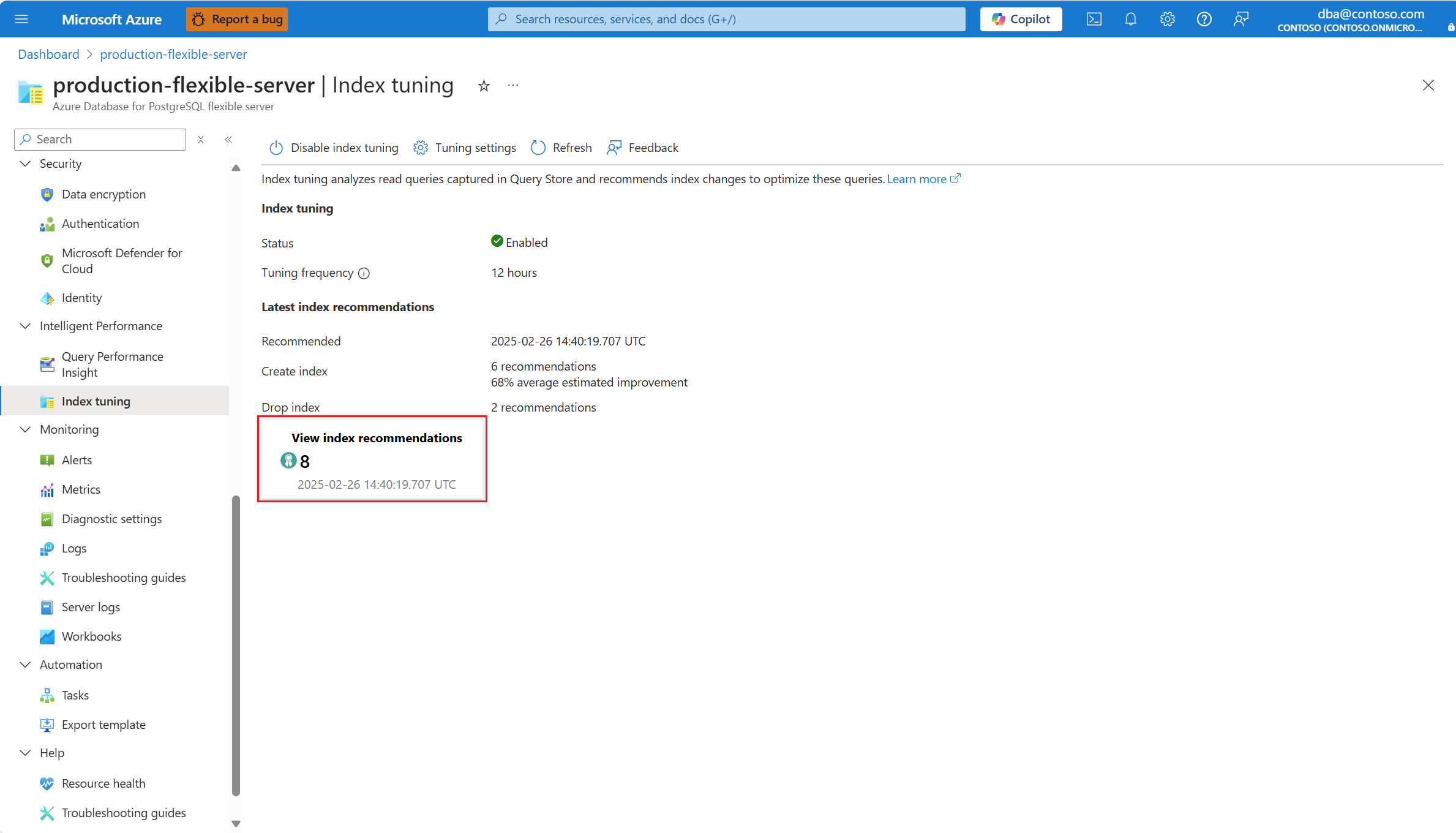
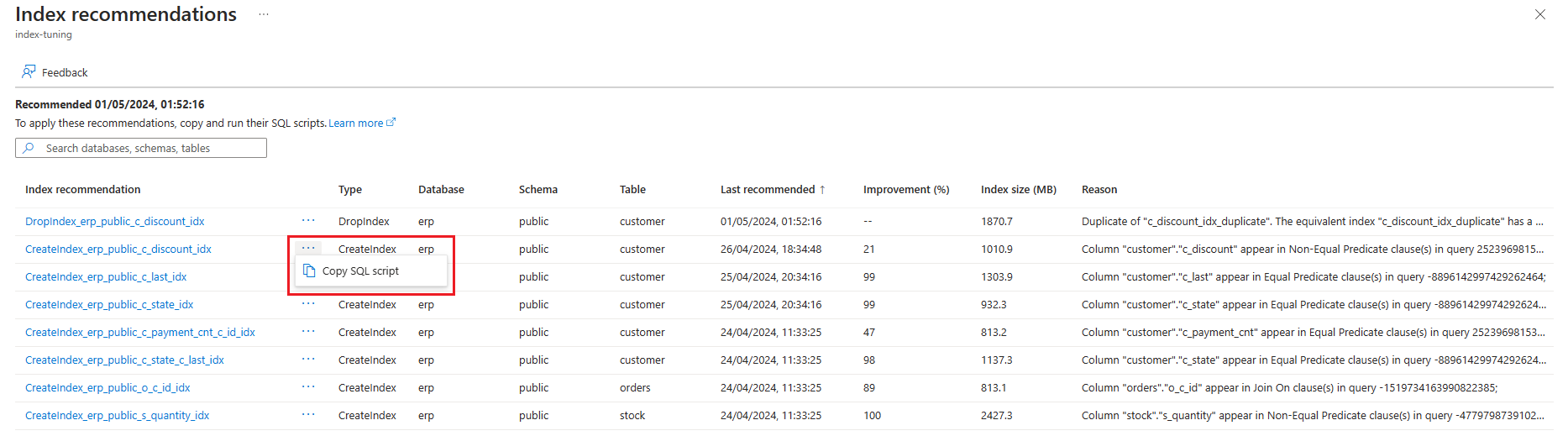
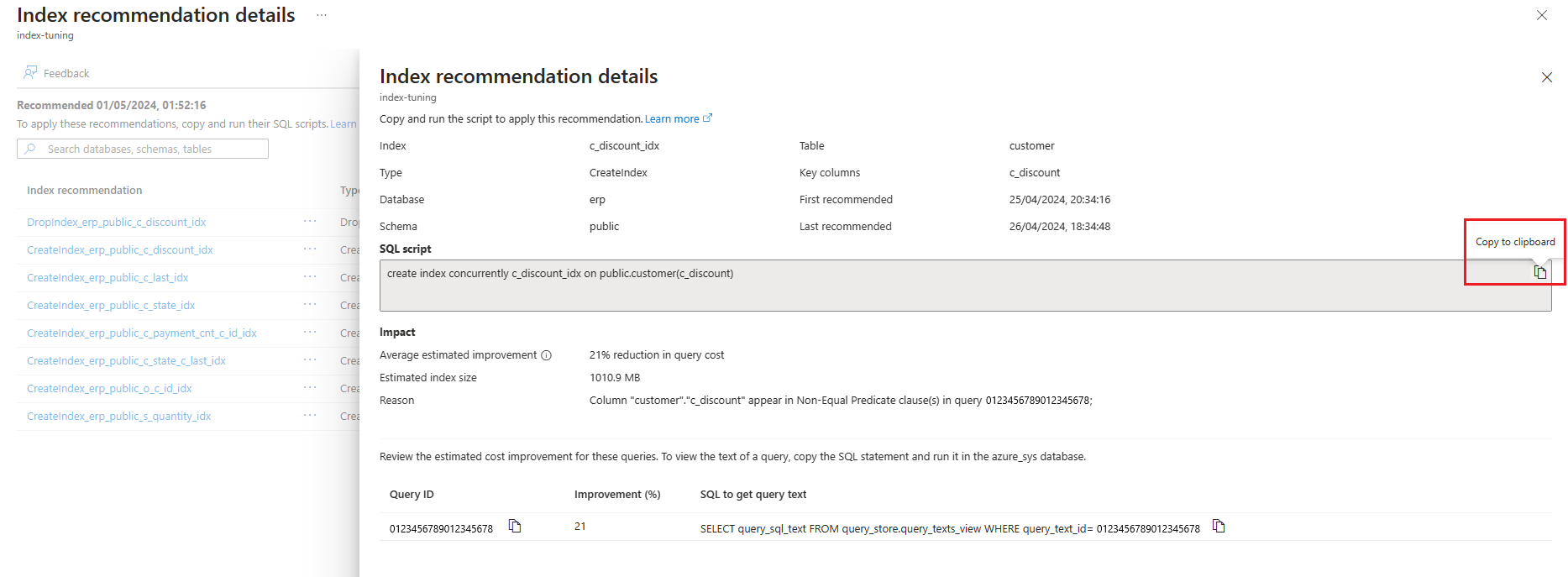
Puede enumerar las recomendaciones de optimización de índices generadas por el ajuste de índices en un servidor existente mediante el comando az postgres flexible-server index-tuning list-recommendations .
Para enumerar todas las recomendaciones de CREATE INDEX, use este comando:
az postgres flexible-server index-tuning list-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type createindex
El comando devuelve toda la información sobre las recomendaciones CREATE INDEX generadas por el ajuste de índices, mostrando algo similar a la salida siguiente:
[
{
"analyzedWorkload": {
"endTime": "2025-02-26T14:40:18.788628+00:00",
"queryCount": 18,
"startTime": "2025-02-26T13:40:18.788628+00:00"
},
"details": {
"databaseName": "<database>",
"includedColumns": "",
"indexColumns": "\"<table>\".\"<column>\"",
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 0.3984375,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
},
{
"absoluteValue": 62.86969111969111,
"dimensionName": "QueryCostImprovement",
"queryId": -555955670159268890,
"unit": "Percentage"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "create index concurrently <index> on <schema>.<table>(<column>)"
},
"improvedQueryIds": [
-555955670159268890
],
"initialRecommendedTime": "2025-02-26T14:40:19.707617+00:00",
"kind": "",
"lastRecommendedTime": "2025-02-26T14:40:19.707617+00:00",
"name": "CreateIndex_<database>_<schema>_<column>_idx",
"recommendationReason": "Column \"<table>\".\"<column>\" appear in Equal Predicate clause(s) in query -555955670159268890;",
"recommendationType": "CreateIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
},
{
.
.
.
}
]
Para enumerar todas las recomendaciones de DROP INDEX, use este comando:
az postgres flexible-server index-tuning list-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type dropindex
El comando devuelve toda la información sobre las recomendaciones drop INDEX generadas por el ajuste de índices, mostrando algo similar a la salida siguiente:
[
{
"analyzedWorkload": {
"endTime": "2025-02-26T19:02:47.522193+00:00",
"queryCount": 0,
"startTime": "2025-01-22T19:02:47.522193+00:00"
},
"details": {
"databaseName": "<database>",
"includedColumns": "",
"indexColumns": "<column>",
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 35.0,
"dimensionName": "Benefit",
"queryId": null,
"unit": "Percentage"
},
{
"absoluteValue": 31.28125,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "drop index concurrently \"<schema>\".\"<index>\";"
},
"improvedQueryIds": null,
"initialRecommendedTime": "2025-02-26T19:02:47.556792+00:00",
"kind": "",
"lastRecommendedTime": "2025-02-26T19:02:47.556792+00:00",
"name": "DropIndex_<database>_<sechema>_<index>",
"recommendationReason": "Duplicate of \"<index>\". The equivalent index \"<index>\" has a shorter length compared to \"<index>\".",
"recommendationType": "DropIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
}
]
Uso de cualquier herramienta de cliente de PostgreSQL de su preferencia:
Conéctese a la base de datos azure_sys disponible en el servidor con cualquier rol que tenga permiso para conectarse a la instancia. Los miembros del rol public pueden leer desde estas vistas.
Ejecute consultas en la vista sessions para recuperar los detalles sobre las sesiones de recomendación.
Ejecute consultas en la vista recommendations para recuperar las recomendaciones generadas por la optimización de índices para CREATE INDEX y DROP INDEX.
Vistas
Las vistas de la base de datos azure_sys proporcionan una manera cómoda de acceder a las recomendaciones de índice generadas por el ajuste del índice y recuperarlas. En concreto, las vistas createindexrecommendations y dropindexrecommendations contienen información detallada sobre las recomendaciones CREATE INDEX y DROP INDEX, respectivamente. Estas vistas exponen datos como el identificador de sesión, el nombre de la base de datos, el tipo de asesor, las horas de inicio y detención de la sesión de optimización, el identificador de recomendación, el tipo de recomendación, el motivo de la recomendación y otros detalles pertinentes. Los usuarios pueden consultar estas vistas para acceder y analizar fácilmente las recomendaciones de índice generadas por el ajuste del índice.
La vista sessions expone todos los detalles de todas las sesiones de optimización de índices.
| nombre de la columna |
tipo de datos |
Descripción |
| identificador_de_sesión |
Identificador Único Universal (UUID) |
Identificador único global asignado a cada nueva sesión de optimización que se inicia. |
| nombre de la base de datos |
varchar(64) |
Nombre de la base de datos en cuyo contexto se ejecutó la sesión de optimización de índices. |
| tipo_de_sesión |
intelligentperformance.recommendation_type |
Indica los tipos de recomendaciones que podría generar esta sesión de optimización de índices. Los valores posibles son: CreateIndex, DropIndex. Las sesiones de tipo CreateIndex pueden generar recomendaciones del tipo CreateIndex. Las sesiones de tipo DropIndex pueden generar recomendaciones de tipos DropIndex o ReIndex. |
| tipo_de_ejecución |
intelligentperformance.recommendation_run_type |
Indica la forma en que se inició esta sesión. Los valores posibles son: Scheduled. A las sesiones ejecutadas automáticamente según el valor de index_tuning.analysis_interval, se les asigna un tipo de ejecución de Scheduled. |
| estado |
intelligentperformance.recommendation_state |
Indica el estado actual de la sesión. Los valores posibles son: Error, Success o InProgress. Las sesiones cuya ejecución no se pudo ejecutar se establecen como Error. Las sesiones que completaron su ejecución correctamente, independientemente de si generaron o no recomendaciones, se establecen como Success. Las sesiones que todavía se ejecutan se establecen como InProgress. |
| hora_de_inicio |
Marca de tiempo sin zona horaria |
Marca de tiempo en la que se inició la sesión de optimización que generó esta recomendación. |
| tiempo_de_parada |
Marca de tiempo sin zona horaria |
Marca de tiempo en la que se inició la sesión de optimización que generó esta recomendación. NULL si la sesión está en curso o se anuló debido a algún error. |
| recuento_de_recomendaciones |
entero |
Número total de recomendaciones generadas en esta sesión. |
La vista recommendations expone todos los detalles de todas las recomendaciones generadas en cualquier sesión de optimización cuyos datos siguen estando disponibles en las tablas subyacentes.
| nombre de la columna |
tipo de datos |
Descripción |
| recommendation_id |
entero |
Número que identifica de forma única una recomendación en todo el servidor. |
| last_known_session_id |
Identificador Único Universal (UUID) |
A cada sesión de optimización de índices se le asigna un identificador único global. El valor de esta columna representa el de la sesión que generó esta recomendación más recientemente. |
| nombre de la base de datos |
varchar(64) |
Nombre de la base de datos en cuyo contexto se generó la recomendación. |
| tipo_de_recomendación |
intelligentperformance.recommendation_type |
Indica el tipo de la recomendación generada. Los valores posibles son: CreateIndex, DropIndex o ReIndex. |
| tiempo_recomendado_inicial |
Marca de tiempo sin zona horaria |
Marca de tiempo en la que se inició la sesión de optimización que generó esta recomendación. |
| último_tiempo_recomendado |
Marca de tiempo sin zona horaria |
Marca de tiempo en la que se inició la sesión de optimización que generó esta recomendación. |
| times_recommended |
entero |
Marca de tiempo en la que se inició la sesión de optimización que generó esta recomendación. |
| razón |
texto |
Motivo que justifica por qué se generó esta recomendación. |
| contexto_de_recomendación |
json |
Contiene la lista de identificadores de consulta para las consultas afectadas por la recomendación, el tipo de índice que se recomienda, el nombre del esquema y el nombre de la tabla en la que se recomienda el índice, las columnas de índice, el nombre del índice y el tamaño estimado en bytes del índice recomendado. |
Motivos para crear recomendaciones de índice
Cuando el ajuste de índices recomienda la creación de un índice, agrega al menos una de las siguientes razones:
| Motivo |
Column <column> appear in Join On clause(s) in query <queryId> |
Column <column> appear in Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Non-Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Group By clause(s) in query <queryId> |
Column <column> appear in Order By clause(s) in query <queryId> |
Motivos para quitar recomendaciones de índice
Cuando el ajuste de índices identifica los índices marcados como no válidos, propone quitarlo con el siguiente motivo:
The index is invalid and the recommended recovery method is to reindex.
Para obtener más información sobre por qué y cuándo los índices están marcados como no válidos, consulte la documentación oficial de REINDEX en PostgreSQL.
Motivos para quitar recomendaciones de índice
Cuando el ajuste de índices detecta un índice que no se usa para, al menos, el número de días establecido en index_tuning.unused_min_period, propone quitarlo con el siguiente motivo:
The index is unused in the past <days_unused> days.
Cuando el ajuste de índices detecta índices duplicados, uno de los duplicados sobrevive y propone quitar el resto. La razón proporcionada siempre tiene el siguiente texto inicial:
Duplicate of <surviving_duplicate>.
Seguido de otro texto que explica el motivo por el que se ha elegido cada uno de los duplicados para la eliminación:
| Motivo |
The equivalent index "<surviving_duplicate>" is a Primary key, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a unique index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a constraint, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a valid index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" has been chosen as replica identity, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" was used to cluster the table, while "<droppable_duplicate>" was not. |
The equivalent index "<surviving_duplicate>" has a smaller estimated size compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more tuples compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more index scans compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been fetched more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been read more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a shorter length compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a smaller oid compared to "<droppable_duplicate>". |
Si el índice no solo es extraíble debido a la duplicación, sino que también no se usa para, al menos, el número de días establecido en index_tuning.unused_min_period, el texto siguiente se anexa al motivo:
Also, the index is unused in the past <days_unused> days.