SAM 2.1
Acabamos de adicionar suporte para o modelo SAM2.1 mais preciso. Por favor, experimente!
SAM 2: Segment Anything Model 2
![]()
O SAM 2, o sucessor do Segment Anything Model (SAM) da Meta, é uma ferramenta de ponta projetada para segmentação abrangente de objetos em imagens e vídeos. Ele se destaca no tratamento de dados visuais complexos por meio de uma arquitetura de modelo unificada e promptable que oferece suporte ao processamento em tempo real e à generalização zero-shot.

Principais Características
Assista: Como Executar a Inferência com o SAM2 da Meta usando Ultralytics | Guia Passo a Passo 🎉
Arquitetura de Modelo Unificada
O SAM 2 combina os recursos de segmentação de imagem e vídeo em um único modelo. Essa unificação simplifica a implantação e permite um desempenho consistente em diferentes tipos de mídia. Ele aproveita uma interface flexível baseada em prompts, permitindo que os usuários especifiquem objetos de interesse por meio de vários tipos de prompts, como pontos, caixas delimitadoras ou máscaras.
Desempenho em Tempo Real
O modelo atinge velocidades de inferência em tempo real, processando aproximadamente 44 quadros por segundo. Isso torna o SAM 2 adequado para aplicações que exigem feedback imediato, como edição de vídeo e realidade aumentada.
Generalização Zero-Shot
O SAM 2 pode segmentar objetos que nunca encontrou antes, demonstrando uma forte generalização zero-shot. Isso é particularmente útil em domínios visuais diversos ou em evolução, onde as categorias pré-definidas podem não cobrir todos os objetos possíveis.
Refinamento Interativo
Os usuários podem refinar iterativamente os resultados da segmentação, fornecendo prompts adicionais, permitindo um controle preciso sobre a saída. Essa interatividade é essencial para ajustar os resultados em aplicações como anotação de vídeo ou imagem médica.
Manuseio Avançado de Desafios Visuais
O SAM 2 inclui mecanismos para gerenciar desafios comuns de segmentação de vídeo, como oclusão e reaparecimento de objetos. Ele usa um mecanismo de memória sofisticado para rastrear objetos em todos os frames, garantindo a continuidade, mesmo quando os objetos são temporariamente obscurecidos ou saem e reentram na cena.
Para uma compreensão mais profunda da arquitetura e capacidades do SAM 2, explore o artigo de pesquisa do SAM 2.
Desempenho e Detalhes Técnicos
O SAM 2 estabelece um novo benchmark no campo, superando os modelos anteriores em várias métricas:
| Métrica | SAM 2 | SOTA Anterior |
|---|---|---|
| Segmentação de Vídeo Interativa | Melhor | - |
| Interações Humanas Necessárias | 3x menos | Linha de Base |
| Precisão da Segmentação de Imagem | Melhorado | SAM |
| Velocidade de Inferência | 6x mais rápido | SAM |
Arquitetura do Modelo
Componentes Essenciais
- Codificador de Imagem e Vídeo: Utiliza uma arquitetura baseada em transformer para extrair recursos de alto nível de imagens e quadros de vídeo. Este componente é responsável por entender o conteúdo visual em cada etapa.
- Prompt Encoder: Processa prompts fornecidos pelo usuário (pontos, caixas, máscaras) para orientar a tarefa de segmentação. Isso permite que o SAM 2 se adapte à entrada do usuário e tenha como alvo objetos específicos dentro de uma cena.
- Mecanismo de Memória: Inclui um codificador de memória, um banco de memória e um módulo de atenção de memória. Esses componentes armazenam e utilizam coletivamente informações de frames passados, permitindo que o modelo mantenha um rastreamento de objetos consistente ao longo do tempo.
- Decodificador de Máscara: Gera as máscaras de segmentação finais com base nos recursos de imagem codificados e prompts. Em vídeo, também usa o contexto de memória para garantir um rastreamento preciso entre os frames.
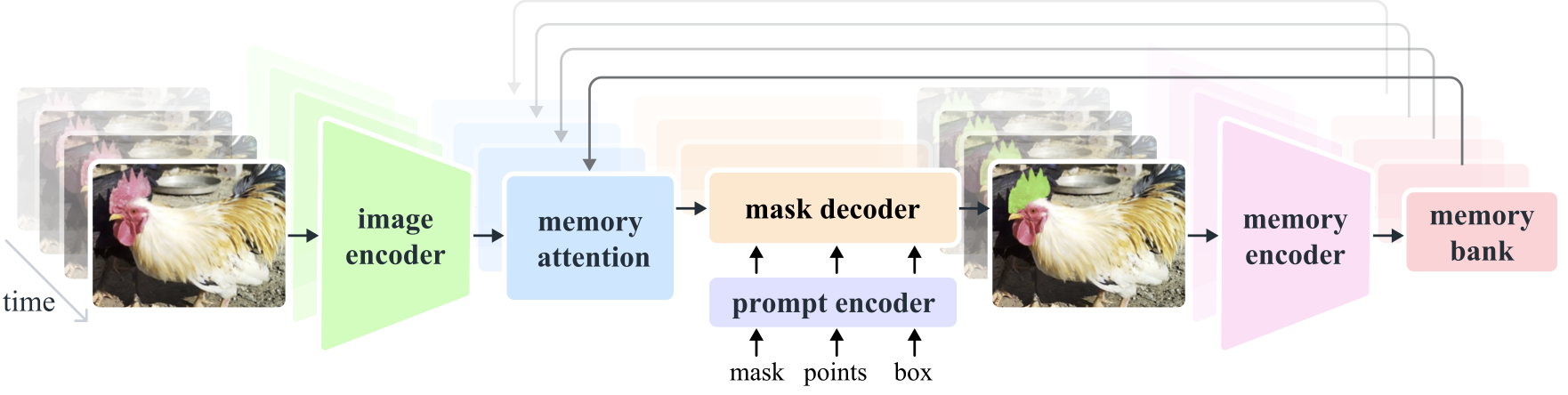
Mecanismo de Memória e Tratamento de Oclusão
O mecanismo de memória permite que o SAM 2 lide com dependências temporais e oclusões em dados de vídeo. À medida que os objetos se movem e interagem, o SAM 2 registra suas características em um banco de memória. Quando um objeto se torna ocluso, o modelo pode confiar nessa memória para prever sua posição e aparência quando ele reaparecer. O cabeçalho de oclusão lida especificamente com cenários onde os objetos não estão visíveis, prevendo a probabilidade de um objeto estar ocluso.
Resolução de Ambiguidade Multi-Máscara
Em situações com ambiguidade (por exemplo, objetos sobrepostos), o SAM 2 pode gerar múltiplas previsões de máscara. Este recurso é crucial para representar com precisão cenas complexas onde uma única máscara pode não descrever suficientemente as nuances da cena.
Dataset SA-V
O conjunto de dados SA-V, desenvolvido para o treinamento do SAM 2, é um dos maiores e mais diversos conjuntos de dados de segmentação de vídeo disponíveis. Inclui:
- Mais de 51.000 vídeos: Capturados em 47 países, proporcionando uma ampla gama de cenários do mundo real.
- Mais de 600.000 Anotações de Máscara: Anotações detalhadas de máscara espaço-temporal, referidas como "masklets", cobrindo objetos inteiros e partes.
- Escala do Conjunto de Dados: Apresenta 4,5 vezes mais vídeos e 53 vezes mais anotações do que os maiores conjuntos de dados anteriores, oferecendo diversidade e complexidade sem precedentes.
Benchmarks
Segmentação de Objetos em Vídeo
O SAM 2 demonstrou um desempenho superior nos principais benchmarks de segmentação de vídeo:
| Conjunto de dados | J&F | J | F |
|---|---|---|---|
| DAVIS 2017 | 82.5 | 79.8 | 85.2 |
| YouTube-VOS | 81.2 | 78.9 | 83.5 |
Segmentação Interativa
Em tarefas de segmentação interativa, o SAM 2 mostra eficiência e precisão significativas:
| Conjunto de dados | NoC@90 | AUC |
|---|---|---|
| DAVIS Interativo | 1.54 | 0.872 |
Instalação
Para instalar o SAM 2, use o seguinte comando. Todos os modelos SAM 2 serão baixados automaticamente na primeira utilização.
pip install ultralytics
Como Usar o SAM2: Versatilidade em Segmentação de Imagens e Vídeos
A tabela a seguir detalha os modelos SAM 2 disponíveis, seus pesos pré-treinados, tarefas suportadas e compatibilidade com diferentes modos de operação, como Inferência, Validação, Treinamento e Exportação.
| Tipo de Modelo | Pesos Pré-treinados | Tarefas Suportadas | Inferência | Validação | Treinamento | Exportar |
|---|---|---|---|---|---|---|
| SAM 2 mínimo | sam2_t.pt | Segmentação de Instância | ✅ | ❌ | ❌ | ❌ |
| SAM 2 pequeno | sam2_s.pt | Segmentação de Instância | ✅ | ❌ | ❌ | ❌ |
| SAM 2 base | sam2_b.pt | Segmentação de Instância | ✅ | ❌ | ❌ | ❌ |
| SAM 2 grande | sam2_l.pt | Segmentação de Instância | ✅ | ❌ | ❌ | ❌ |
| SAM 2.1 mínimo | sam2.1_t.pt | Segmentação de Instância | ✅ | ❌ | ❌ | ❌ |
| SAM 2.1 pequeno | sam2.1_s.pt | Segmentação de Instância | ✅ | ❌ | ❌ | ❌ |
| SAM 2.1 base | sam2.1_b.pt | Segmentação de Instância | ✅ | ❌ | ❌ | ❌ |
| SAM 2.1 grande | sam2.1_l.pt | Segmentação de Instância | ✅ | ❌ | ❌ | ❌ |
Exemplos de Previsão do SAM 2
O SAM 2 pode ser utilizado em um amplo espectro de tarefas, incluindo edição de vídeo em tempo real, imagens médicas e sistemas autônomos. Sua capacidade de segmentar dados visuais estáticos e dinâmicos o torna uma ferramenta versátil para pesquisadores e desenvolvedores.
Segmentar com Prompts
Segmentar com Prompts
Use prompts para segmentar objetos específicos em imagens ou vídeos.
from ultralytics import SAM
# Load a model
model = SAM("sam2.1_b.pt")
# Display model information (optional)
model.info()
# Run inference with bboxes prompt
results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200])
# Run inference with single point
results = model(points=[900, 370], labels=[1])
# Run inference with multiple points
results = model(points=[[400, 370], [900, 370]], labels=[1, 1])
# Run inference with multiple points prompt per object
results = model(points=[[[400, 370], [900, 370]]], labels=[[1, 1]])
# Run inference with negative points prompt
results = model(points=[[[400, 370], [900, 370]]], labels=[[1, 0]])
Segmentar Tudo
Segmentar Tudo
Segmentar toda a imagem ou conteúdo de vídeo sem prompts específicos.
from ultralytics import SAM
# Load a model
model = SAM("sam2.1_b.pt")
# Display model information (optional)
model.info()
# Run inference
model("path/to/video.mp4")
# Run inference with a SAM 2 model
yolo predict model=sam2.1_b.pt source=path/to/video.mp4
Segmentar Vídeo e Rastrear objetos
Segmentar Vídeo
Segmentar todo o conteúdo de vídeo com prompts específicos e rastrear objetos.
from ultralytics.models.sam import SAM2VideoPredictor
# Create SAM2VideoPredictor
overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=1024, model="sam2_b.pt")
predictor = SAM2VideoPredictor(overrides=overrides)
# Run inference with single point
results = predictor(source="test.mp4", points=[920, 470], labels=[1])
# Run inference with multiple points
results = predictor(source="test.mp4", points=[[920, 470], [909, 138]], labels=[1, 1])
# Run inference with multiple points prompt per object
results = predictor(source="test.mp4", points=[[[920, 470], [909, 138]]], labels=[[1, 1]])
# Run inference with negative points prompt
results = predictor(source="test.mp4", points=[[[920, 470], [909, 138]]], labels=[[1, 0]])
- Este exemplo demonstra como o SAM 2 pode ser usado para segmentar todo o conteúdo de uma imagem ou vídeo se nenhum prompt (bboxes/pontos/máscaras) for fornecido.
Comparação de SAM 2 vs YOLO
Aqui comparamos os modelos SAM 2 da Meta, incluindo a menor variante SAM2-t, com o menor modelo de segmentação da Ultralytics, YOLO11n-seg:
| Modelo | Tamanho (MB) |
Parâmetros (M) |
Velocidade (CPU) (ms/im) |
|---|---|---|---|
| Meta SAM-b | 375 | 93.7 | 49401 |
| Meta SAM2-b | 162 | 80.8 | 31901 |
| Meta SAM2-t | 78.1 | 38.9 | 25997 |
| MobileSAM | 40.7 | 10.1 | 25381 |
| FastSAM-s com backbone YOLOv8 | 23.7 | 11.8 | 55.9 |
| YOLOv8n-seg da Ultralytics | 6,7 (11,7x menor) | 3,4 (11,4x menos) | 24.5 (1061x mais rápido) |
| Ultralytics YOLO11n-seg | 5.9 (13,2x menor) | 2.9 (13,4x menos) | 30.1 (864x mais rápido) |
Esta comparação demonstra as diferenças substanciais nos tamanhos e velocidades dos modelos entre as variantes SAM e os modelos de segmentação YOLO. Embora o SAM forneça recursos exclusivos de segmentação automática, os modelos YOLO, particularmente YOLOv8n-seg e YOLO11n-seg, são significativamente menores, mais rápidos e computacionalmente mais eficientes.
Testes executados em um Apple M4 Pro 2025 com 24 GB de RAM usando torch==2.6.0 e ultralytics==8.3.90. Para reproduzir este teste:
Exemplo
from ultralytics import ASSETS, SAM, YOLO, FastSAM
# Profile SAM2-t, SAM2-b, SAM-b, MobileSAM
for file in ["sam_b.pt", "sam2_b.pt", "sam2_t.pt", "mobile_sam.pt"]:
model = SAM(file)
model.info()
model(ASSETS)
# Profile FastSAM-s
model = FastSAM("FastSAM-s.pt")
model.info()
model(ASSETS)
# Profile YOLO models
for file_name in ["yolov8n-seg.pt", "yolo11n-seg.pt"]:
model = YOLO(file_name)
model.info()
model(ASSETS)
Auto-Anotação: Criação Eficiente de Conjuntos de Dados
A auto-anotação é um recurso poderoso do SAM 2, permitindo que os usuários gerem conjuntos de dados de segmentação de forma rápida e precisa, aproveitando modelos pré-treinados. Essa capacidade é particularmente útil para criar conjuntos de dados grandes e de alta qualidade sem um esforço manual extenso.
Como Auto-Anotar com SAM 2
Assista: Anotação Automática com o Modelo Segment Anything 2 da Meta usando Ultralytics | Rotulagem de Dados
Para auto-anotar seu conjunto de dados usando SAM 2, siga este exemplo:
Exemplo de Auto-Anotação
from ultralytics.data.annotator import auto_annotate
auto_annotate(data="path/to/images", det_model="yolo11x.pt", sam_model="sam2_b.pt")
| Argumento | Tipo | Padrão | Descrição |
|---|---|---|---|
data |
str |
obrigatório | Caminho para o diretório contendo as imagens alvo para anotação ou segmentação. |
det_model |
str |
'yolo11x.pt' |
Caminho do modelo de detecção de objetos YOLO para detecção de objetos inicial. |
sam_model |
str |
'sam_b.pt' |
Caminho do modelo SAM para segmentação (suporta variantes SAM, SAM2 e modelos mobile_sam). |
device |
str |
'' |
Dispositivo de computação (por exemplo, 'cuda:0', 'cpu' ou '' para detecção automática de dispositivo). |
conf |
float |
0.25 |
Limite de confiança da detecção YOLO para filtrar detecções fracas. |
iou |
float |
0.45 |
Limite de IoU para Supressão Não Máxima para filtrar caixas sobrepostas. |
imgsz |
int |
640 |
Tamanho de entrada para redimensionar imagens (deve ser múltiplo de 32). |
max_det |
int |
300 |
Número máximo de detecções por imagem para eficiência de memória. |
classes |
list[int] |
None |
Lista de índices de classe para detectar (por exemplo, [0, 1] para pessoa e bicicleta). |
output_dir |
str |
None |
Diretório para salvar as anotações (o padrão é './labels' relativo ao caminho dos dados). |
Esta função facilita a criação rápida de conjuntos de dados de segmentação de alta qualidade, ideal para pesquisadores e desenvolvedores que desejam acelerar seus projetos.
Limitações
Apesar dos seus pontos fortes, o SAM 2 tem certas limitações:
- Estabilidade do Rastreamento: O SAM 2 pode perder o rastreamento de objetos durante sequências prolongadas ou mudanças significativas de ponto de vista.
- Confusão de Objetos: O modelo pode, por vezes, confundir objetos de aparência semelhante, particularmente em cenas lotadas.
- Eficiência com Múltiplos Objetos: A eficiência da segmentação diminui ao processar vários objetos simultaneamente devido à falta de comunicação entre os objetos.
- Precisão Detalhada: Pode perder detalhes finos, especialmente com objetos em movimento rápido. Prompts adicionais podem resolver parcialmente este problema, mas a suavidade temporal não é garantida.
Citações e Agradecimentos
Se o SAM 2 for uma parte crucial do seu trabalho de pesquisa ou desenvolvimento, por favor, cite-o usando a seguinte referência:
@article{ravi2024sam2,
title={SAM 2: Segment Anything in Images and Videos},
author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph},
journal={arXiv preprint},
year={2024}
}
Estendemos nossa gratidão à Meta AI por suas contribuições para a comunidade de IA com este modelo e conjunto de dados inovadores.
FAQ
O que é o SAM 2 e como ele melhora o Segment Anything Model (SAM) original?
O SAM 2, o sucessor do Segment Anything Model (SAM) da Meta, é uma ferramenta de ponta projetada para segmentação abrangente de objetos em imagens e vídeos. Ele se destaca no tratamento de dados visuais complexos por meio de uma arquitetura de modelo unificada e promptable que oferece suporte ao processamento em tempo real e à generalização zero-shot. O SAM 2 oferece diversas melhorias em relação ao SAM original, incluindo:
- Arquitetura de Modelo Unificada: Combina capacidades de segmentação de imagem e vídeo em um único modelo.
- Desempenho em Tempo Real: Processa aproximadamente 44 frames por segundo, tornando-o adequado para aplicações que exigem feedback imediato.
- Generalização Zero-Shot: Segmenta objetos que nunca encontrou antes, útil em diversos domínios visuais.
- Refinamento Interativo: Permite que os usuários refinem iterativamente os resultados da segmentação, fornecendo prompts adicionais.
- Manuseio Avançado de Desafios Visuais: Gerencia desafios comuns de segmentação de vídeo, como oclusão e reaparecimento de objetos.
Para mais detalhes sobre a arquitetura e os recursos do SAM 2, explore o artigo de pesquisa do SAM 2.
Como posso usar o SAM 2 para segmentação de vídeo em tempo real?
O SAM 2 pode ser utilizado para segmentação de vídeo em tempo real, aproveitando sua interface programável e recursos de inferência em tempo real. Aqui está um exemplo básico:
Segmentar com Prompts
Use prompts para segmentar objetos específicos em imagens ou vídeos.
from ultralytics import SAM
# Load a model
model = SAM("sam2_b.pt")
# Display model information (optional)
model.info()
# Segment with bounding box prompt
results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200])
# Segment with point prompt
results = model("path/to/image.jpg", points=[150, 150], labels=[1])
Para uma utilização mais abrangente, consulte a seção Como usar o SAM 2.
Quais datasets são usados para treinar o SAM 2 e como eles melhoram seu desempenho?
O SAM 2 é treinado no conjunto de dados SA-V, um dos maiores e mais diversos conjuntos de dados de segmentação de vídeo disponíveis. O conjunto de dados SA-V inclui:
- Mais de 51.000 vídeos: Capturados em 47 países, proporcionando uma ampla gama de cenários do mundo real.
- Mais de 600.000 Anotações de Máscara: Anotações detalhadas de máscara espaço-temporal, referidas como "masklets", cobrindo objetos inteiros e partes.
- Escala do Conjunto de Dados: Apresenta 4,5 vezes mais vídeos e 53 vezes mais anotações do que os maiores conjuntos de dados anteriores, oferecendo diversidade e complexidade sem precedentes.
Este extenso conjunto de dados permite que o SAM 2 alcance um desempenho superior nos principais benchmarks de segmentação de vídeo e aprimore suas capacidades de generalização zero-shot. Para mais informações, consulte a seção Conjunto de Dados SA-V.
Como o SAM 2 lida com oclusões e reaparecimentos de objetos na segmentação de vídeo?
O SAM 2 inclui um mecanismo de memória sofisticado para gerenciar dependências temporais e oclusões em dados de vídeo. O mecanismo de memória consiste em:
- Codificador de Memória e Banco de Memória: Armazena características de frames passadas.
- Módulo de Atenção de Memória: Utiliza informações armazenadas para manter um rastreamento de objetos consistente ao longo do tempo.
- Cabeçalho de Oclusão: Lida especificamente com cenários em que os objetos não estão visíveis, prevendo a probabilidade de um objeto estar ocluído.
Este mecanismo garante a continuidade mesmo quando os objetos são temporariamente obscurecidos ou saem e voltam a entrar na cena. Para mais detalhes, consulte a seção Mecanismo de Memória e Tratamento de Oclusão.
Como o SAM 2 se compara a outros modelos de segmentação, como o YOLO11?
Os modelos SAM 2, como o SAM2-t e o SAM2-b da Meta, oferecem poderosos recursos de segmentação zero-shot, mas são significativamente maiores e mais lentos em comparação com os modelos YOLO11. Por exemplo, o YOLO11n-seg é aproximadamente 13 vezes menor e mais de 860 vezes mais rápido que o SAM2-b. Enquanto o SAM 2 se destaca em cenários de segmentação versátil, baseada em prompt e zero-shot, o YOLO11 é otimizado para velocidade, eficiência e aplicações em tempo real, tornando-o mais adequado para implantação em ambientes com recursos limitados.





