Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se proporcionan soluciones a problemas comunes que pueden surgir al usar el EventProcessorClient tipo . Si busca soluciones a otros problemas comunes que podrían surgir al usar Azure Event Hubs, consulte Solución de problemas de Azure Event Hubs.
412 errores de condición previa cuando se usa un procesador de eventos
412 errores de condición previa se producen cuando el cliente intenta tomar o renovar la propiedad de una partición, pero la versión local del registro de propiedad está obsoleta. Este problema se produce cuando otra instancia del procesador roba la propiedad de la partición. Para obtener más información, vea la siguiente sección.
La propiedad de las particiones cambia con frecuencia
Cuando cambia el número de EventProcessorClient instancias (es decir, se agregan o quitan), las instancias en ejecución intentan equilibrar la carga de particiones entre sí mismas. Durante unos minutos después del cambio en el número de procesadores, se espera que las particiones cambien de propietario. Una vez equilibrada, la propiedad de las particiones debe ser estable y cambiar con poca frecuencia. Si la propiedad de la partición cambia con frecuencia cuando el número de procesadores es constante, es probable que indique un problema. Le recomendamos que registre una incidencia en GitHub con registros y una reproducción.
La propiedad de la partición se determina a través de los registros de propiedad de CheckpointStore. En cada intervalo de equilibrio de carga, EventProcessorClient realizará las siguientes tareas:
- Capture los registros de propiedad más recientes.
- Compruebe los registros para ver qué registros no han actualizado su marca de tiempo dentro del intervalo de expiración de propiedad de la partición. Solo se tienen en cuenta los registros que coinciden con estos criterios.
- Si hay particiones sin dueño y la carga no está equilibrada entre instancias de
EventProcessorClient, el cliente del procesador de eventos intentará apropiarse de una partición. - Actualice el registro de propiedad de las particiones que posee y que tienen un vínculo activo con esas particiones.
Puede configurar los intervalos de equilibrio de carga y de expiración de propiedad al crear el EventProcessorClient a través del EventProcessorClientBuilder, como se describe en la lista siguiente.
- El método loadBalancingUpdateInterval(Duration) indica con qué frecuencia se ejecuta el ciclo de equilibrio de carga.
- El método partitionOwnershipExpirationInterval(Duration) indica la cantidad mínima de tiempo desde que se ha actualizado el registro de propiedad, antes de que el procesador considere una partición sin propietario.
Por ejemplo, si un registro de propiedad se actualizó a las 9:30 a.m. y partitionOwnershipExpirationInterval es de 2 minutos. Cuando ocurre un ciclo de balanceo de carga y se detecta que el registro de propiedad no se ha actualizado en los últimos 2 minutos o antes de las 9:32 a. m., se considerará que la partición está sin propietario.
Si se produce un error en uno de los consumidores de partición, cerrará el consumidor correspondiente pero no intentará recuperarlo hasta el siguiente ciclo de equilibrado de carga.
"... el receptor actual "<RECEIVER_NAME>" con la época "0" se está desconectando"
El mensaje de error completo es similar al siguiente resultado:
New receiver 'nil' with higher epoch of '0' is created hence current receiver 'nil' with epoch '0'
is getting disconnected. If you are recreating the receiver, make sure a higher epoch is used.
TrackingId:<GUID>, SystemTracker:<NAMESPACE>:eventhub:<EVENT_HUB_NAME>|<CONSUMER_GROUP>,
Timestamp:2022-01-01T12:00:00}"}
Este error se espera cuando se produce el equilibrio de carga después EventProcessorClient de agregar o quitar instancias. El equilibrio de carga es un proceso en curso. Cuando se usa BlobCheckpointStore con el consumidor, cada 30 segundos ~ (de forma predeterminada), el consumidor comprueba para ver qué consumidores tienen una reclamación para cada partición, a continuación, ejecuta alguna lógica para determinar si es necesario "robar" una partición de otro consumidor. El mecanismo de servicio usado para afirmar la propiedad exclusiva sobre una partición se conoce como Época.
Sin embargo, si no se agregan o quitan instancias, hay un problema subyacente que se debe solucionar. Para obtener más información, consulte la sección Cambios de propiedad de particiones con frecuencia y Presentación de problemas de GitHub.
Uso elevado de CPU
El uso elevado de la CPU suele deberse a que una instancia posee demasiadas particiones. Se recomienda no más de tres particiones para cada núcleo de CPU. Es mejor empezar con 1,5 particiones para cada núcleo de CPU y, a continuación, probar aumentando el número de particiones propiedad.
Memoria insuficiente y elección del tamaño del montón
El problema de falta de memoria (OOM) puede producirse si el heap máximo actual de la JVM no es suficiente para ejecutar la aplicación. Es posible que quiera medir el requisito del montón de la aplicación. A continuación, en función del resultado, ajuste el tamaño del montón estableciendo la memoria máxima del montón adecuada mediante la opción JVM -Xmx.
No debe especificar -Xmx como un valor mayor que la memoria disponible o el límite establecido para el host (la máquina virtual o el contenedor), por ejemplo, la memoria solicitada en la configuración del contenedor. Debe asignar suficiente memoria para que el host soporte el heap de Java.
En los siguientes pasos se describe una manera típica de medir el valor del montón máximo de Java:
Ejecute la aplicación en un entorno cercano a producción, donde la aplicación envía, recibe y procesa eventos bajo la carga máxima esperada en producción.
Espere a que la aplicación alcance un estado estable. En esta fase, la aplicación y JVM habrían cargado todos los objetos de dominio, tipos de clase, instancias estáticas, grupos de objetos (TCP, grupos de conexiones de base de datos), etc.
En el estado estable, verá el patrón estable con forma de sierra para la colección del montón, como se muestra en el siguiente recorte de pantalla:
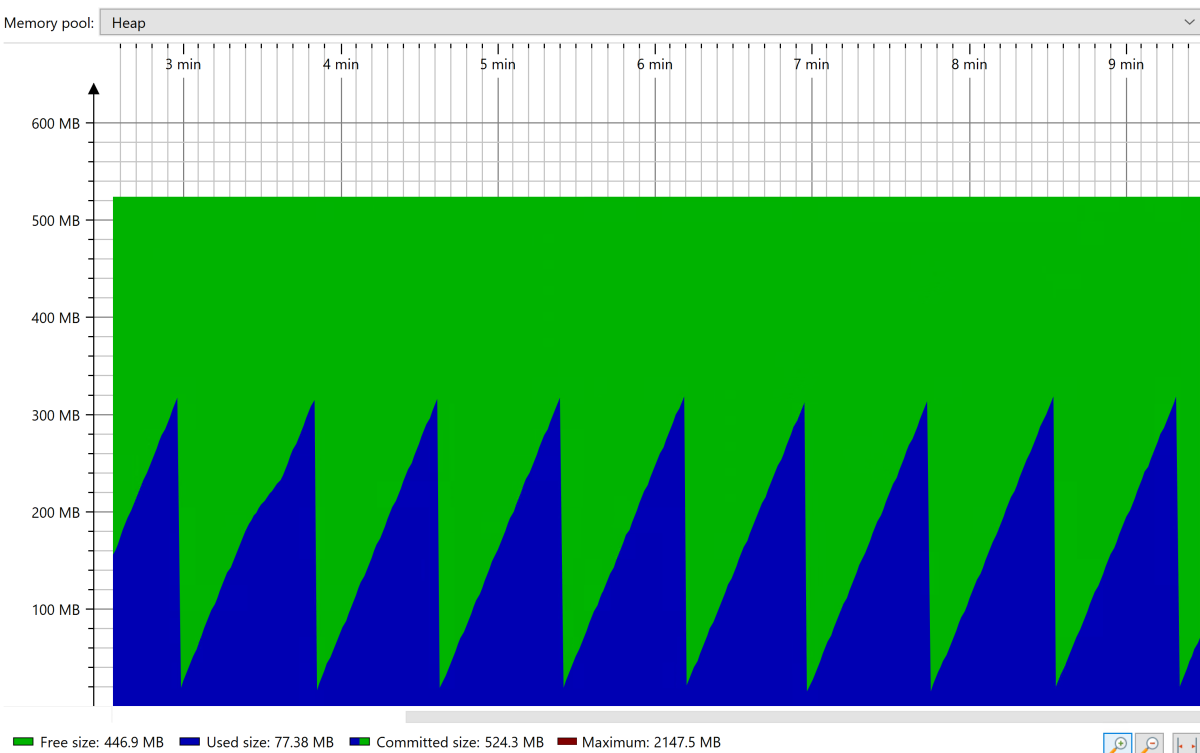
Una vez que la aplicación alcanza el estado estable, fuerza una recolección completa de elementos no utilizados (GC) mediante herramientas como JConsole. Observe la memoria ocupada tras la GC completa. Desea ajustar el tamaño del montón de modo que solo el 30 % esté ocupado después del GC completo. Puede usar este valor para establecer el tamaño máximo del montón (mediante
-Xmx).

Si está en el contenedor, entonces cambie el tamaño del contenedor para que tenga un extra de 1 GB ~ de memoria para la instancia de JVM que no sea del montón.
El cliente del procesador deja de recibir
El cliente del procesador suele funcionar continuamente en una aplicación host durante días. A veces, observa que EventProcessorClient no está procesando una o varias particiones. Normalmente, no hay suficiente información para determinar por qué se produjo la excepción. La detención de EventProcessorClient es el síntoma de una causa subyacente (es decir, la condición de carrera) que se produjo al intentar recuperarse de un error transitorio. Para obtener la información que necesitamos, consulte Presentación de problemas de GitHub.
EventData duplicado recibido cuando se reinicia el procesador
El servicio EventProcessorClient y Event Hubs garantizan una entrega al menos una vez. Puede agregar metadatos para distinguir eventos duplicados. Para más información, consulte ¿Azure Event Hubs garantiza una entrega al menos una vez? en Stack Overflow. Si necesita una única entrega, debería considerar Service Bus, que espera una confirmación del cliente. Para obtener una comparación de los servicios de mensajería, consulte Elección entre los servicios de mensajería de Azure.
El cliente de bajo nivel deja de recibir
EventHubConsumerAsyncClient es un cliente de consumidor de bajo nivel proporcionado por la biblioteca de Event Hubs, diseñado para usuarios avanzados que requieren un mayor control y flexibilidad sobre sus aplicaciones reactivas. Este cliente ofrece una interfaz de bajo nivel, lo que permite a los usuarios gestionar la contrapresión, los hilos y la recuperación dentro de la cadena Reactor. A diferencia de EventProcessorClient, EventHubConsumerAsyncClient no incluye mecanismos de recuperación automática para todas las causas terminales. Por lo tanto, los usuarios deben controlar los eventos terminales y seleccionar los operadores de reactor adecuados para implementar estrategias de recuperación.
El EventHubConsumerAsyncClient::receiveFromPartition método emite un error de terminal cuando la conexión encuentra un error que no se puede reintentar o cuando se produce un error consecutivo en una serie de intentos de recuperación de conexión, lo que agota el límite máximo de reintentos. Aunque el receptor de bajo nivel intenta recuperarse de errores transitorios, se espera que los usuarios del cliente de consumidor controle los eventos de terminal. Si se desea la recepción continua de eventos, la aplicación debe ajustar la cadena reactor para crear un nuevo cliente de consumidor en un evento de terminal.
Migración de la biblioteca cliente heredada a la nueva
La guía de migración incluye pasos para migrar desde el cliente heredado y migrar puntos de control heredados.
Pasos siguientes
Si la guía de resolución de problemas de este artículo no le ayuda a resolver los problemas al usar bibliotecas cliente de Azure SDK para Java, le recomendamos que deje la incidencia en el repositorio GitHub de Azure SDK para Java.