ノートブックをクラスターにアタッチして 1 つ以上のセルを実行すると、そのノートブックが状態を持つようになり、出力が表示されます。 このセクションでは、ノートブックの状態と出力を管理する方法について説明します。
ノートブックの状態と出力を消去する
ノートブックの状態と出力をクリアするには、[実行] メニューの下部にある Clear オプションのいずれかを選択します。
| メニュー オプション | 説明 |
|---|---|
| すべてのセル出力をクリアする | セルの出力をクリアします。 これは、ノートブックを共有し、結果は含まれないようにする場合に便利です。 |
| 状態をクリアする | 関数と変数の定義、データ、インポートされたライブラリなど、ノートブックの状態をクリアします。 |
| 状態と結果をクリアする | セル出力とノートブックの状態をクリアします。 |
| 状態をクリアしてすべて実行する | ノートブックの状態をクリアし、新しい実行を開始します。 |
結果テーブル
セルを実行すると、結果テーブルに結果が表示されます。 結果テーブルでは、次の操作を行うことができます。
- 表形式の結果データの列またはその他のサブセットをクリップボードにコピーします。
- 結果テーブルでテキスト検索を実行します。
- データの並べ替えとフィルター処理を行います。
- キーボードの方向キーを使用して、表のセル間を移動します。
- 列名またはセルの値の一部を選択するには、ダブルクリックしてドラッグし、目的のテキストを選択します。
- 列エクスプローラーを使用して、列の検索、表示/非表示、ピン留め、並べ替えを行います。
ノートブック結果テーブル 
結果テーブルの制限を表示するには、ノートブックの結果テーブルの制限を参照してください。
データを選択する
結果テーブルのデータを選択するには、次のいずれかの操作を行います。
- データまたはデータのサブセットをクリップボードにコピーします。
- 列または行ヘッダーをクリックします。
- テーブルの左上のセルをクリックして、テーブル全体を選択します。
- 任意のセル セットにカーソルをドラッグして選択します。
選択したものに関する情報を示すサイド パネルを開くには、右上端で ![]() panel icon[検索] ボックスの横にある、パネル アイコン ( アイコン) をクリックします。
panel icon[検索] ボックスの横にある、パネル アイコン ( アイコン) をクリックします。
![]()
データをクリップボードにコピーする
CSV 形式の結果テーブルをクリップボードにコピーするには、[テーブル タイトル] タブの横にある下向き矢印をクリックし、[ 結果をクリップボードにコピー] をクリックします。

または、テーブルの左上にあるボックスをクリックして完全なテーブルを選択し、右クリックしてドロップダウン メニューから [コピー ] を選択します。
選択したデータをコピーするには、いくつかの方法があります。
- MacOS で
Cmd + Cキーを押すか、Windows でCtrl + Cを押して、結果を CSV 形式でクリップボードにコピーします。 - 右クリックして [ コピー ] を選択し、結果を CSV 形式でクリップボードにコピーします。
- 選択したデータを CSV、TSV、または Markdown 形式でコピーするには、右クリックして [ コピー] を選択します。

結果の並べ替え
列の値で結果テーブルを並べ替えるには、列名の上にカーソルを置きます。 セルの右側に列名を含むアイコンが表示されます。 矢印をクリックして列を並べ替えます。
 を並べ替える方法
を並べ替える方法
複数の列で並べ替えるには、Shift キーを押しながら列の並べ替え矢印をクリックします。
既定では、並べ替えは自然な並べ替え順序に従います。 辞書式の並べ替え順序を適用するには、SQL で ORDER BY を使用するか、環境内で使用可能なそれぞれの SORT 関数を使用します。
結果のフィルター処理
結果テーブルのフィルターを使用して、データを詳しく調べます。 結果テーブルに適用されるフィルターは視覚化にも影響を与え、基になるクエリやデータセットを変更せずに対話型の探索を有効にします。 ビジュアライゼーションのフィルター処理を行う方法をご覧ください。
フィルターを作成するには、いくつかの方法があります。
Databricks Assistant
アシスタントで自然言語プロンプトを使用する
Databricks Assistant を有効にしている場合は、自然言語プロンプトを使用してフィルターを作成できます。
- セルの結果の右上にある [
![フィルター] アイコン](../_static/images/product-icons/filtericon.svg) をクリックします。
をクリックします。 - 表示されるダイアログで、目的のフィルターを説明するテキストを入力します。
- [
![送信] アイコンをクリックします](../_static/images/product-icons/sendicon.svg) 。 アシスタントによってフィルターが生成され、適用されます。
。 アシスタントによってフィルターが生成され、適用されます。
アシスタントを使用して追加のフィルターを作成する場合は、[ ![]() をクリックします。フィルターの横にある別のプロンプトを入力します。
をクリックします。フィルターの横にある別のプロンプトを入力します。
「自然言語プロンプトでデータをフィルター処理する」を参照してください。
[フィルター] ダイアログ
組み込みのフィルター ダイアログを使用する
- Databricks Assistant が有効になっていない場合は、[ をクリックします。セルの結果の右上にあるフィルター ダイアログを開きます。 このダイアログには、[
![フィルターの追加] ボタン](../_static/images/notebooks/add-filter.png) をクリックしてアクセスすることもできます。
をクリックしてアクセスすることもできます。 - フィルター処理する列を選択します。
- 適用するフィルター規則を選択します。
- フィルター処理する値を選択します。

値別
特定の値でフィルター処理する
- 結果テーブルから、その値を持つセルを右クリックします。
- ドロップダウン メニューから [ この値でフィルター] を選択します。

列ごとに
特定の列にフィルターを適用する
- フィルターを適用する列にカーソルを合わせます。
- [
![Kebab] メニュー アイコン](../_static/images/product-icons/overflowicon.svg) をクリックします。
をクリックします。 - フィルター をクリックします。
- フィルター処理する値を選択します。

フィルターを一時的に有効または無効にするには、ダイアログの [有効/無効] ボタンを切り替えます。
フィルターを削除するには、[ ![]() をクリックします。フィルター名削除
をクリックします。フィルター名削除  の横にあります。
の横にあります。
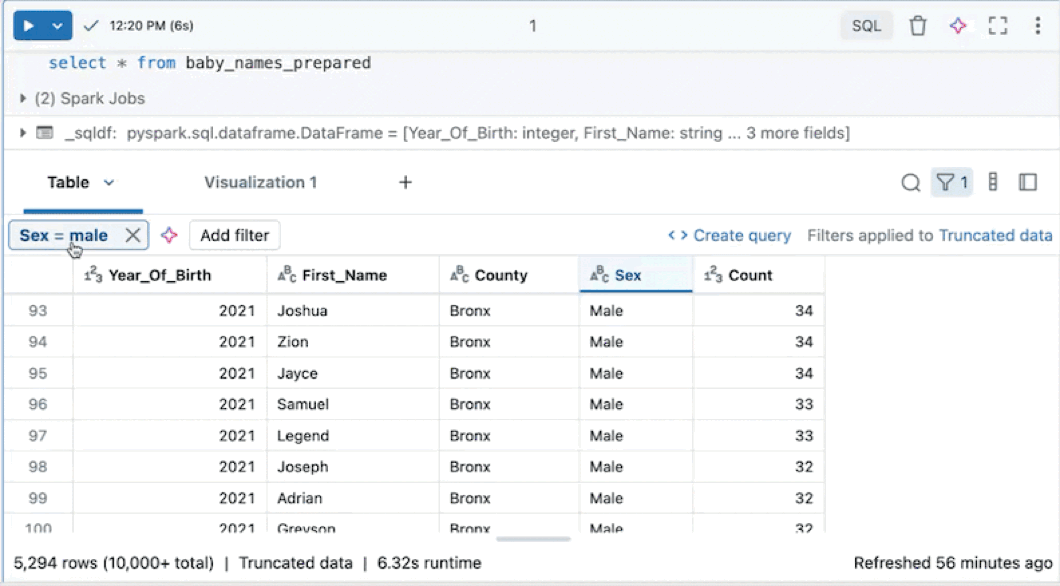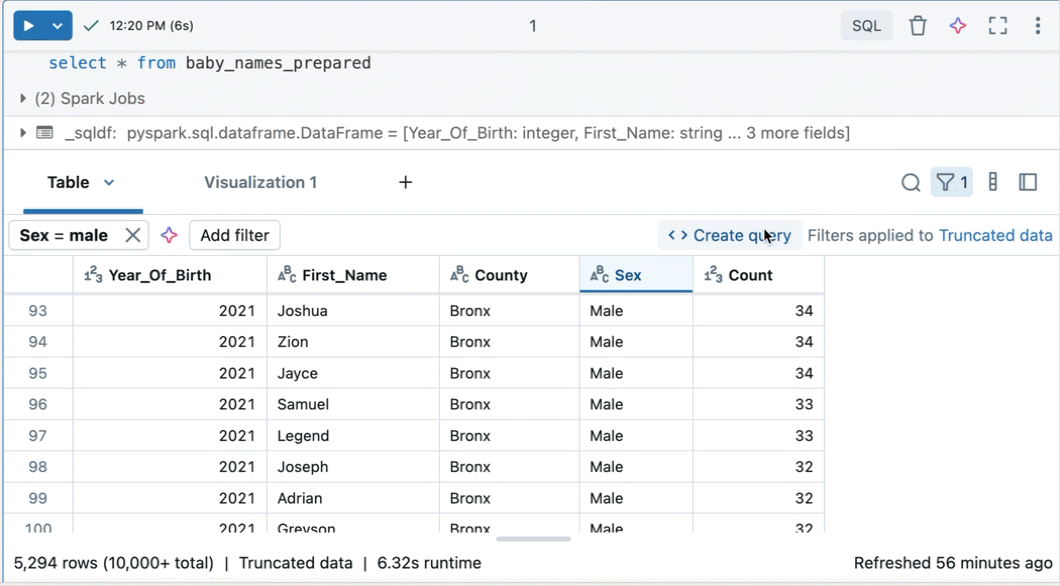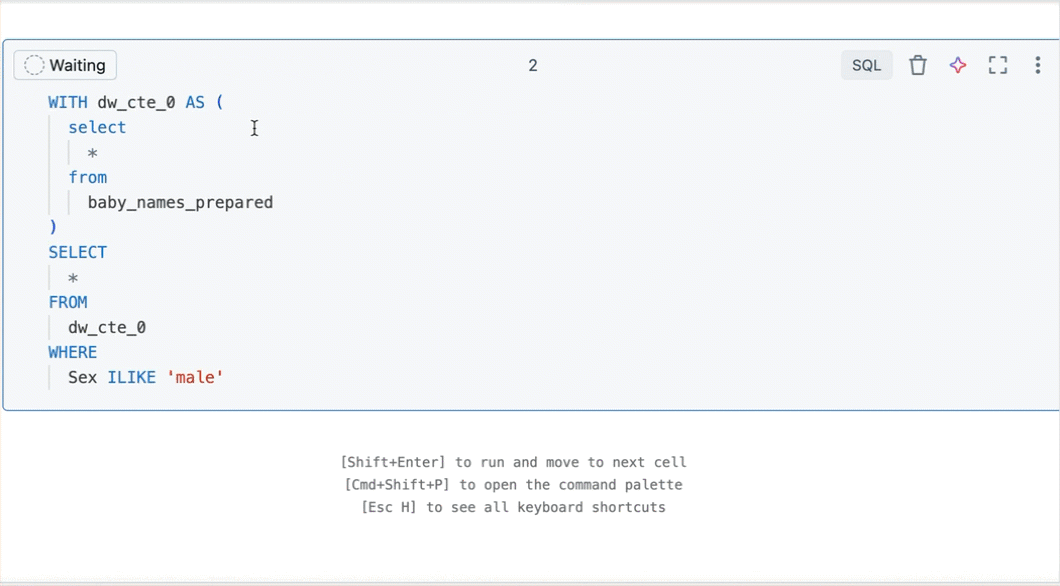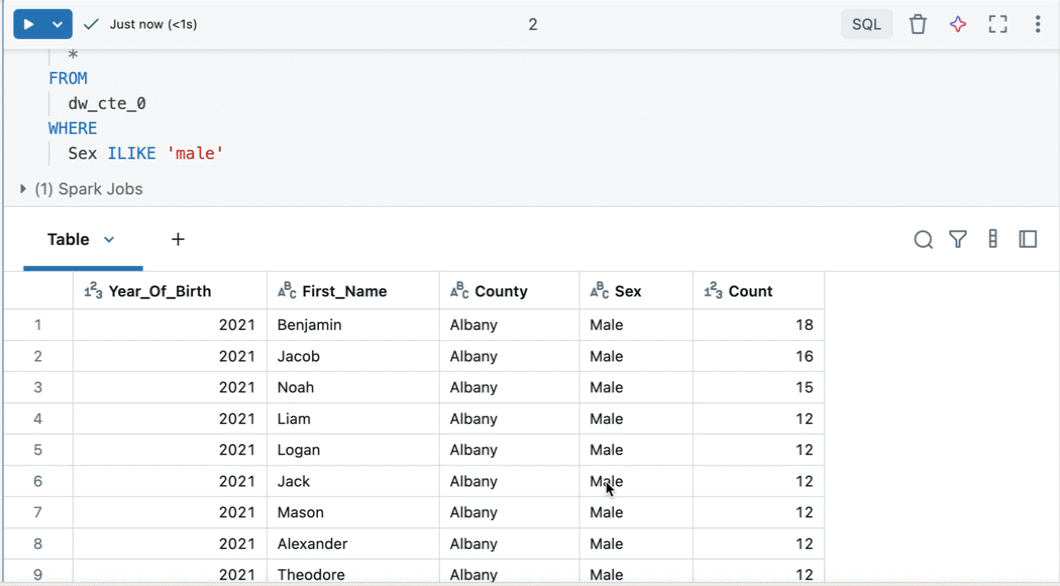
完全なデータセットにフィルターを適用する
既定では、フィルターは結果テーブルに表示される結果にのみ適用されます。 返されたデータが切り捨てられる場合 (たとえば、クエリから 10,000 行を超える行が返された場合、またはデータセットが 2 MB を超える場合)、フィルターは返された行にのみ適用されます。 テーブルの右上にあるメモは、フィルターが切り捨てられたデータに適用されたことを示しています。
代わりに、完全なデータセットをフィルター処理することもできます。 [Truncated data] (切り捨てられたデータ) をクリックし、[Full dataset] (データセット全体) を選びます。 データセットのサイズによっては、フィルターが適用されるまでに時間がかかる場合があります。

フィルター処理された結果からクエリを作成する
既定の言語として SQL を使用するノートブックのフィルター処理された結果テーブルまたは視覚化から、フィルターが適用された新しいクエリを作成できます。 テーブルまたは視覚化の右上にある [ クエリの作成] をクリックします。 クエリがノートブックの次のセルとして追加されます。
作成されたクエリは、元のクエリの上にフィルターを適用します。 これにより、より小さく関連性の高いデータセットを操作できるため、より効率的なデータ探索と分析が可能になります。
列を探索する
列が多いテーブルの操作を容易にするために、列エクスプローラーを使用できます。 列エクスプローラーを開くには、結果テーブルの右上にある列アイコン (![]() をクリックします。
をクリックします。
列エクスプローラーを使用すると、次のことができます。
- 列を検索する: 検索バーに入力して列の一覧をフィルター処理します。 エクスプローラーで列をクリックして、結果テーブル内の列に移動します。
- 列の表示/非表示: チェック ボックスを使用して列の表示を制御します。 上部のチェック ボックスをオンにすると、すべての列の可視性が一度に切り替わります。 個々の列は、名前の横にあるチェック ボックスを使用して表示または非表示にすることができます。
- 列をピン留めする: 列名にカーソルを合わせると、ピン アイコンが表示されます。 ピン アイコンをクリックして列をピン留めします。 結果テーブルを水平方向にスクロールしても、ピン留めされた列は表示されたままです。
-
列を並べ替える: ドラッグ アイコン (
 )をクリックしたまま列の名前の右側に移動し、列を新しい目的の位置にドラッグ アンド ドロップします。 これにより、結果テーブルの列の順序が変更されます。
)をクリックしたまま列の名前の右側に移動し、列を新しい目的の位置にドラッグ アンド ドロップします。 これにより、結果テーブルの列の順序が変更されます。

列の書式設定
列ヘッダーは、列のデータ型を示します。 たとえば、整数型の列の  整数データ型を示します。 インジケーターをマウスでポイントすると、データ型が表示されます。
整数データ型を示します。 インジケーターをマウスでポイントすると、データ型が表示されます。
結果テーブルの列は、Currency、Percentage、URL などの型として書式設定でき、より明確なテーブルの小数点以下の桁数を制御できます。
列名のケバブ メニューで、列の書式を設定します。

結果のダウンロード
既定では、結果のダウンロードは有効です。 この設定を切り替えるには、「ノートブックから結果をダウンロードする機能を管理する」を参照してください。
表形式の出力が含まれているセル結果をローカル コンピューターにダウンロードできます。 タブ タイトルの横にある下向き矢印をクリックします。 メニューのオプションは、結果の行数と Databricks Runtime のバージョンによって異なります。 ダウンロードした結果は、ノートブック名に対応する名前を持つ CSV ファイルとしてローカル コンピューターに保存されます。

SQL ウェアハウスまたはサーバーレス コンピューティングに接続されているノートブックの場合は、結果を Excel ファイルとしてダウンロードすることもできます。

SQL セルの結果を調べる
Databricks ノートブックでは、SQL 言語セルからの結果は、変数 _sqldfに割り当てられた DataFrame として自動的に使用できます。
_sqldf変数を使用して、後続の Python および SQL セルの前の SQL 出力を参照できます。 詳細については、「 EXPlore SQL セルの結果を参照してください。
セルごとに複数の出力を表示する
Python ノートブックと、Python 以外のノートブックの %python セルでは、セルごとに複数の出力がサポートされます。 たとえば、次のコードの出力には、プロットとテーブルの両方が含まれます。
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)
出力のサイズを変更する
テーブルまたは視覚化の右下隅をドラッグして、セル出力のサイズを変更します。
Databricks Git フォルダーでノートブックの出力をコミットする
.ipynb ノートブック出力のコミットの詳細については、「.ipynb ノートブック出力のコミットを許可する」を参照してください。
- ノートブックは .ipynb ファイルである必要があります
- ワークスペース管理者の設定では、ノートブックの出力をコミットできるようにする必要があります