Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: SDK de Azure Machine Learning v1 para Python
SDK de Azure Machine Learning v1 para Python
Importante
En este artículo se proporciona información sobre el uso del SDK de Azure Machine Learning v1. EL SDK v1 está en desuso a partir del 31 de marzo de 2025. El soporte técnico finalizará el 30 de junio de 2026. Puede instalar y usar SDK v1 hasta esa fecha.
Se recomienda realizar la transición al SDK v2 antes del 30 de junio de 2026. Para más información sobre SDK v2, consulte ¿Qué es la CLI de Azure Machine Learning y el SDK de Python v2? y la referencia del SDK v2.
En este artículo se describe cómo compartir una canalización de aprendizaje automático con sus compañeros o clientes.
Las canalizaciones de aprendizaje automático son flujos de trabajo reutilizables para tareas de aprendizaje automático. Una ventaja de las canalizaciones es aumentar la colaboración. También puede versionar las canalizaciones para permitir que los clientes utilicen el modelo actual mientras usted trabaja en una nueva versión.
Requisitos previos
Cree una Área de trabajo de Azure Machine Learning para contener los recursos de canalización.
Configure el entorno de desarrollo mediante la instalación del SDK de Azure Machine Learning o use una instancia de proceso de Azure Machine Learning que ya tenga instalado el SDK.
Cree y ejecute una canalización de aprendizaje automático. Una manera de cumplir este requisito es completar tutorial: Creación de una canalización de Azure Machine Learning para la puntuación por lotes. Para ver otras opciones, consulte Creación y ejecución de canalizaciones de aprendizaje automático con el SDK de Azure Machine Learning.
Publicación de una canalización
Después de tener una canalización en ejecución, puede publicarla para que se ejecute con entradas diferentes. Para que el punto de conexión REST de una canalización publicada acepte parámetros, debe configurar la canalización para que use PipelineParameter objetos para los argumentos que variarán.
Para crear un parámetro de canalización, use un objeto PipelineParameter con un valor predeterminado:
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Agregue el
PipelineParameterobjeto como parámetro a cualquiera de los pasos de la canalización, como se muestra aquí:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Publique esta canalización, que aceptará un parámetro cuando se invoque:
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")Después de publicar la canalización, puede comprobarla en la interfaz de usuario. El identificador de canalización es el identificador único de la canalización publicada.
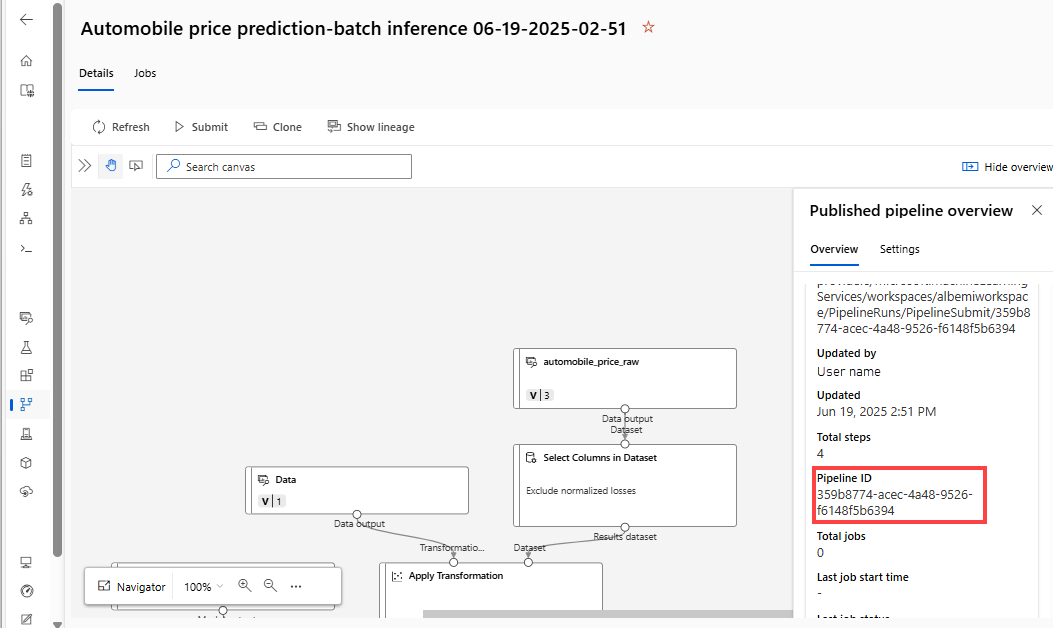

Ejecución de una canalización publicada
Todas las canalizaciones publicadas tienen un punto de conexión REST. Mediante el punto de conexión de canalización, puede desencadenar una ejecución de la canalización desde sistemas externos, incluidos los clientes que no son de Python. Este punto de conexión permite la repetibilidad administrada en escenarios de puntuación por lotes y reentrenamiento.
Importante
Si usa el control de acceso basado en rol (RBAC) de Azure para administrar el acceso a la canalización, establezca los permisos para el escenario de canalización (entrenamiento o puntuación).
Para invocar la ejecución de la canalización anterior, necesita un token de encabezado de autenticación de Microsoft Entra. El proceso para obtener un token se describe en la referencia de la clase AzureCliAuthentication y en el cuaderno Autenticación en Azure Machine Learning .
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
El json argumento de la solicitud POST debe contener, para la ParameterAssignments clave, un diccionario que contenga los parámetros de canalización y sus valores. Además, el json argumento puede contener las claves siguientes:
| Clave | Descripción |
|---|---|
ExperimentName |
Nombre del experimento asociado al punto de conexión. |
Description |
Texto de forma libre que describe el punto final. |
Tags |
Pares clave-valor libres que se pueden usar para etiquetar y anotar solicitudes. |
DataSetDefinitionValueAssignments |
Diccionario que se usa para cambiar conjuntos de datos sin volver a entrenar. (Consulte la discusión más adelante en este artículo). |
DataPathAssignments |
Diccionario que se usa para cambiar rutas de datos sin volver a entrenar. (Consulte la discusión más adelante en este artículo). |
Ejecución de una canalización publicada mediante C#
En el código siguiente se muestra cómo llamar a una canalización de forma asincrónica desde C#. El fragmento de código parcial solo muestra la estructura de llamadas. No muestra clases completas ni control de errores. No forma parte de un ejemplo de Microsoft.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// Submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Ejecuta una canalización publicada usando Java
El código siguiente muestra una llamada a una canalización que requiere autenticación. (Consulte Configuración de la autenticación para recursos y flujos de trabajo de Azure Machine Learning). Si la canalización se implementa públicamente, no necesita las llamadas que generan authKey. El fragmento de código parcial no muestra la clase Java ni la reutilizable control de excepciones. El código usa Optional.flatMap para encadenar funciones que podrían devolver un vacío Optional. El uso de flatMap acorta y aclara el código, pero tenga en cuenta que getRequestBody() traga excepciones.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token));
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc. (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Cambio de conjuntos de datos y rutas de datos sin necesidad de volver a entrenar
Es posible que quiera entrenar e inferencia en diferentes conjuntos de datos y rutas de datos. Por ejemplo, es posible que quiera entrenar en un conjunto de datos más pequeño, pero realizar la inferencia en el conjunto de datos completo. Puede cambiar los conjuntos de datos mediante la clave DataSetDefinitionValueAssignments en el argumento json de la solicitud. Puede cambiar rutas de acceso de datos mediante DataPathAssignments. La técnica es similar para ambas:
En el script de definición de canalización, cree un
PipelineParameterpara el conjunto de datos. Cree unDatasetConsumptionConfigoDataPatha partir dePipelineParameter:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)En el script de aprendizaje automático, acceda al conjunto de datos especificado dinámicamente mediante
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc. ...Observe que el script de aprendizaje automático tiene acceso al valor especificado para
DatasetConsumptionConfig(tabular_dataset) y no al valor dePipelineParameter(tabular_ds_param).En el script de definición de la canalización, establezca
DatasetConsumptionConfigcomo un parámetro paraPipelineScriptStep.train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Para cambiar los conjuntos de datos dinámicamente en la llamada REST de inferencia, use
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
Los cuadernos Showcasing Dataset y PipelineParameter y Showcasing DataPath y PipelineParameter contienen ejemplos completos de esta técnica.
Creación de un punto de conexión de canalización con versiones
Puede crear un punto de conexión de canalización que tenga varias canalizaciones publicadas detrás de ella. Esta técnica proporciona un punto de conexión REST fijo a medida que iteras y actualizas tus flujos de trabajo de aprendizaje automático.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Envío de un trabajo a un punto de conexión de canalización
Puede enviar un trabajo a la versión predeterminada de un punto de conexión de canalización:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
También puede enviar un trabajo a una versión específica:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
Puede lograr lo mismo mediante la API REST:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Uso de canalizaciones publicadas en Studio
También puede ejecutar una canalización publicada desde Studio:
Inicie sesión en Azure Machine Learning Studio.
En el menú de la izquierda, seleccione Puntos de conexión.
Seleccione Puntos de conexión de canalización:

Seleccione una canalización específica para ejecutar, consumir o revisar los resultados de las ejecuciones anteriores del punto de conexión de canalización.

Deshabilitación de una canalización publicada
Para ocultar una canalización de la lista de canalizaciones publicadas, debes deshabilitarla, ya sea en el estudio o mediante el SDK.
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
Puede volver a habilitarlo mediante p.enable(). Para obtener más información, consulte la referencia de la clase PublishedPipeline.
Pasos siguientes
- Usa estos cuadernos Jupyter en GitHub para profundizar en los flujos de aprendizaje automático.
- Consulte la referencia del SDK para el paquete azureml-pipelines-core y el paquete azureml-pipelines-steps .
- Para obtener sugerencias sobre la depuración y la solución de problemas de canalizaciones, consulte Depuración de canalizaciones .