数式として指定されます。
操作エクスペリエンスでは、マッピングは現在 [コンピューティング]、[名前変更]、[新しいプロパティ] の各変換を使用してサポートされています。
コンピューティング
[コンピューティング] 変換を使用して、ソース データに数式を適用できます。 この操作は、ソース データに数式を適用し、結果フィールドを格納するために使用されます。
[変換 (省略可能)] で、[コンピューティング]>[追加] を選びます。

必要な設定を入力します。
| 設定 |
説明 |
| 数式を選択する |
ドロップダウンから既存の数式を選択するか、[カスタム] を選択して手動で数式を入力します。 |
| 出力 |
結果の出力表示名を指定します。 |
| 式 |
ソース データに適用する数式を入力します。 |
| 説明 |
変換の説明を入力します。 |
| 最後の既知の値 |
必要に応じて、現在の値が使用できない場合は、最後の既知の値を使用します。 |
[数式] フィールドに数式を入力するか、既存の数式を編集できます。 数式には、ソース データ内のフィールドを使用できます。 「@」と入力するか、Ctrl + Space キーを押して、ドロップダウンからデータポイントを選択します。 組み込みの数式の場合は、<dataflow> プレースホルダーを選択して、使用可能なデータ ポイントの一覧を表示します。
MQTT メタデータ プロパティは、形式 @$metadata.user_properties.<property> または @$metadata.topic を使用して入力できます。
@$metadata.<header> 形式を使用して、$metadata ヘッダーを入力することもできます。
$metadata 構文は、メッセージ ヘッダーの一部である MQTT プロパティにのみ必要です。 詳細については、「フィールド参照」を参照してください。
数式には、ソース データ内のフィールドを使用できます。 たとえば、ソース データの temperature フィールドを使用して温度を摂氏に変換し、それを temperatureCelsius 出力フィールドに格納できます。
適用を選択します。
名前の変更
[名前の変更] 変換を使用して、データポイントの名前を変更できます。 この操作は、ソース データ内のデータポイントの名前を新しい名前に変更するために使用されます。 新しい名前は、データ フローの後続のステージで使用できます。
[変換 (省略可能)] で、[名前の変更]>[追加] を選びます。

必要な設定を入力します。
| 設定 |
説明 |
| データポイント |
ドロップダウンからデータポイントを選択するか、$metadata ヘッダーを入力します。 |
| 新しいデータポイント名 |
データポイントの新しい名前を入力します。 |
| 説明 |
変換の説明を入力します。 |
MQTT メタデータ プロパティは、形式 @$metadata.user_properties.<property> または @$metadata.topic を使用して入力できます。
@$metadata.<header> 形式を使用して、$metadata ヘッダーを入力することもできます。
$metadata 構文は、メッセージ ヘッダーの一部である MQTT プロパティにのみ必要です。 詳細については、「フィールド参照」を参照してください。
適用を選択します。
新しいプロパティ
[新しいプロパティ] 変換を使用して、ソース データに新しいプロパティを追加できます。 この操作は、ソース データに新しいプロパティを追加するために使用されます。 新しいプロパティは、データ フローの後続のステージで使用できます。
[変換 (省略可能)] で、[新しいプロパティ]>[追加] を選びます。

必要な設定を入力します。
| 設定 |
説明 |
| プロパティキー |
新しいプロパティのキーを入力します。 |
| プロパティ値 |
新しいプロパティの値を入力します。 |
| 説明 |
新しいプロパティの説明を入力します。 |
適用を選択します。
たとえば、ソース データの temperature フィールドを使用して温度を摂氏に変換し、それを temperatureCelsius フィールドに格納できます。 コンテキスト化データセットの ___location フィールドを使用してソース データをエンリッチすることもできます。
{
"operationType": "BuiltInTransformation",
"builtInTransformationSettings": {
"map": [
{
"inputs": [
"$source.temperature ? $last" // ---------------- $1
],
"output": "temperatureCelsius",
"expression": "($1 - 32) * 5/9"
},
{
"inputs": [
"$context(assetDataset).___location" // - $2
],
"output": "___location"
}
]
}
}
MQTT メタデータ プロパティには、形式 $metadata.user_properties.<property> または $metadata.topic を使用してアクセスできます。
$metadata.<header> 形式を使用して、$metadata ヘッダーを入力することもできます。 詳細については、「フィールド参照」を参照してください。
たとえば、ソース データの temperature フィールドを使用して温度を摂氏に変換し、それを temperatureCelsius フィールドに格納できます。 コンテキスト化データセットの ___location フィールドを使用してソース データをエンリッチすることもできます。
builtInTransformationSettings: {
map: [
{
inputs: [
'temperature'
]
output: 'temperatureCelsius'
expression: '($1 - 32) * 5/9'
}
{
inputs: [
'$context(assetDataset).___location'
]
output: '___location'
}
]
}
MQTT メタデータ プロパティには、形式 $metadata.user_properties.<property> または $metadata.topic を使用してアクセスできます。
$metadata.<header> 形式を使用して、$metadata ヘッダーを入力することもできます。 詳細については、「フィールド参照」を参照してください。
たとえば、ソース データの temperature フィールドを使用して温度を摂氏に変換し、それを temperatureCelsius フィールドに格納できます。 コンテキスト化データセットの ___location フィールドを使用してソース データをエンリッチすることもできます。
builtInTransformationSettings:
map:
- inputs:
- temperature # - $1
expression: "($1 - 32) * 5/9"
output: temperatureCelsius
- inputs:
- $context(assetDataset).___location
output: ___location
詳細については、「データ フローを使用してデータをマッピングする」と「データ フローを使用したデータの変換」に関する記事を参照してください。
[削除]
既定では、すべてのデータポイントが出力スキーマに含まれます。 Remove 変換を使用して、変換先から任意のデータ ポイントを 削除 できます。
変換 (省略可能) で、削除 を選択します。
出力スキーマから削除するデータ ポイントを選択します。

適用を選択します。
出力スキーマからデータ ポイントを削除するには、データ フロー構成で builtInTransformationSettings プロパティを使用します。
map プロパティは、削除するデータポイントを指定するために使用されます。
{
"operationType": "BuiltInTransformation",
"builtInTransformationSettings": {
"map": [
{
"inputs": [
"*"
],
"output": "*"
},
{
"inputs": [
"weight"
],
"output": ""
}
{
"inputs": [
"weight.SourceTimestamp"
],
"output": ""
},
{
"inputs": [
"weight.Value"
],
"output": ""
},
{
"inputs": [
"weight.StatusCode"
],
"output": ""
},
{
"inputs": [
"weight.StatusCode.Code"
],
"output": ""
},
{
"inputs": [
"weight.StatusCode.Symbol"
],
"output": ""
}
]
}
}
builtInTransformationSettings: {
map: [
{
inputs: [
'*'
]
output: '*'
}
{
inputs: [
'weight'
]
output: ''
}
{
inputs: [
'weight.SourceTimestamp'
]
output: ''
}
{
inputs: [
'weight.Value'
]
output: ''
}
{
inputs: [
'weight.StatusCode'
]
output: ''
}
{
inputs: [
'weight.StatusCode.Code'
]
output: ''
}
{
inputs: [
'weight.StatusCode.Symbol'
]
output: ''
}
]
}
builtInTransformationSettings:
map:
- type: PassThrough
inputs:
- "*"
output: "*"
- inputs:
- weight
output: ""
- inputs:
- weight.SourceTimestamp
output: ""
- inputs:
- weight.Value
output: ""
- inputs:
- weight.StatusCode
output: ""
- inputs:
- weight.StatusCode.Code
output: ""
- inputs:
- weight.StatusCode.Symbol
output: ""
詳細については、「データ フローを使用してデータをマッピングする」と「データ フローを使用したデータの変換」に関する記事を参照してください。
スキーマに従ってデータをシリアル化する
データを宛先に送信する前にシリアル化する場合は、スキーマとシリアル化形式を指定する必要があります。 それ以外の場合は、データは推論された型を使用して JSON でシリアル化されます。 Microsoft Fabric や Azure Data Lake などのストレージ エンドポイントには、データの一貫性を確保するためにスキーマが必要です。 サポートされているシリアル化形式は、Parquet と Delta です。
操作エクスペリエンスの場合は、データ フロー エンドポイントの詳細でスキーマとシリアル化の形式を指定します。 シリアル化形式をサポートするエンドポイントは、Microsoft Fabric OneLake、Azure Data Lake Storage Gen 2、Azure Data Explorer、およびローカル ストレージです。 たとえば、差分形式でデータをシリアル化するには、スキーマをスキーマ レジストリにアップロードし、データ フロー変換先エンドポイント構成で参照する必要があります。

スキーマ レジストリにスキーマをアップロードしたら、データ フロー構成でスキーマを参照できます。
{
"builtInTransformationSettings": {
"serializationFormat": "Delta",
"schemaRef": "aio-sr://<SCHEMA_NAMESPACE>/<SCHEMA>:<VERSION>"
}
}
スキーマ レジストリにスキーマをアップロードしたら、データ フロー構成でスキーマを参照できます。
builtInTransformationSettings: {
serializationFormat: 'Delta'
schemaRef: 'aio-sr://<SCHEMA_NAMESPACE>/<SCHEMA>:<VERSION>'
}
スキーマ レジストリにスキーマをアップロードしたら、データ フロー構成でスキーマを参照できます。
builtInTransformationSettings:
serializationFormat: Delta
schemaRef: 'aio-sr://<SCHEMA_NAMESPACE>/<SCHEMA>:<VERSION>'
スキーマ レジストリの詳細については、「メッセージ スキーマについて」を参照してください。
宛先
データ フローの宛先を構成するには、エンドポイント参照とデータ宛先を指定します。 エンドポイントのデータの宛先の一覧を指定できます。
ローカル MQTT ブローカー以外の宛先にデータを送信するには、データ フロー エンドポイントを作成します。 その方法については、データ フロー エンドポイントの構成に関するページを参照してください。 宛先がローカル MQTT ブローカーでない場合は、ソースとして使用する必要があります。 ローカル MQTT ブローカー エンドポイントの使用の詳細については、 データ フローでローカル MQTT ブローカー エンドポイントを使用する必要がある方法に関するページを参照してください。
重要
ストレージ エンドポイントには、シリアル化にスキーマが必要です。 Microsoft Fabric OneLake、Azure Data Lake Storage、Azure Data Explorer、またはローカル記憶域でデータ フローを使用するには、スキーマ参照を指定する必要があります。
宛先として使用するデータ フロー エンドポイントを選択します。

ストレージ エンドポイントには、シリアル化にスキーマが必要です。 Microsoft Fabric OneLake、Azure Data Lake Storage、Azure Data Explorer、またはローカル ストレージの宛先エンドポイントを選択する場合は、スキーマ参照を指定する必要があります。 たとえば、データを Delta 形式で Microsoft Fabric エンドポイントにシリアル化するには、スキーマをスキーマ レジストリにアップロードし、データ フローの宛先エンドポイントの構成内でそれを参照する必要があります。

[続行] を選択して、宛先を構成します。
データの送信先となるトピックやテーブルなど、宛先に必要な設定を入力します。 詳細については、「データの宛先の構成 (トピック、コンテナー、またはテーブル)」を参照してください。
{
"destinationSettings": {
"endpointRef": "<CUSTOM_ENDPOINT_NAME>",
"dataDestination": "<TOPIC_OR_TABLE>" // See section on configuring data destination
}
}
destinationSettings: {
endpointRef: '<CUSTOM_ENDPOINT_NAME>'
dataDestination: '<TOPIC_OR_TABLE>' // See section on configuring data destination
}
destinationSettings:
endpointRef: <CUSTOM_ENDPOINT_NAME>
dataDestination: <TOPIC_OR_TABLE> # See section on configuring data destination
データ ソースと同様に、データの宛先は、複数のデータ フロー間でデータ フロー エンドポイントを再利用可能に保つために使用される概念です。 基本的には、データ フロー エンドポイント構成のサブディレクトリを表します。 たとえば、データ フロー エンドポイントがストレージ エンドポイントの場合、データの宛先はストレージ アカウント内のテーブルです。 データ フロー エンドポイントが Kafka エンドポイントの場合、データの宛先は Kafka トピックです。
| エンドポイントの種類 |
データの宛先の意味 |
説明 |
| MQTT (または Event Grid) |
トピック |
データが送信される MQTT トピック。 静的トピックのみがサポートされ、ワイルドカードはサポートされません。 |
| Kafka (または Event Hubs) |
トピック |
データが送信される Kafka トピック。 静的トピックのみがサポートされ、ワイルドカードはサポートされません。 エンドポイントが Event Hubs 名前空間の場合、データの宛先は名前空間内の個々のイベント ハブです。 |
| Azure Data Lake Storage |
コンテナー |
ストレージ アカウントのコンテナー。 テーブルではありません。 |
| Microsoft Fabric OneLake |
ファイルまたはフォルダー |
構成済みのエンドポイントのパスの種類に対応します。 |
| アジュール データ エクスプローラー (Azure Data Explorer) |
テーブル |
Azure Data Explorer データベース内のテーブル。 |
| ローカル ストレージ |
フォルダー |
ローカル ストレージの永続ボリューム マウント内のフォルダーまたはディレクトリ名。
Azure Arc クラウド取り込みエッジ ボリュームで有効な Azure コンテナー ストレージを使用する場合、これは、作成したサブボリュームの spec.path パラメーターと一致する必要があります。 |
データの宛先を構成するには:
操作エクスペリエンスを使用する場合、データの宛先フィールドはエンドポイントの種類に基づいて自動的に解釈されます。 たとえば、データ フロー エンドポイントがストレージ エンドポイントの場合、宛先の詳細ページでコンテナー名の入力が求められます。 データ フロー エンドポイントが MQTT エンドポイントである場合、宛先の詳細ページでトピックの入力などが求められます。

{
"destinationSettings": {
"endpointRef": "<CUSTOM_ENDPOINT_NAME>",
"dataDestination": "<TOPIC_OR_TABLE>" // See section on configuring data destination
}
}
たとえば、静的 MQTT トピックのローカル MQTT ブローカーにデータを送り返すには、次の構成を使用します。
{
"destinationSettings": {
"endpointRef": "default",
"dataDestination": "example-topic"
}
}
または、カスタム イベント ハブ エンドポイントがある場合、構成は次のようになります。
{
"destinationSettings": {
"endpointRef": "my-eh-endpoint",
"dataDestination": "individual-event-hub"
}
}
構文は、すべてのデータ フロー エンドポイントで同じです:
destinationSettings: {
endpointRef: "<CUSTOM_ENDPOINT_NAME>"
dataDestination: '<TOPIC_OR_TABLE>'
}
たとえば、静的 MQTT トピックのローカル MQTT ブローカーにデータを送り返すには、次の構成を使用します。
destinationSettings: {
endpointRef: 'default'
dataDestination: 'example-topic'
}
または、カスタム イベント ハブ エンドポイントがある場合、構成は次のようになります。
destinationSettings: {
endpointRef: 'my-eh-endpoint'
dataDestination: 'individual-event-hub'
}
ストレージ エンドポイントを宛先として使用する別の例:
destinationSettings: {
endpointRef: 'my-adls-endpoint'
dataDestination: 'my-container'
}
構文は、すべてのデータ フロー エンドポイントで同じです:
destinationSettings:
endpointRef: <CUSTOM_ENDPOINT_NAME>
dataDestination: <TOPIC_OR_TABLE>
たとえば、静的 MQTT トピックのローカル MQTT ブローカーにデータを送り返すには、次の構成を使用します。
destinationSettings:
endpointRef: default
dataDestination: example-topic
または、カスタム イベント ハブ エンドポイントがある場合、構成は次のようになります。
destinationSettings:
endpointRef: my-eh-endpoint
dataDestination: individual-event-hub
ストレージ エンドポイントを宛先として使用する別の例:
destinationSettings:
endpointRef: my-adls-endpoint
dataDestination: my-container
例
次の例は、ソースと宛先に MQTT エンドポイントを使用したデータ フロー構成です。 ソースは、MQTT トピック azure-iot-operations/data/thermostat からのデータをフィルターします。 変換によって温度が華氏に変換され、温度に湿度を掛けた値が 100,000 未満のデータにフィルターされます。 宛先が MQTT トピック factory にデータを送信します。

az iot ops dataflow apply コマンドを使用して、データ フローを作成または変更します。
az iot ops dataflow apply --resource-group <ResourceGroupName> --instance <AioInstanceName> --profile <DataflowProfileName> --name <DataflowName> --config-file <ConfigFilePathAndName>
--config-file パラメーターは、リソース プロパティを含む JSON 構成ファイルのパスとファイル名です。
この例では、ユーザーのホーム ディレクトリに格納されている次のコンテンツを含む data-flow.json という名前の構成ファイルを想定しています。
{
"mode": "Enabled",
"operations": [
{
"operationType": "Source",
"sourceSettings": {
"dataSources": [
"thermostats/+/sensor/temperature/#",
"humidifiers/+/sensor/humidity/#"
],
"endpointRef": "default",
"serializationFormat": "Json"
}
},
{
"builtInTransformationSettings": {
"datasets": [],
"filter": [
{
"expression": "$1 * $2 < 100000",
"inputs": [
"temperature.Value",
"\"Tag 10\".Value"
],
"type": "Filter"
}
],
"map": [
{
"inputs": [
"*"
],
"output": "*",
"type": "PassThrough"
},
{
"expression": "fToC($1)",
"inputs": [
"Temperature.Value"
],
"output": "TemperatureF",
"type": "Compute"
},
{
"inputs": [
"@\"Tag 10\".Value"
],
"output": "Humidity",
"type": "Rename"
}
],
"serializationFormat": "Json"
},
"operationType": "BuiltInTransformation"
},
{
"destinationSettings": {
"dataDestination": "factory",
"endpointRef": "default"
},
"operationType": "Destination"
}
]
}
既定のデータフロー プロファイルを使用してデータ フローを作成または更新するコマンドの例を次に示します。
az iot ops dataflow apply --resource-group myResourceGroup --instance myAioInstance --profile default --name data-flow --config-file ~/data-flow.json
param aioInstanceName string = '<AIO_INSTANCE_NAME>'
param customLocationName string = '<CUSTOM_LOCATION_NAME>'
param dataflowName string = '<DATAFLOW_NAME>'
resource aioInstance 'Microsoft.IoTOperations/instances@2024-11-01' existing = {
name: aioInstanceName
}
resource customLocation 'Microsoft.ExtendedLocation/customLocations@2021-08-31-preview' existing = {
name: customLocationName
}
// Pointer to the default data flow endpoint
resource defaultDataflowEndpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
// Pointer to the default data flow profile
resource defaultDataflowProfile 'Microsoft.IoTOperations/instances/dataflowProfiles@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
resource dataflow 'Microsoft.IoTOperations/instances/dataflowProfiles/dataflows@2024-11-01' = {
// Reference to the parent data flow profile, the default profile in this case
// Same usage as profileRef in Kubernetes YAML
parent: defaultDataflowProfile
name: dataflowName
extendedLocation: {
name: customLocation.id
type: 'CustomLocation'
}
properties: {
mode: 'Enabled'
operations: [
{
operationType: 'Source'
sourceSettings: {
// Use the default MQTT endpoint as the source
endpointRef: defaultDataflowEndpoint.name
// Filter the data from the MQTT topic azure-iot-operations/data/thermostat
dataSources: [
'azure-iot-operations/data/thermostat'
]
}
}
// Transformation optional
{
operationType: 'BuiltInTransformation'
builtInTransformationSettings: {
// Filter the data where temperature * "Tag 10" < 100000
filter: [
{
inputs: [
'temperature.Value'
'"Tag 10".Value'
]
expression: '$1 * $2 < 100000'
}
]
map: [
// Passthrough all values by default
{
inputs: [
'*'
]
output: '*'
}
// Convert temperature to Fahrenheit and output it to TemperatureF
{
inputs: [
'temperature.Value'
]
output: 'TemperatureF'
expression: 'cToF($1)'
}
// Extract the "Tag 10" value and output it to Humidity
{
inputs: [
'"Tag 10".Value'
]
output: 'Humidity'
}
]
}
}
{
operationType: 'Destination'
destinationSettings: {
// Use the default MQTT endpoint as the destination
endpointRef: defaultDataflowEndpoint.name
// Send the data to the MQTT topic factory
dataDestination: 'factory'
}
}
]
}
}
apiVersion: connectivity.iotoperations.azure.com/v1
kind: Dataflow
metadata:
name: my-dataflow
namespace: azure-iot-operations
spec:
# Reference to the default data flow profile
profileRef: default
mode: Enabled
operations:
- operationType: Source
sourceSettings:
# Use the default MQTT endpoint as the source
endpointRef: default
# Filter the data from the MQTT topic azure-iot-operations/data/thermostat
dataSources:
- azure-iot-operations/data/thermostat
# Transformation optional
- operationType: builtInTransformation
builtInTransformationSettings:
# Filter the data where temperature * "Tag 10" < 100000
filter:
- inputs:
- 'temperature.Value'
- '"Tag 10".Value'
expression: '$1 * $2 < 100000'
map:
# Passthrough all values by default
- inputs:
- '*'
output: '*'
# Convert temperature to Fahrenheit and output it to TemperatureF
- inputs:
- temperature.Value
output: TemperatureF
expression: cToF($1)
# Extract the "Tag 10" value and output it to Humidity
- inputs:
- '"Tag 10".Value'
output: 'Humidity'
- operationType: Destination
destinationSettings:
# Use the default MQTT endpoint as the destination
endpointRef: default
# Send the data to the MQTT topic factory
dataDestination: factory
データ フロー構成のその他の例については、Azure REST API (データ フロー) と Bicep のクイックスタートに関するページを参照してください。
データ フローが機能していることを確認する
「チュートリアル: Azure Event Grid への双方向 MQTT ブリッジ」に従って、データ フローが機能していることを確認します。
データ フロー構成のエクスポート
データ フロー構成をエクスポートするには、操作エクスペリエンスを使用するか、データ フローのカスタム リソースをエクスポートします。
エクスポートするデータ フローを選択し、ツール バーから [エクスポート] を選びます。

az iot ops dataflow show コマンドを使用して、データ フローをエクスポートします。
az iot ops dataflow show --resource-group <ResourceGroupName> --instance <AioInstanceName> --name <DataflowName> --profile <DataflowProfileName> --output json > my-dataflow.json
data-flowという名前のデータ フローを data-flow.json という名前の JSON ファイルにエクスポートするコマンドの例を次に示します。
az iot ops dataflow show --resource-group myResourceGroup --instance myAioInstance --profile default --name data-flow --output json > data-flow.json
kubectl get dataflow my-dataflow -o yaml > my-dataflow.yaml
適切なデータ フロー構成
データ フローが期待どおりに動作していることを確認するには、次のことを確かめします:
次のステップ
