在智能体应用内,您可以上传文档、图片、视频或音频文件,并基于文件内容与大模型进行问答。文件仅在当前会话范围内生效,支持动态文件解析和视觉理解功能。
功能说明
根据文件类型不同,智能体提供以下核心功能:
文件类型 | 支持功能 |
文档 | 文本解析(提取文字内容并生成回答) |
图片 | 双模式支持:文本解析(提取文字内容) 视觉理解(分析图像内容,如物体、场景、动作等) |
视频 | 视频内容解析(提取文字或关键帧分析) |
音频 | 音频内容解析(识别语音内容) |
文本解析
适用场景
解析文档、图片、视频或音频中的文字内容,结合大模型回答问题。
如何使用
在智能体应用内选择任一模型;
打开动态文件解析开关;
单击输入框左上方的
 图标按钮,上传符合要求的文件;
图标按钮,上传符合要求的文件;在输入框中输入问题,系统将提取文件中的文字内容,大模型将基于这些内容生成回答。
操作示例
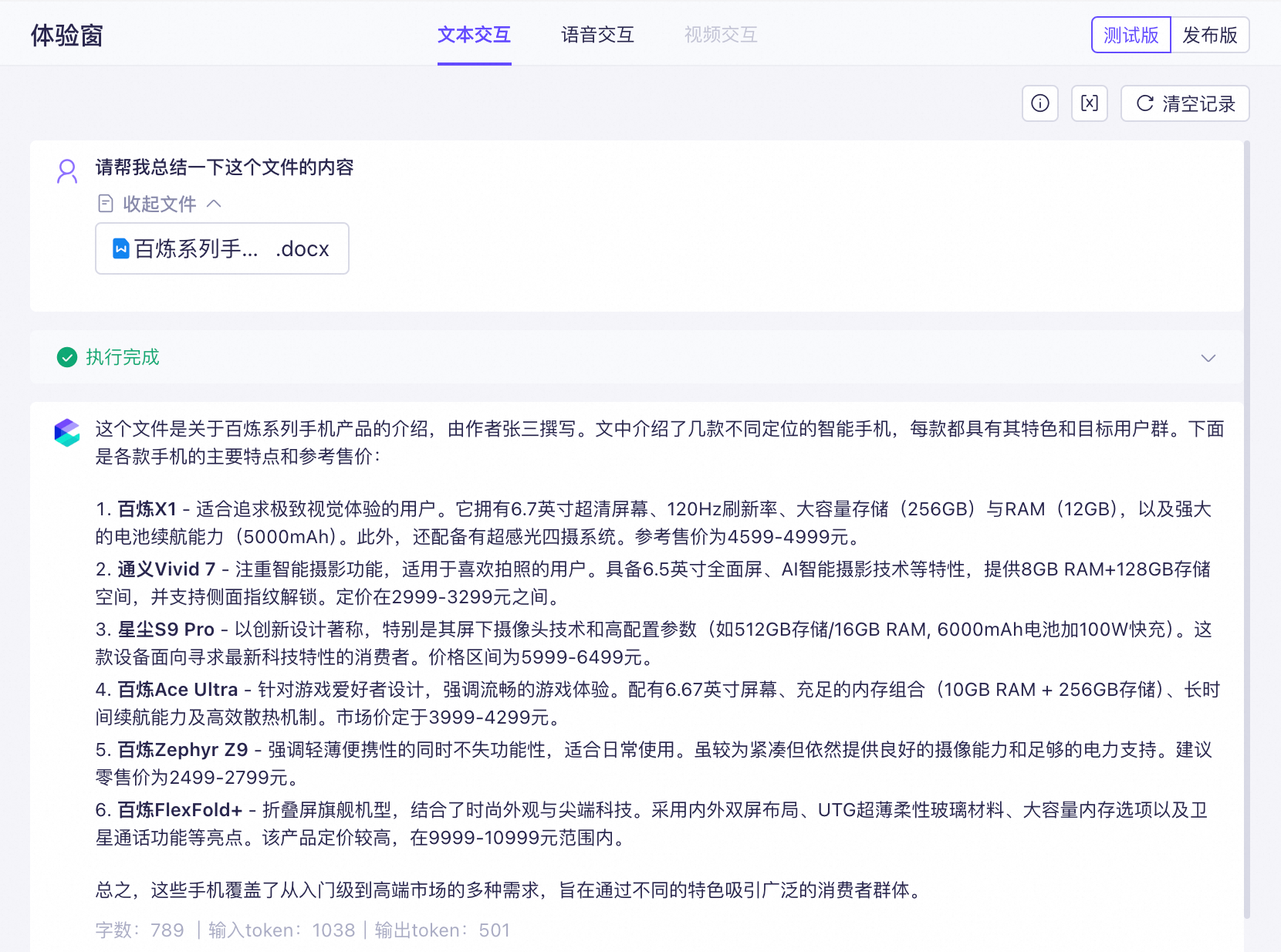
上传文档
上传示例文件百炼系列手机产品介绍.docx;
在输入框中输入:“请帮我总结一下这个文件的内容”,获取大模型的回复。
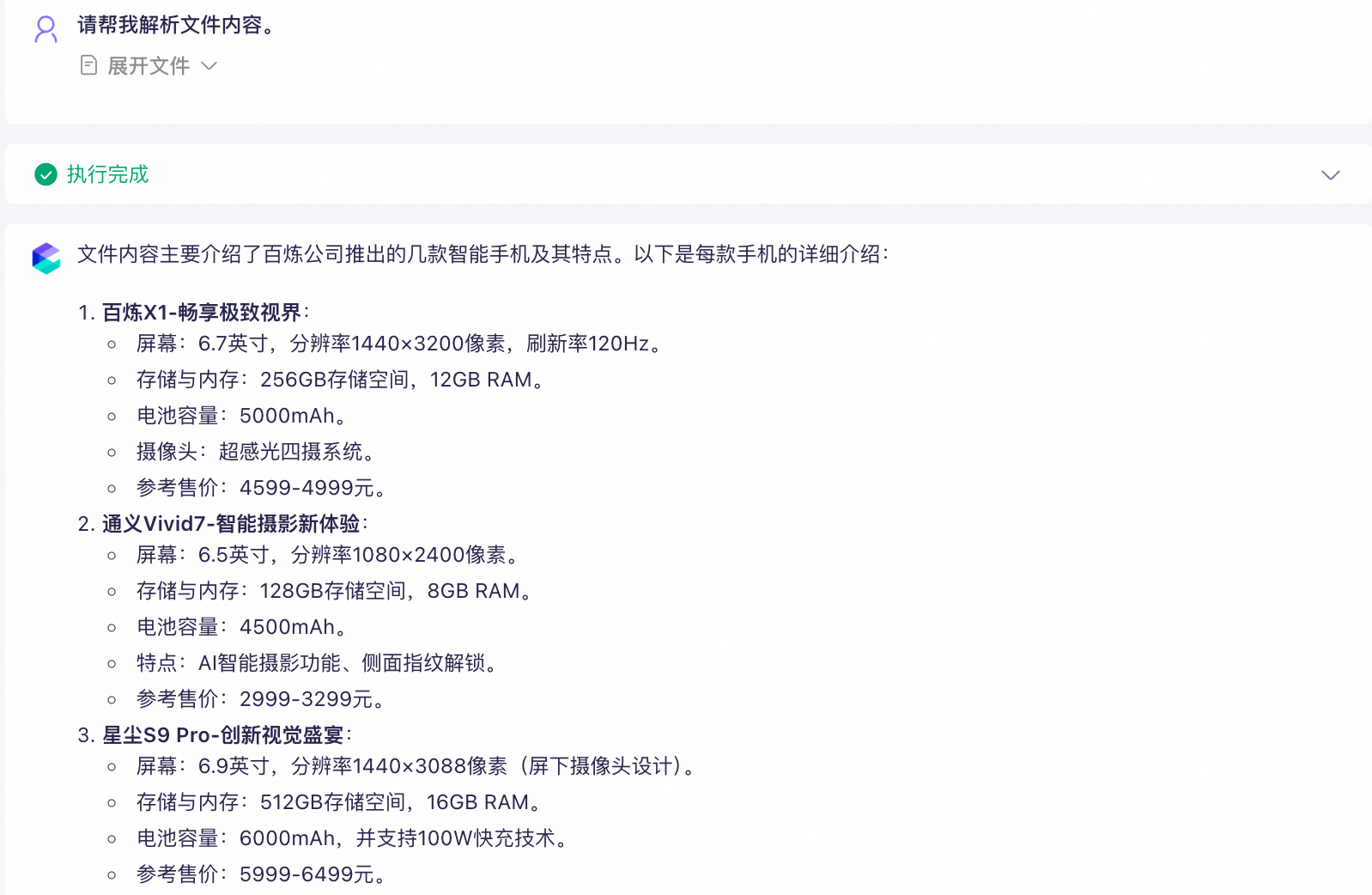
上传图片
上传示例文件test.png;
在输入框中输入:“请帮我解析文件内容。”,获取大模型的回复。
{kind=link}
上传视频
上传示例文件test.mp4;
在输入框中输入:“这个视频里面有什么?”,获取大模型的回复。

上传音频
上传示例文件test.wav;
在输入框中输入:“这个音频内容是什么?”,获取大模型的回复。

API调用
您可通过session_file_ids参数在当前请求中传递文件ID。
Java SDK中为sessionFileIds接口,通过HTTP调用时,请将 session_file_ids 放入 parameters 对象中。文件ID获取方法、应用调用示例请参考应用调用-上传文件。
视觉理解
适用场景
通过通义千问VL系列模型分析图片中的图像内容(如物体、场景、动作等),无需依赖文字信息。
如何使用
在智能体应用内选择通义千问VL系列模型;
开启视觉开关;
单击输入框左上方的
 图标按钮上传图片;
图标按钮上传图片;在输入框中输入问题,模型将直接分析图像内容并生成回答。

操作示例
上传示例图片文件animal_01.jpg;
在输入框中输入:“这个图片中有什么?”,获取大模型的回复。

{kind=link}
API调用
您可通过参数image_list在当前请求中传入多张图像URL。
Java SDK中为images接口。通过HTTP调用时,请将image_list放入input对象中。
应用调用步骤和示例请参考应用调用-上传文件。
相关文档
应用调用:应用可通过DashScope SDK或HTTP两种方式调用。
应用调用参数信息:调用接口的详细参数信息。
模型列表:模型的具体内容。