このクイックスタートは、開発環境として Databricks Notebook を使用する場合に、GenAI アプリを MLflow Tracing と統合するのに役立ちます。 ローカル IDE を使用する場合は、代わりに IDE クイック スタート を使用してください。
達成する内容
このチュートリアルの最後には、次の内容が含まれます。
- GenAIアプリのためのMLflow実験とリンクされたDatabricksノートブック
- MLflow トレースを使用してインストルメント化されたシンプルな GenAI アプリケーション
- MLflow 実験におけるそのアプリからの痕跡

[前提条件]
- Databricks ワークスペース: Databricks ワークスペースへのアクセス。
手順 1: Databricks Notebook を作成する
注
Databricks Notebook を作成すると、GenAI アプリケーションのコンテナーである MLflow 実験が作成されます。 実験の詳細と、 データ モデル セクションに含まれる内容について説明します。
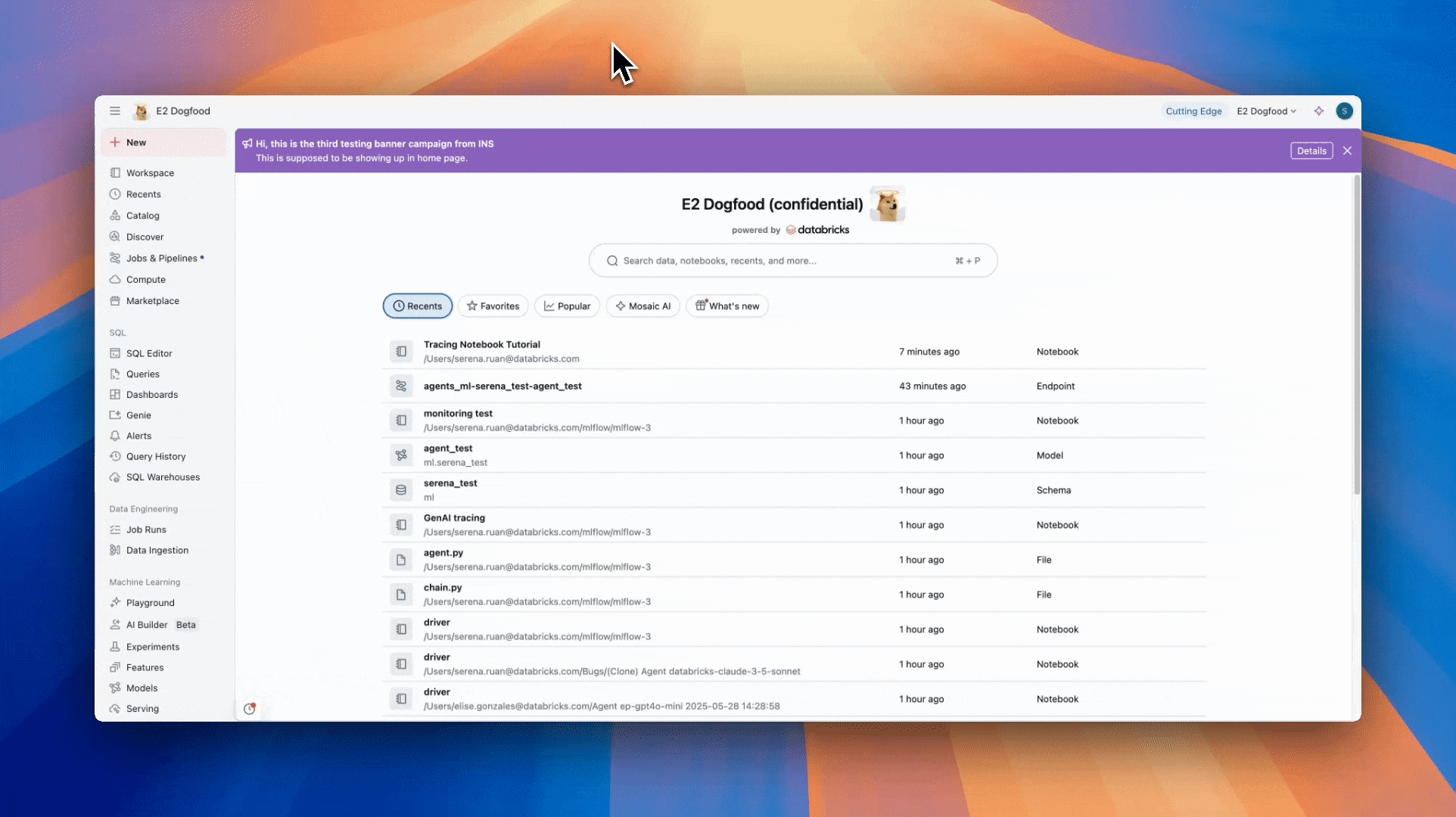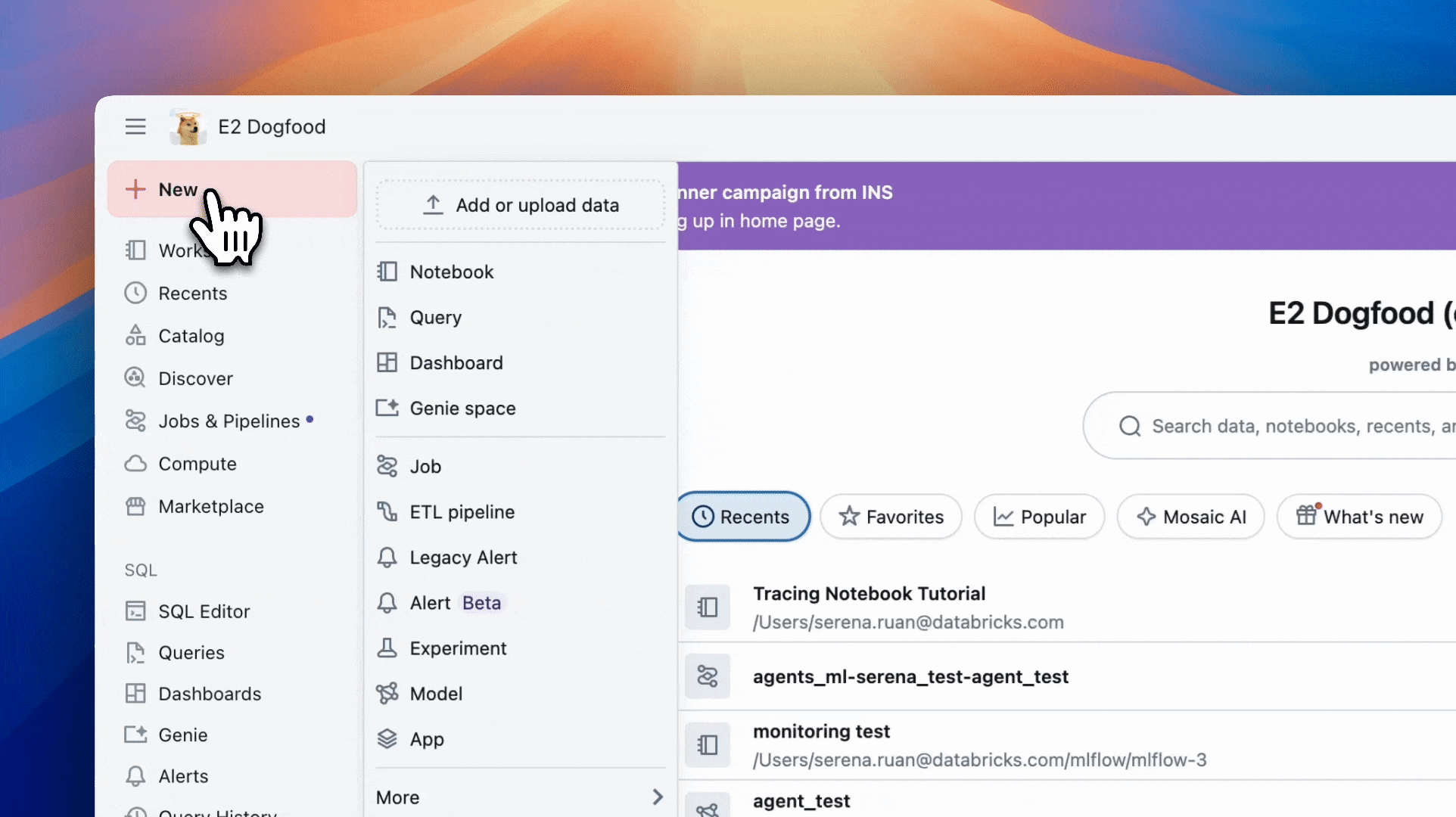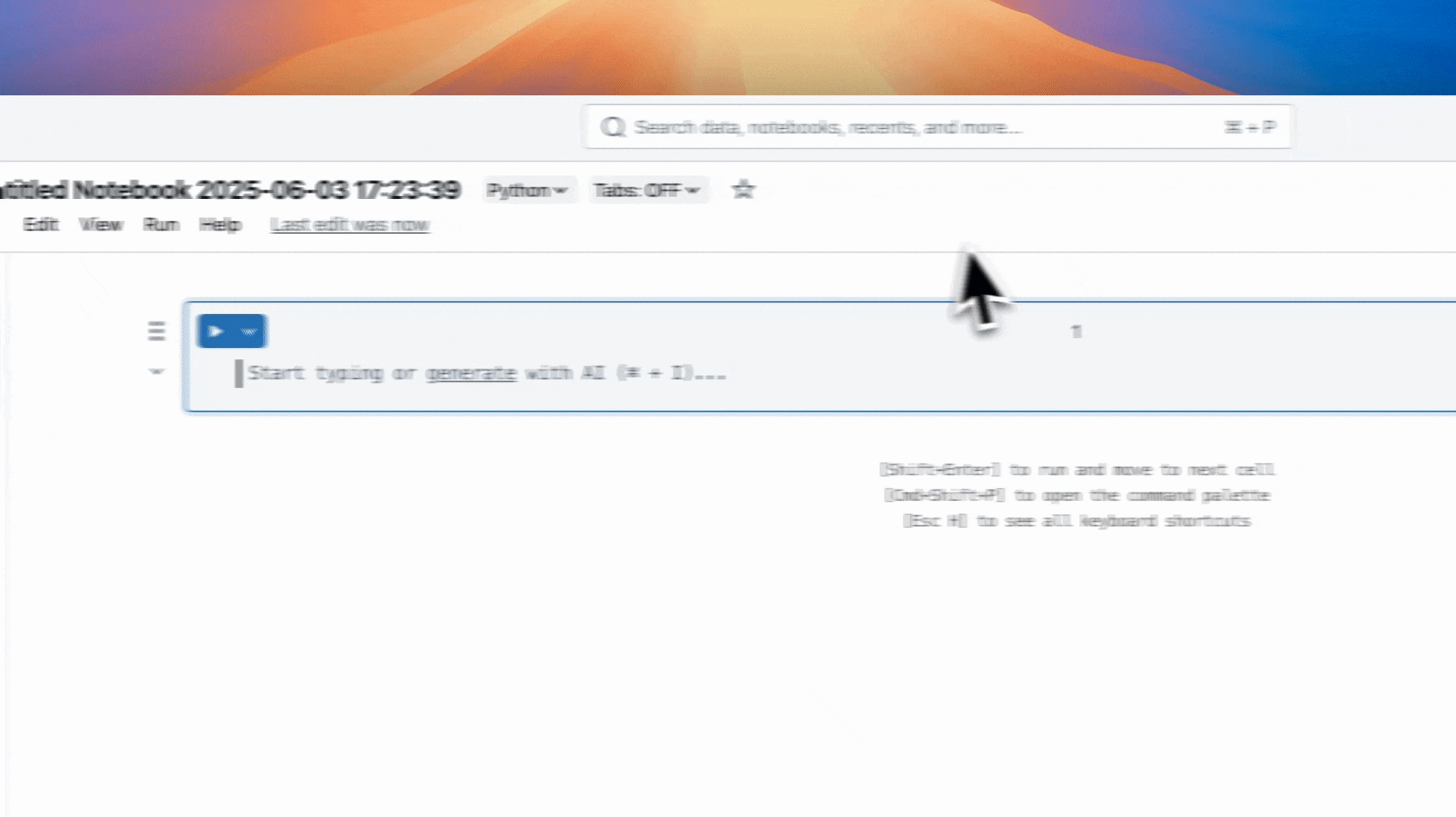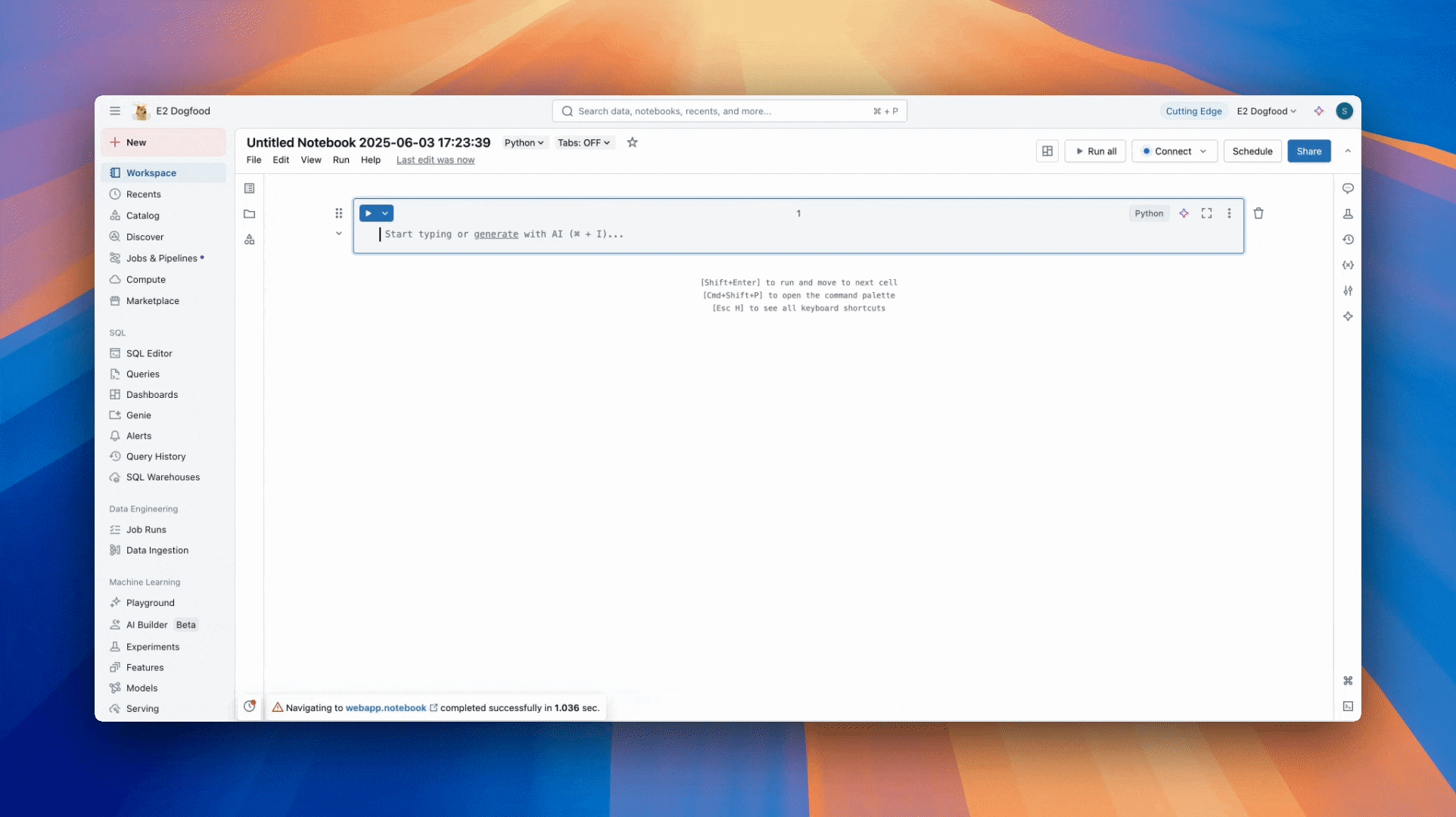
- Databricks ワークスペースを開く
- 左側のサイドバーの上部にある [ 新規 ] に移動
- [ノートブック] をクリックする
手順 2: (推奨) 最新バージョンの MLflow があることを確認する
Databricks ランタイムには MLflow が含まれます。 ただし、最も包括的なトレース機能や堅牢なサポートなど、GenAI 機能で最適なエクスペリエンスを得るために、最新バージョンの MLflow を使用することを強くお勧めします。
次を実行して、ノートブックの MLflow を更新できます。
%pip install --upgrade "mlflow[databricks]>=3.1" openai
dbutils.library.restartPython()
-
mlflow[databricks]>=3.1: このコマンドにより、MLflow 3.1 以降のバージョンと、Databricks 内のシームレスな接続と機能のためのdatabricksが追加されます。 -
dbutils.library.restartPython(): これは、新しくインストールされたバージョンが Python カーネルによって使用されるようにするために重要です。
Warnung
トレース機能は MLflow 2.15.0 以降で使用できます。拡張トレース機能や堅牢なサポートなど、最新の GenAI 機能には MLflow 3 ( mlflow[databricks] を使用する場合は特に 3.1 以降) をインストールすることを強くお勧めします 。
手順 3: アプリケーションをインストルメント化する
ヒント
Databricks は、人気のあるフロンティアとオープン ソースの基本 LLM へのすぐに使用できるアクセスを提供しました。 このクイック スタートを実行するには、次の操作を行います。
- Databricks でホストされる LLM を使用する
- LLM プロバイダーから独自の API キーを直接使用する
- LLM プロバイダーの API キーへの管理アクセスを有効にする 外部モデル を作成する
MLflow でサポートされている他の 20 以上の LLM SDK (Anthropic、Bedrock など) または GenAI オーサリング フレームワーク (LangGraph など) のいずれかを使用する場合は、新しい MLflow 実験を作成するときに表示される手順に従います。
アプリケーションに適した統合を選択します。
次のコードを使用してノートブックにセルを作成する
ここでは、
@mlflow.traceと組み合わせて Python アプリケーションを簡単にトレースできる デコレーターを使用して、OpenAI SDK への呼び出しの詳細をキャプチャします。次のコード スニペットでは、Anthropic の Claude Sonnet LLM を使用しています。 サポートされている基本モデルの一覧から別の LLM を選択できます。
import mlflow from databricks.sdk import WorkspaceClient # Enable MLflow's autologging to instrument your application with Tracing mlflow.openai.autolog() # Create an OpenAI client that is connected to Databricks hosted LLMs mlflow_creds = mlflow.utils.databricks_utils.get_databricks_host_creds() client = OpenAI( api_key=mlflow_creds.token, base_url=f"{mlflow_creds.host}/serving-endpoints" ) # Use the trace decorator to capture the application's entry point @mlflow.trace def my_app(input: str): # This call is automatically instrumented by `mlflow.openai.autolog()` response = client.chat.completions.create( model="databricks-claude-sonnet-4", # This example uses a Databricks hosted LLM - you can replace this with any AI Gateway or Model Serving endpoint. If you have an external model endpoint configured, you can use that model name here. messages=[ { "role": "system", "content": "You are a helpful assistant.", }, { "role": "user", "content": input, }, ], ) return response.choices[0].message.content result = my_app(input="What is MLflow?") print(result)[ノートブック] セルを実行してコードを実行する
手順 4: MLflow でトレースを表示する
- [ノートブック] セルの下にトレースが表示されます
- 必要に応じて、MLflow 実験 UI に移動してトレースを表示できます。
- 画面の右側にある実験アイコンをクリックします
- [実験の実行] の横にある開いているアイコンをクリックします
- 生成されたトレースが [ トレース ] タブに表示されます
- トレースをクリックして詳細を表示します
トレースの理解
作成したトレースには、次の情報が表示されます。
-
ルート スパン:
my_app(...)関数への入力を表します- 子スパン: OpenAI 完了要求を表します
- 属性: モデル名、トークン数、タイミング情報などのメタデータが含まれています
- 入力: モデルに送信されるメッセージ
- 出力: モデルから受信した応答
この単純なトレースは、次のようなアプリケーションの動作に関する貴重な分析情報を既に提供しています。
- 質問された内容
- 生成された応答
- 要求にかかった時間
- 使用されたトークンの数 (コストに影響)
ヒント
RAG システムやマルチステップ エージェントなどのより複雑なアプリケーションの場合、MLflow Tracing は各コンポーネントとステップの内部動作を明らかにすることで、さらに多くの価値を提供します。
次のステップ
これらの推奨されるアクションとチュートリアルを使用して、体験を続けます。
- アプリの品質を評価 する - MLflow の評価機能を使用して GenAI アプリの品質を測定して改善する
- 人間のフィードバックを収集 する - ユーザーとドメインの専門家からフィードバックを収集する方法について説明します
- ユーザーとセッションを追跡 する - トレースにユーザーと会話のコンテキストを追加する
リファレンス ガイド
このガイドで説明されている概念と機能の詳細なドキュメントを確認します。
- トレースの概念 - MLflow トレースの基礎を理解する
- トレース データ モデル - トレース、スパン、および MLflow 構造体による可観測データの構造について説明します
- 手動トレース API - カスタム インストルメンテーションの高度なトレース手法を調べる