Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Our focus in the database world has primarily been on retrieving information from a structured source, through a structured query.
Relational DBs --> structured data, structured query
XML DBs --> semi-structured data, structured query
search --> unstructured data, unstructured query
Actually, search --> data with hidden structure, query with possibly hidden structure
Recent efforts on IR considers data with no explicit structure:
- Indexing and and retrieval of information-containing objects (text documents, web-pages, image, audio, ..)
- Want only relevant objects
- Efficiently from a large set
- Lets focus mainly on text based documents in this post
- Related areas
- DB Management
- Artificial intelligence
- Knowledge representation and intelligent action
- NLP and linguistics
- linguistic analysis of natural language text
- Machine learning
- Systems that improve performance with experience
Traditional Preprocessing steps
- Strip irrelevant markup, tags, punctuation
- Tokenize
- Stem tokens to root words
- Porter stemmer: set or local rules to reduce word to its root.
- Words with distinct meanings may reduce to the same token
- Does not recognize all morphological derivations
- (arm, army) --> arm, (police, policy) --> polic
- Remove stop words: I, a, the, is..
- Detect common phrases
- Build Inverted index: keywords --> docs
Basic Retrieval Models
- Set-theoretic
- Boolean model
- Extended Boolean
- Algebraic
- Vector Space
- Extended Boolean
- Generalized VS
- Latent semantic, neural network, etc.
- Probabilistic
- Inference/Belief Network
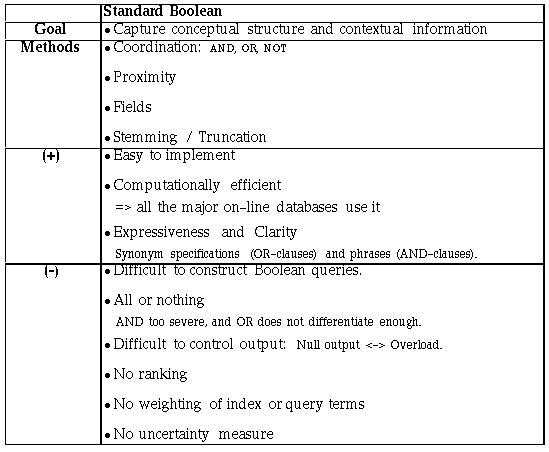
Boolean Model
Document Representation: Set of terms
Queries: Exact matches on presence of terms using logical operators AND, NOT, OR,..
No partial matches or ranking
Reasonably efficient implementations - think set operations in relational DBs queries
Rigid: hard to control: # of docs retrieved, rankings, relevance feedback
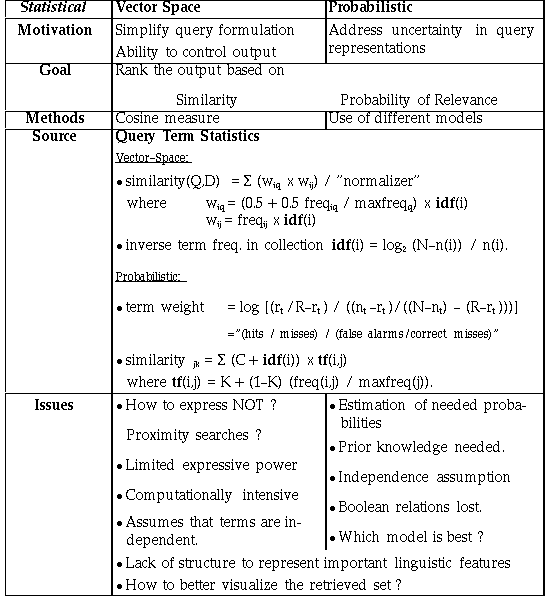
Vector Space Model
Document Representation: Bag of terms (with frequency)
Queries: Set of desired terms with optional weights
t distinct terms remain after preprocessing step, forming a vector space:
Dimension = t = |vocabulary|
Weight assigned to terms in the document, query (i, j): w_i,j
d_j = (w_1j, w_2j, …, w_tj)
Graphically..
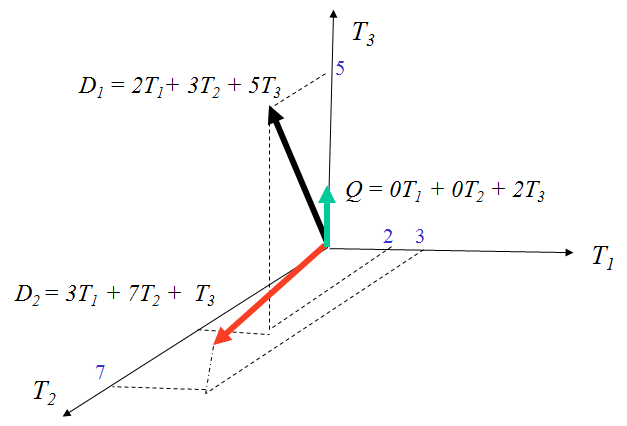
Term-document matrix:
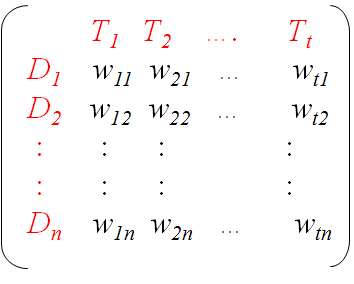
Each real-valued weight corresponds to the degree of significance of that term in the document. 0=no significance I, we, the, ..) or that it does not exist.
Term frequency (tf): tf_ij = frequency of i in j divided by frequency of most common term in j
Document frequency (df): number of documents containing term
Inverse document frequency of i: log_2 ( total # documents / df_i) Log dampens the effect relative to tf
tf-idf weighing commonly used to determine term weight: w_ij = tf_ij idf_i = tf_ij log2 (N/ df_i)
A term common across all documents is given less importance, and rare terms occurring in a document are given higher weight
Query is also treated as a document vector. Now the problem is to find similar documents
Need a way to compute degree of similarity between two vectors: Dot product!
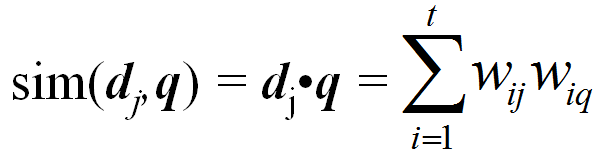
Problems: Favors long documents. Does not measure how many terms don't match.
Compute similarity based on Cosine of the angle between two vectors.
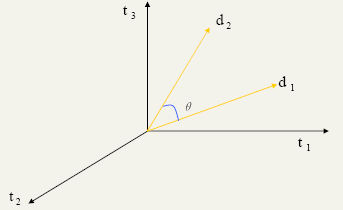
With V vocabulary and D documents, complexity is O( |V| * |D|) !!
Key points:
- Query viewed as a document
- Measure proximity to it (numerous methods with different optimizations have been proposed)
- Measures score/ranking, not just logical matches
Overall problems with Vector Space:
- Missing semantic, word-sense type information
- Missing Syntactic information - phrase structure, word order, proximity
- Does not support boolean queries as with the boolean model. Requiring presence of absence of terms
- Scoring Phrases of words difficult
- Wild-cards
Extended Boolean Model (p-Norm model)
Falls in the arena of Fuzzy set theory
Similar to boolean retrieval model, except adjust strictness of logical operators with a p-value.
p = infinity --> Boolean model
p = 1 --> Vector space
Spectrum of operator strictness in between..
A good list of comparisons: (https://www.scils.rutgers.edu/~aspoerri/InfoCrystal/Ch_2.html)
Upcoming posts on IR:
More on preprocessing, indexing, approximate matches, index compression
Optimizations for VS model
ML algorithms for IR: clustering and classification,EM, dimensionality reduction, probabilistic models, HMMs, BayesNet
Maybe get into NLP
Comments
- Anonymous
June 12, 2009
PingBack from http://greenteafatburner.info/story.php?id=4550