Model Setup¶
Model Setup can be accessed in either of the following ways:
- On the models overview page, click the "Create Model" button, or
- From an existing model card, click the "Config Model" button
"Models" in "Energy Optimizer" can use data both from Insights Hub time series and Integrated Data Lake (IDL). Data from time series is referred to as "Dynamic features", whereas data from IDL are "Batch features". The Model Building Wizard provides a guided workflow to the user to configure the model, select their Dynamic features Batch features. It also includes a step to remove anomalies from the training data. The wizard is split into the following steps:
- Model Information
- Dynamic Features
- Batch Features
- Select Training Data
- Review Training Data
- Configure Model
Model Information¶
In this section, configure the general details of the model such as the name, description and select the mandatory variables. A model requires the following four variables:
- Energy Consumer
- Energy Resource
- Batch variable
- Reference variable
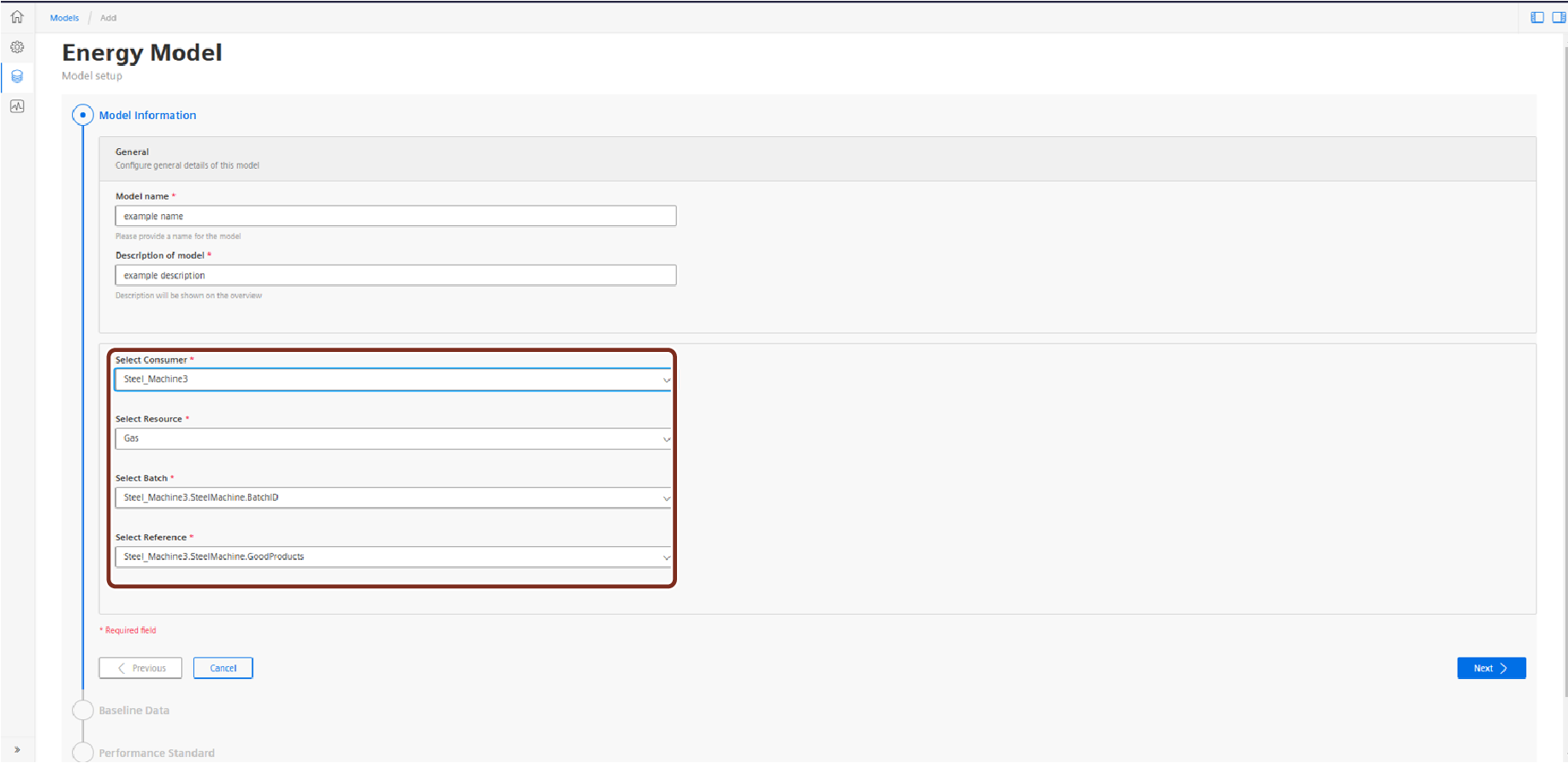
Most of these steps should be auto-filled based on the consumer configuration. After selecting a configured consumer from the first dropdown box, the variables for Batch and Reference will be pre-populated. Then, select the target Resource for the model. The Product variable is optional. For more information on configuring these variables for an energy consumer, see the Configuration.
Note
Only one model can be defined on any Consumer/Resource combination.
When all variables are selected, click "Next" to proceed.
Dynamic Features¶
Dynamic features come directly from time series. First, select an asset and aspect that includes the Dynamic features for the model. These can come from any asset configured on the tenant, but currently only a single aspect is supported.

When an aspect is selected, select the individual variables from the pop-up box. Below you will see the list of selected features. In general, Dynamic features could have a timestamp that differs from the batch or energy data, so they must be first aggregated before they can be used in a model to predict the energy resource. A different aggregation method can be used for each feature.
Select the aggregation method such as sum, max, mean from the drop-down list.

Batch Features¶
Batch features come from a CSV file on IDL. Each row of the file corresponds to process data for a single batch. By definition, they are already aggregated at the batch level. However, each row of the file must also contain a time identifier so that it can be joined with the correct energy resource and dynamic feature data. The time identifier should be written in ISO 8601 format. This time should correspond to the start time for the batch.
Use the data source window to locate the file with the batch data. From here, you can browse all your files on IDL. When you select a file, the file schema configuration is displayed below. Select the checkbox next to each feature to include it in the model. The application will infer the data type for each feature, but there is also the option to change the feature data type. One of the features must be set as the time identifier.
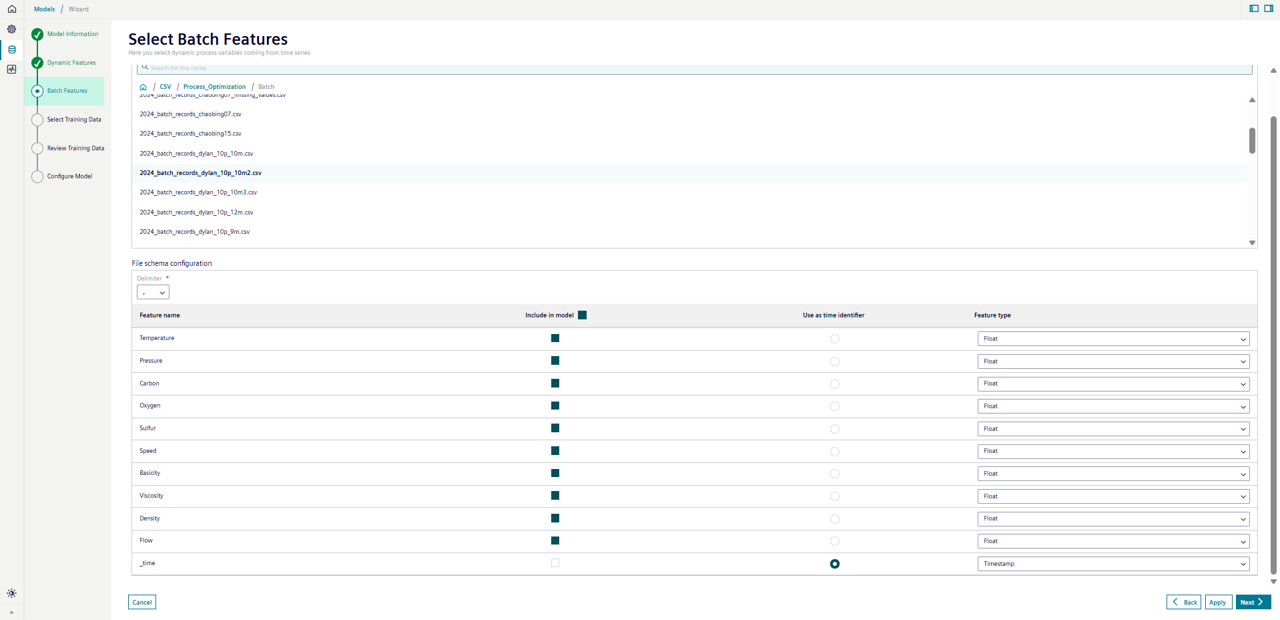
Once all Batch features are selected, click "Next".
Select Training Data¶
In this step, you can reduce the size of the training data by filtering on the date range. The filtered data will show in the time chart and scatterplot below.

The remove outliers plot can be used to interactively remove anomalies from the data set. After selecting a point on the chart, it will be highlighted in red and will be removed from the training data. Either single point or box-select can be used to flag anomalies. Click on the points again to remove the anomaly flag.
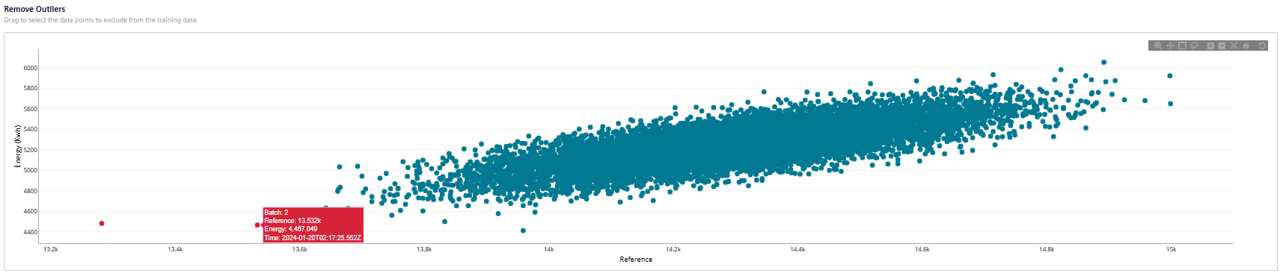
When all anomalies have been identified, move to the next step.
Review Training Data¶
On this page, the data from both Dynamic and Batch features are assembled into a single table for review. The total number of records and some summary statistics for each feature are displayed at the top.

You can also review the distribution of data by switching to the "Baseline Distributions" tab.

You can review the data here. Use the "Back" button to navigate back to any previous step. When returning to the "Review Training Data" page, the data set will be re-built. When everything is completed, select "Next".
Model Configuration¶
The final step is to specify whether the model should use the Energy variable or the Energy Per Reference as the target.
Click "Save" to return to the model card overview page and the model you have just created will be in the "Ready" state with "Dataset loaded". Click "Train" from the card menu and the model moves to "Training in progress". The app refreshes every 10 seconds to check whether training is complete.