Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In last week's post, we covered the basics of conditional probabilities in language modeling. Let's now have another quick math lesson on joint probabilities.
A joint probability is useful when you're interested in the probability of an entire sequence of words. Here I can borrow an equation from Wikipedia:
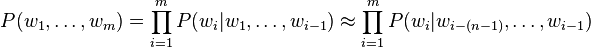
The middle term is the true value of observing the word sequence w1 through wm. The right term is the approximation when you only have an order-n dataset. Here's an example using our Python library:
>>> import MicrosoftNgram
>>> s = MicrosoftNgram.LookupService(model='urn:ngram:bing-body:jun09:2')
>>> s.GetJointProbability('apple pie')
-6.170992
>>> s.GetConditionalProbability('apple') + s.GetConditionalProbability('apple pie')
-6.170992
As expected, the joint probability is the same as the product of the conditional probability [remember — those numbers are log values, and log(a*b)=log(a)+log(b)].
But there's a hitch — what happens if a particular sequence of words had never been observed? Even in a corpus as large as the web, this is going to happen. Should the joint probability be 0? Depending on your application, the answer might be yes -- but for most scenarios, if the word sequence was at all probable, an approximation would be preferable. This is where smoothing comes in to play.
A number of different smoothing techniques are used today, but in essence we assess what we call a backoff penalty for word combinations for which we've no data. P(wm|wm-n,...,wm-1) is approximated as P(wm|wm-n+1,...,wm-1) * BO(wm-n,...,wm-1), i.e. we back off to a lower-order n-gram and assess a penalty which is a function of the context.